【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
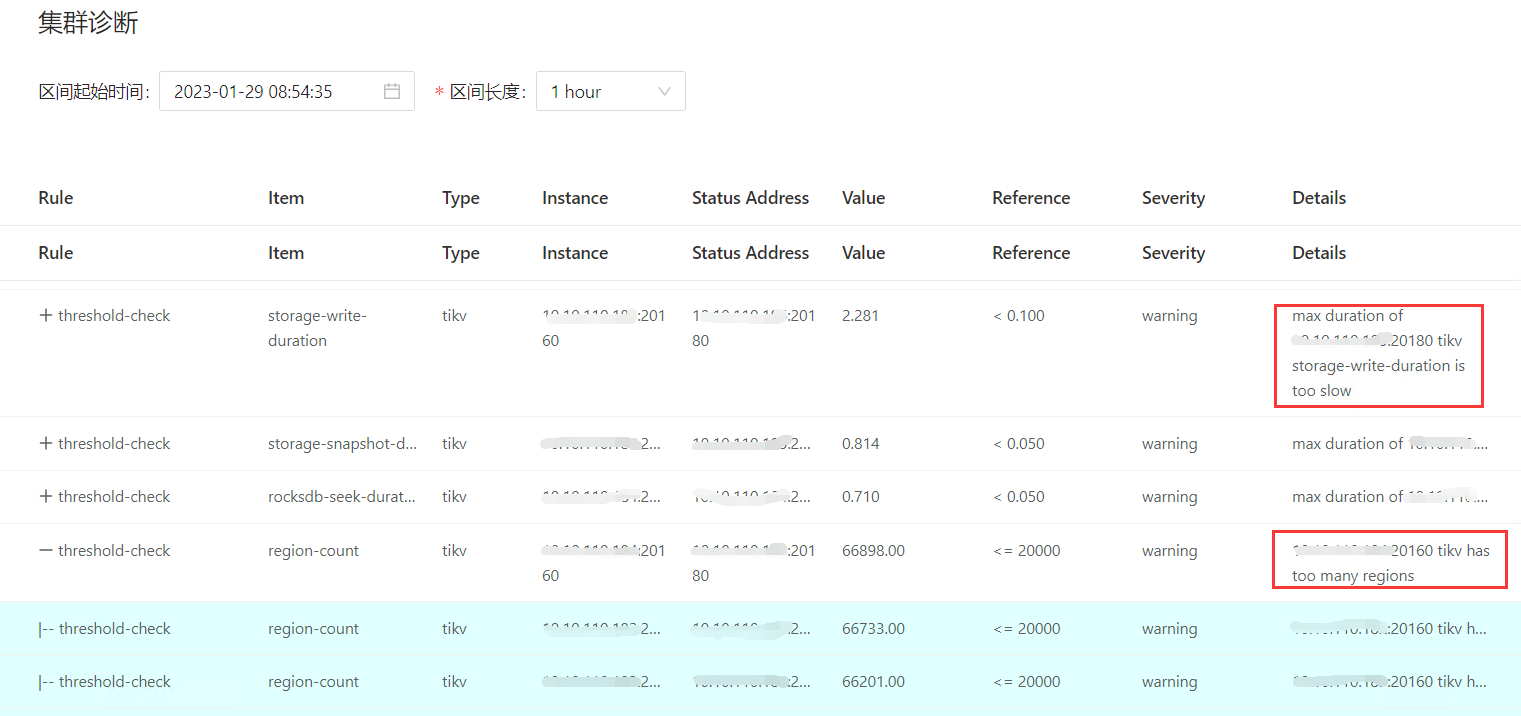
您提供的截图只是报告中说某个tikv节点的写延迟比较高,还有一个是某个节点的region数量过多,这两个是同一个节点吗?慢的原因又很多,没有足够的信息,大家也只能乱猜。
所以,能多提供些信息吗?比如相关监控,日志,相关sql等
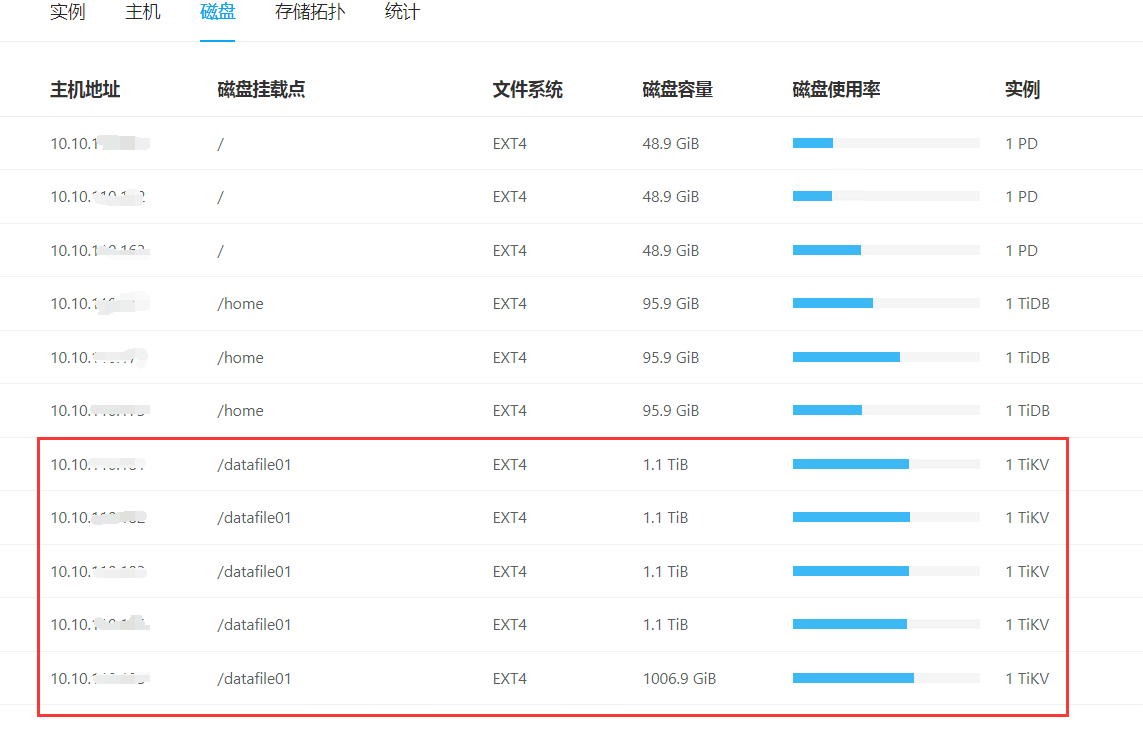
tikv 一共5个节点,都是同样的。
时间有规律性么
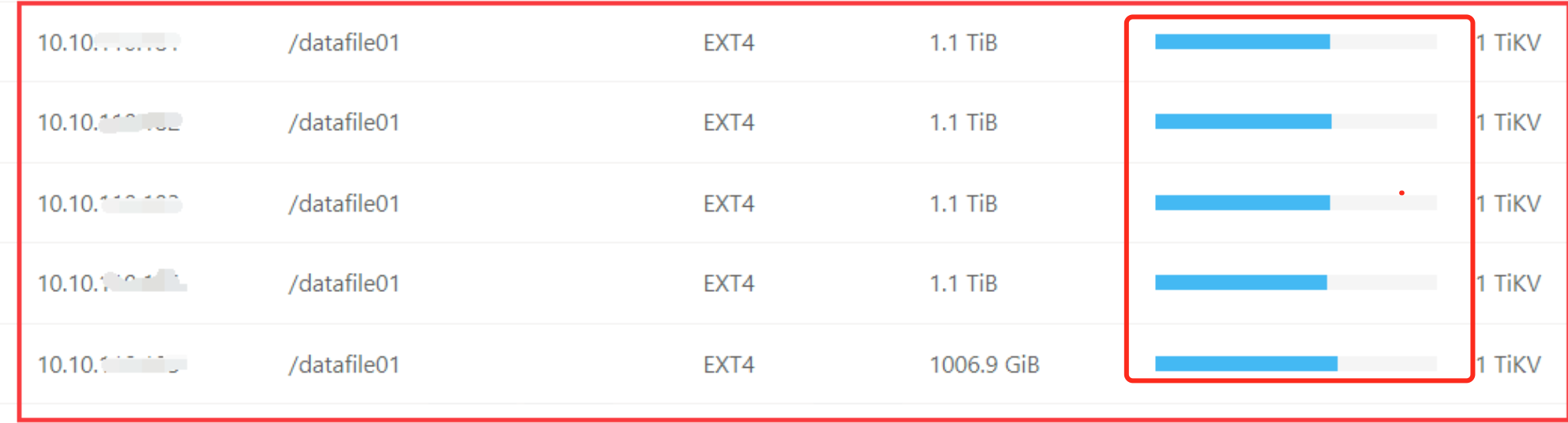
如果所有的tikv节点都有这两个告警,那每个节点的磁盘使用率如何?空region多不多?磁盘是ssd吗?
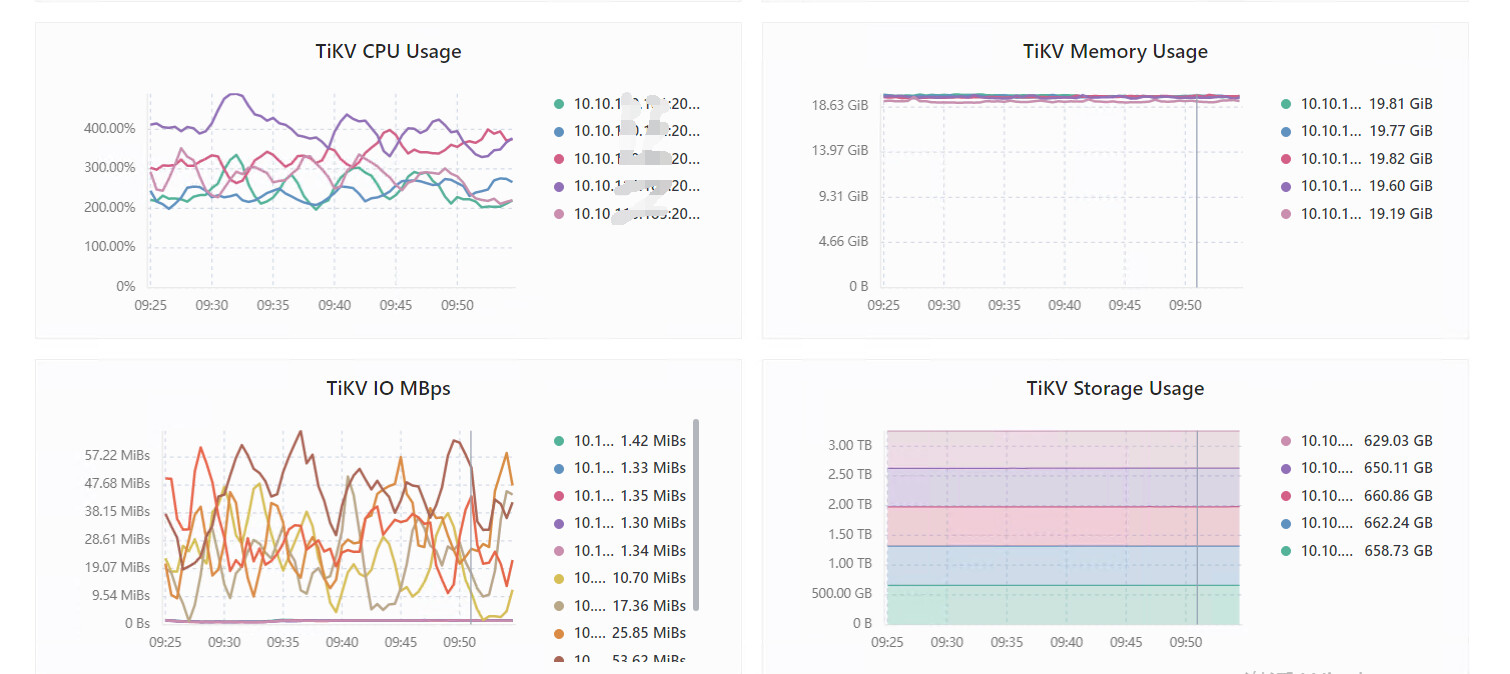
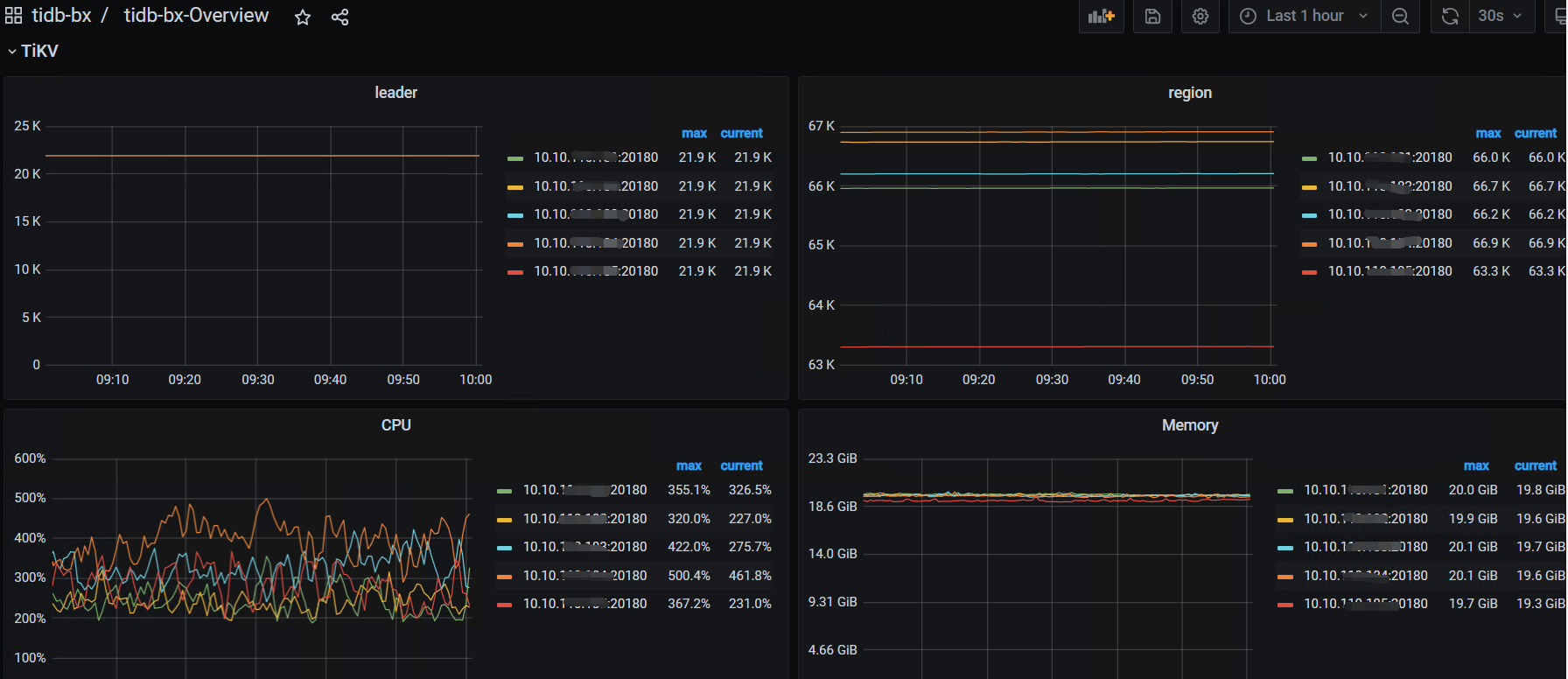
raft store cpu 利用率和 propose wait duration 的监控图能发下吗?
tikv的日志也发下吧
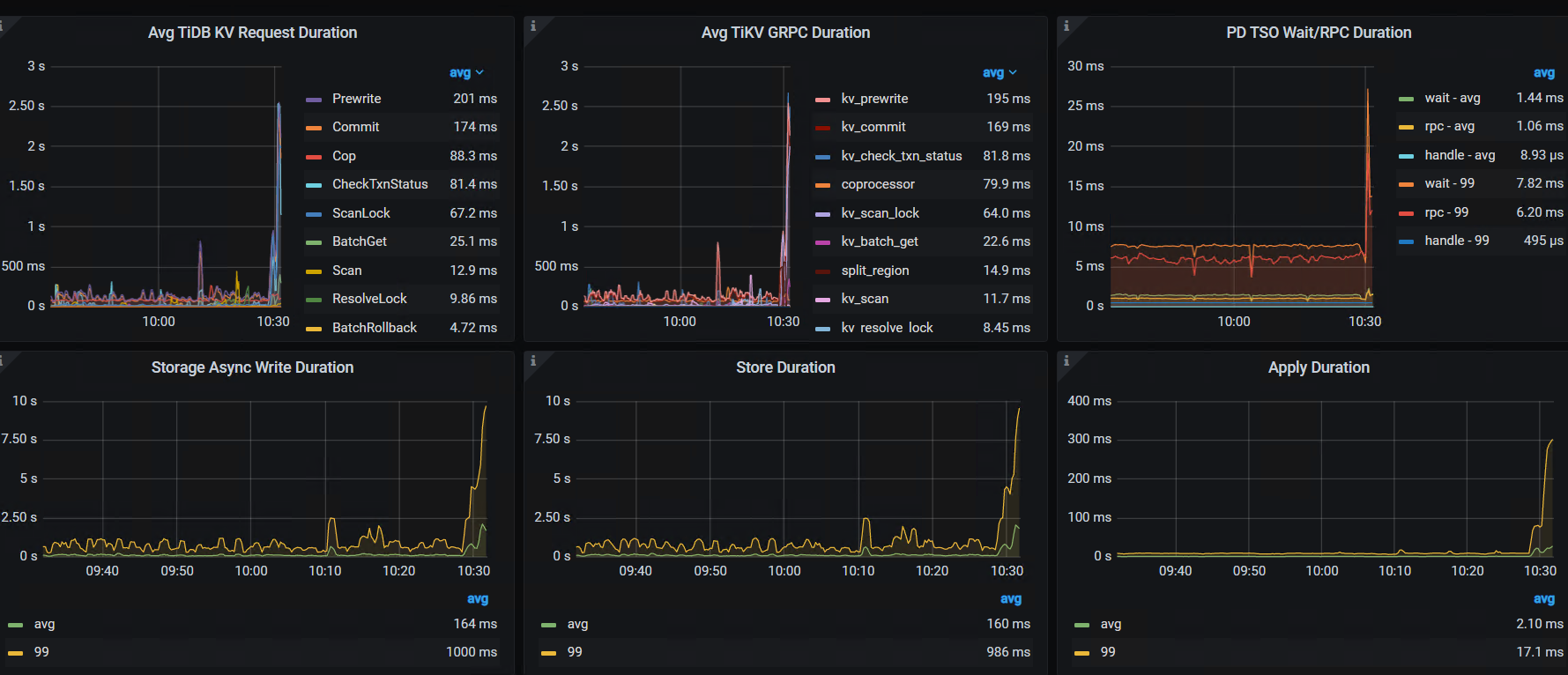
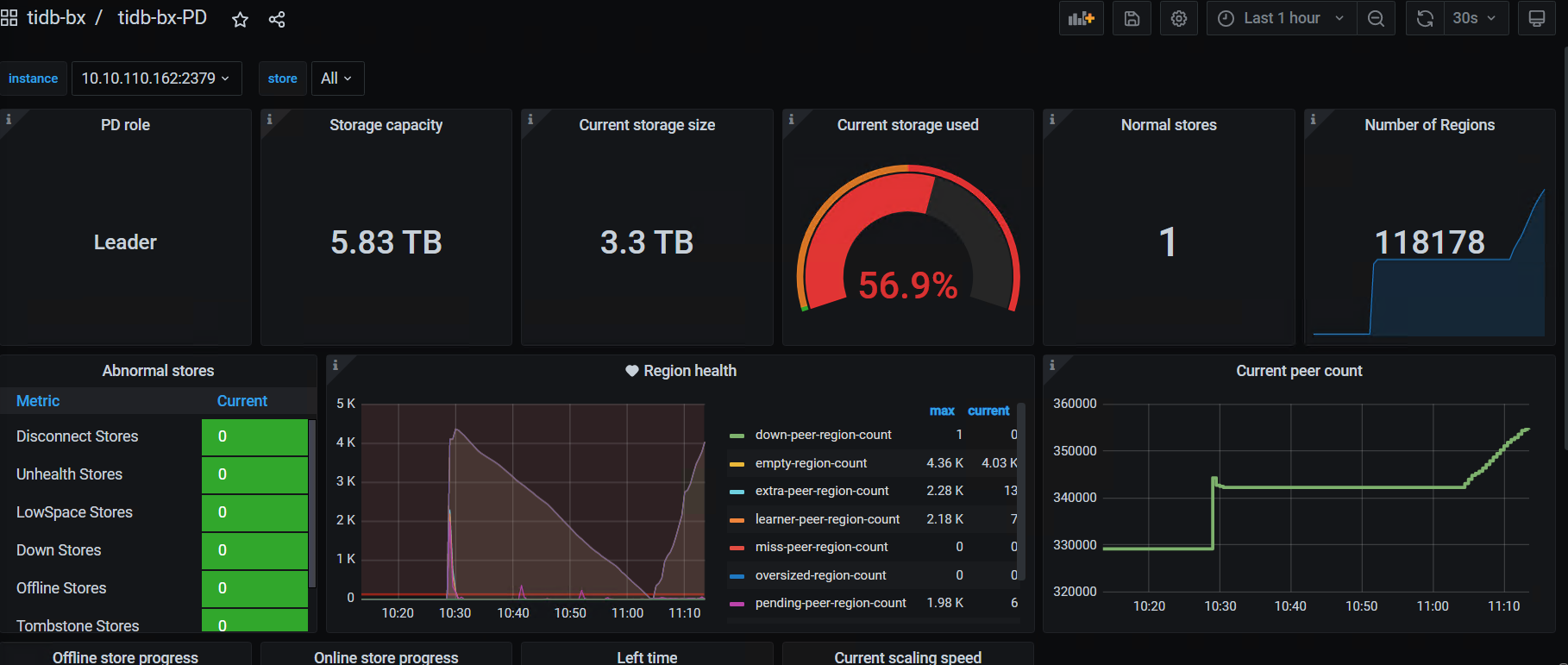
这几个监控:
PD — region -health
PD—Statistics - balance—store leader size / count /score
store region szie / count /score
TIKV Details— Thread CPU — raft store cpu /
磁盘的IO监控情况:
node_exporter ---- DISK
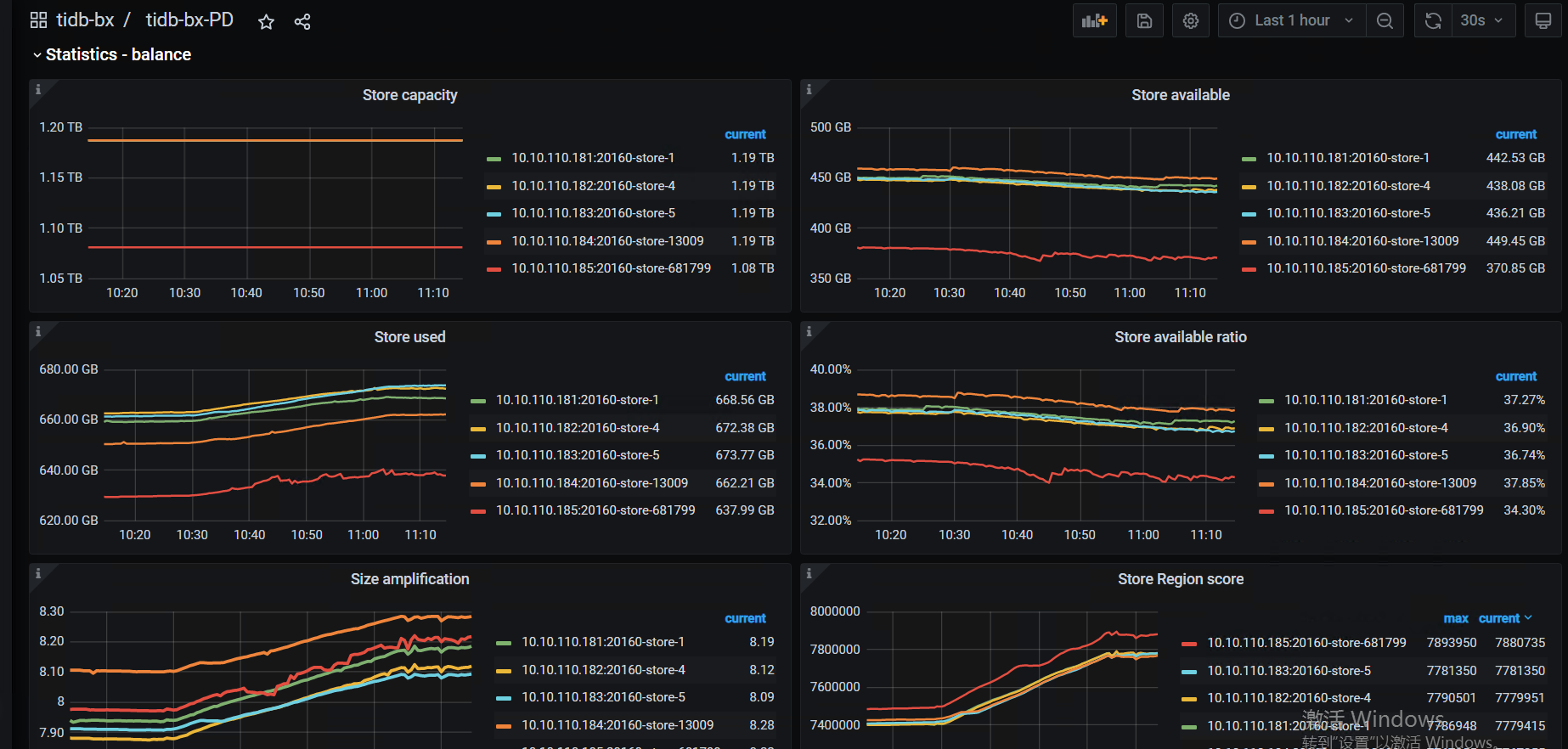
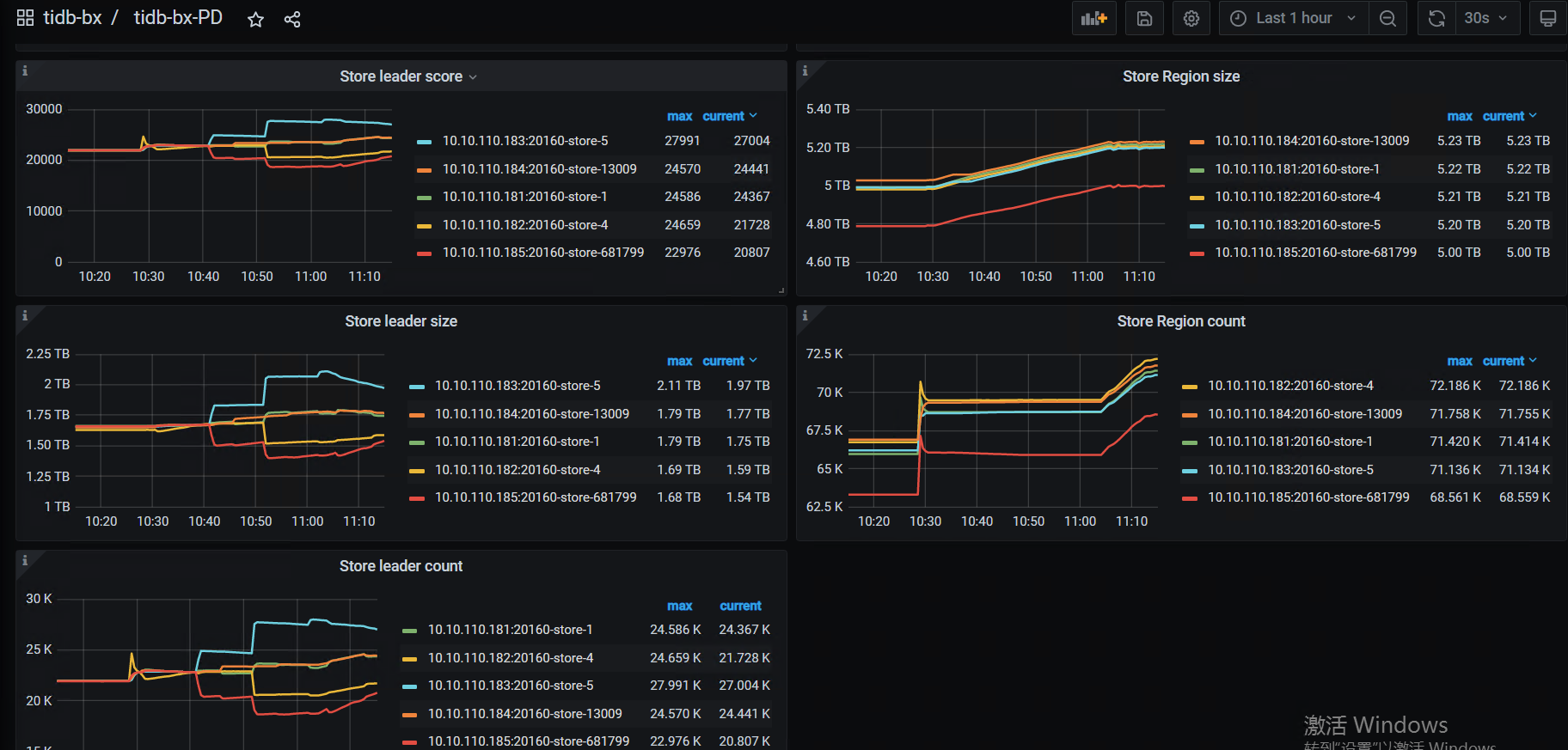
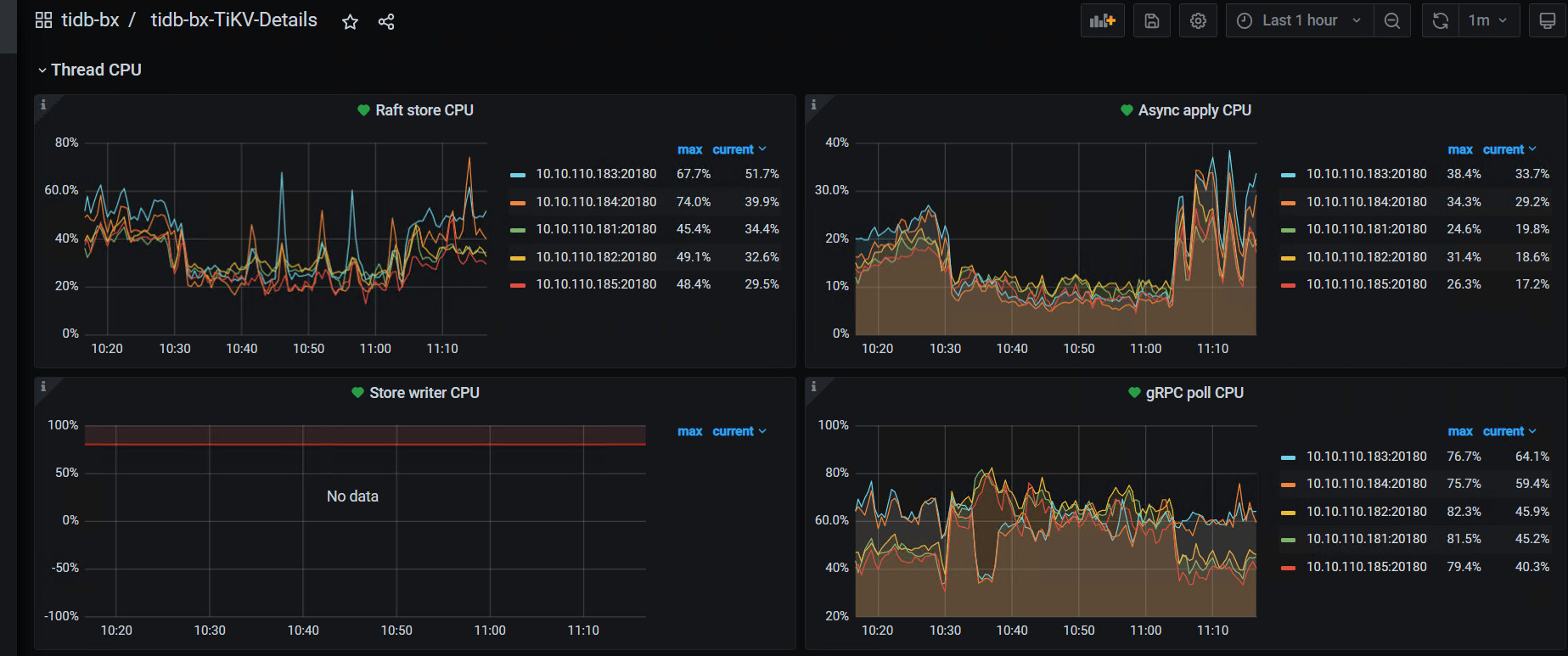
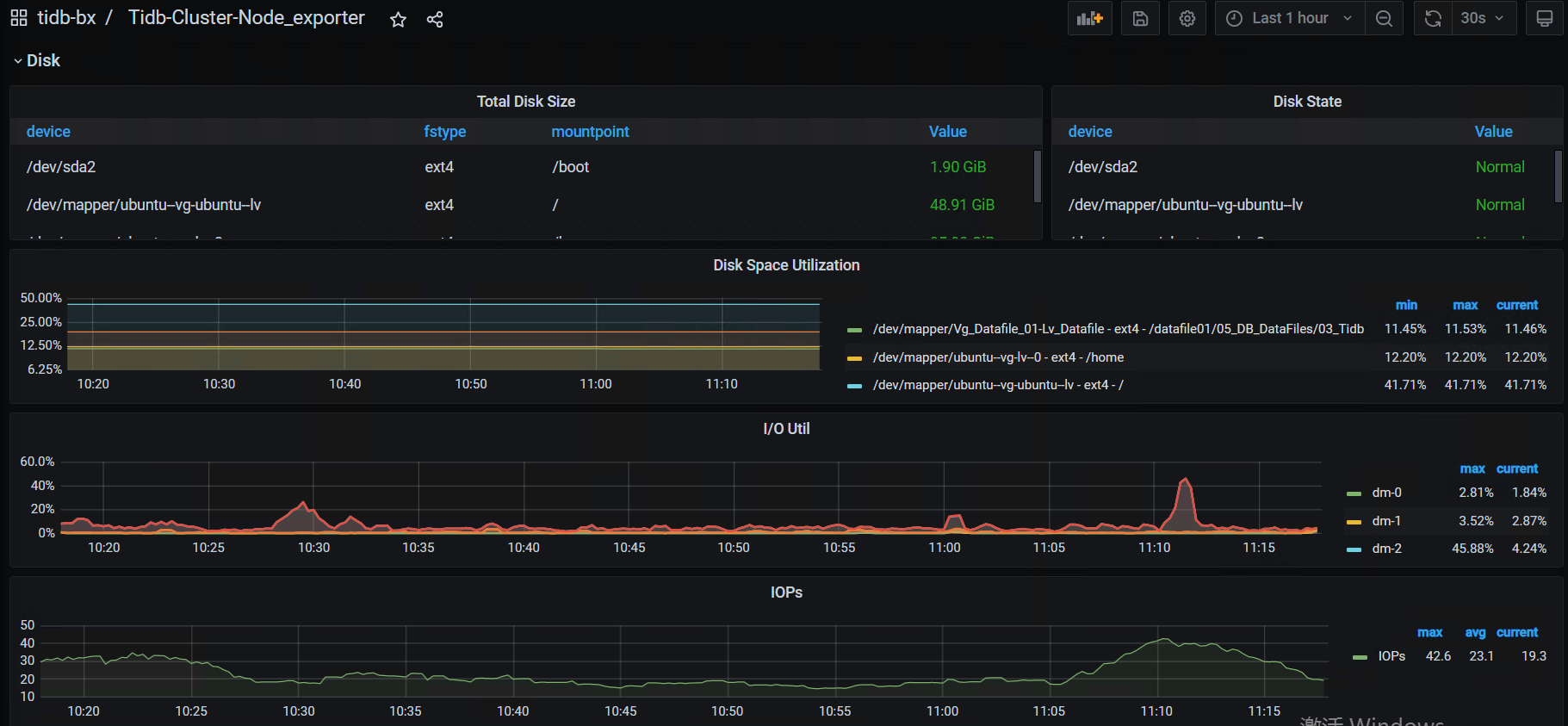
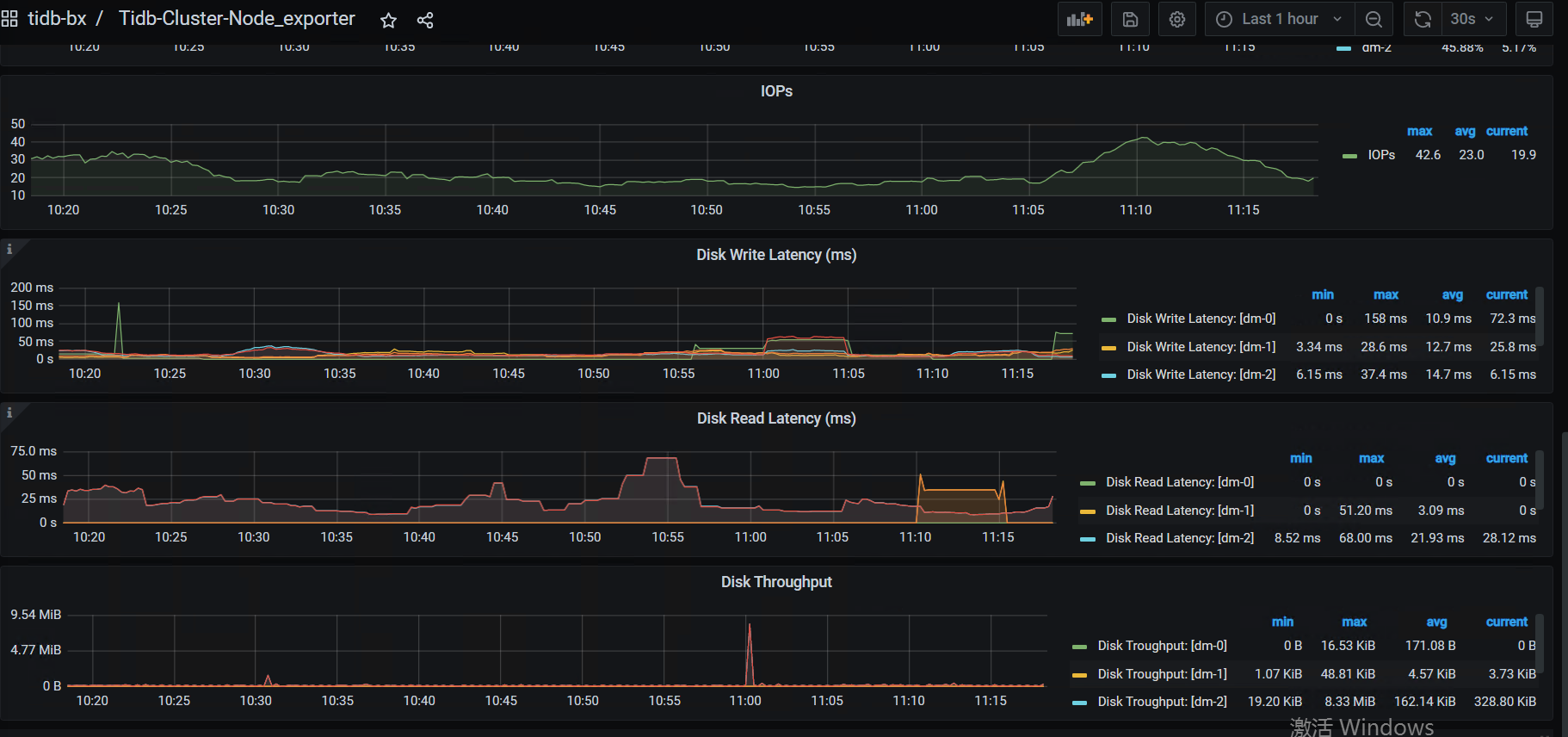
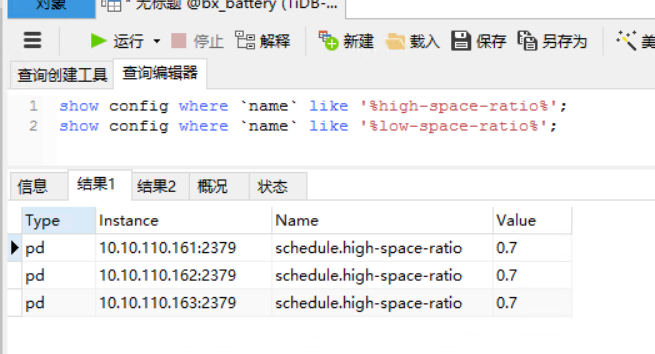
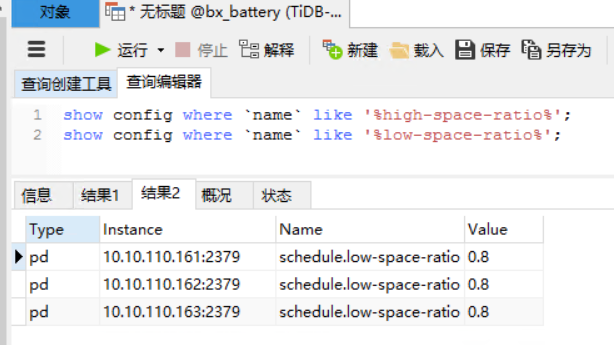
- 看看系统的high-space-ratio 和 low-space-ratio 设置是多大?磁盘使用量到系统默认的60%,会引起region调度。看看最近几天的监控,是不是比以前调度多了,如果是,可以适当调高点这两个参数。长久之计还是扩节点
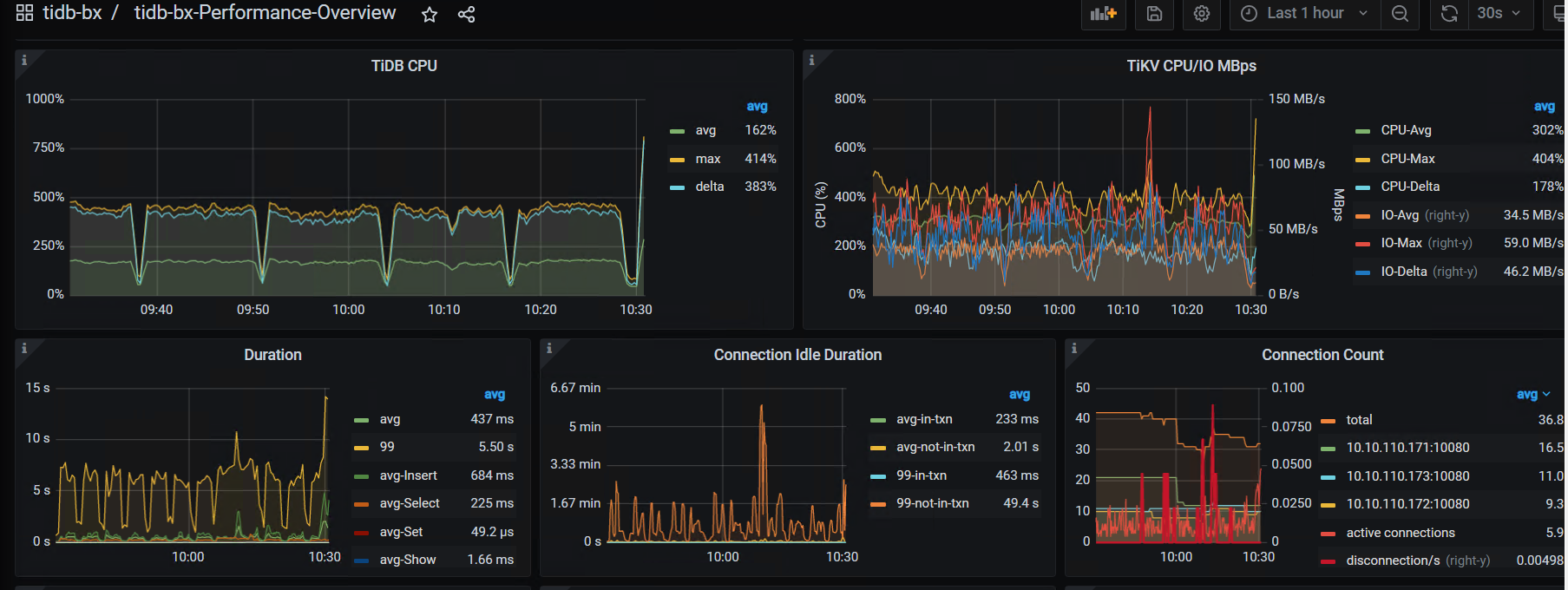
- 10:30的时候是有什么操作吗?region数有个突增,10点40左右leader有频繁的调度,这个时间点的tikv写延迟很高
- 提供下tikv的日志吧
- 另外,你的磁盘是什么类型的ssd?感觉有点慢啊
增加tikv吗?
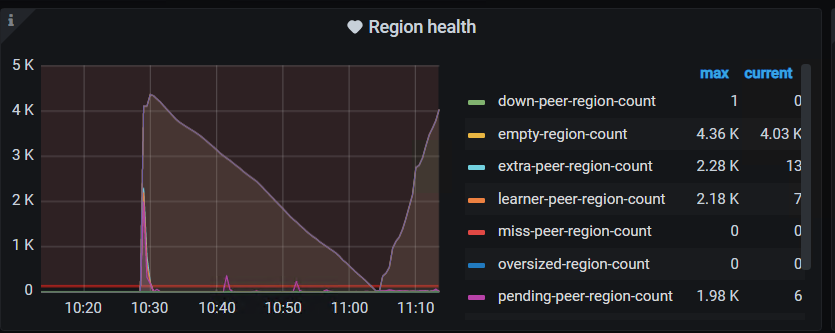
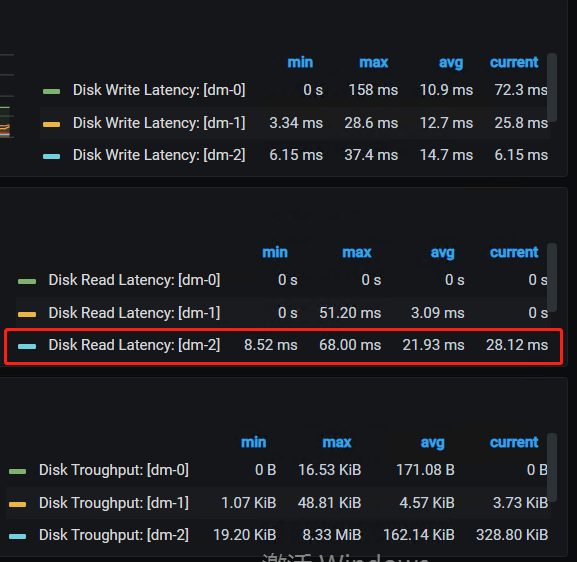
如何 优化下 empty region,减少损耗。 给个指导