SoHuDrgon
2023 年1 月 9 日 06:55
1
【 TiDB 使用环境】生产环境
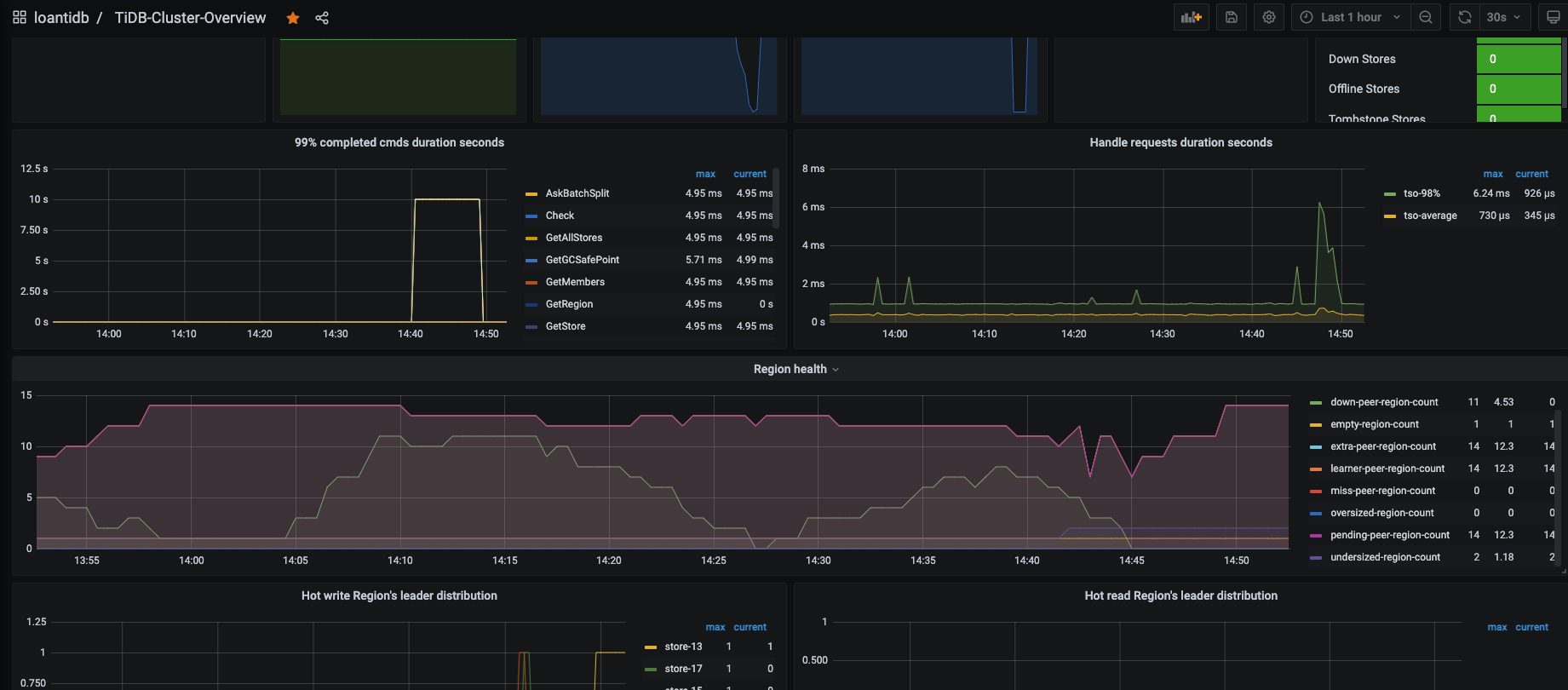
【遇到的问题:问题现象及影响】14 pending-peer
重启了TIKV还是这样。
pending_peer14.txt (17.8 KB)
WalterWj
2023 年1 月 9 日 07:07
2
pending 一般含义是指 tikv 这边压力过大,有排队堵塞。
这种情况不常见,是不是 compact 被异常关闭了?
WalterWj
2023 年1 月 9 日 09:08
4
WalterWj
2023 年1 月 9 日 09:09
5
集群有用过 lightning 或者修改过 tikv compact 相关配置么?还有集群压力大不大。一般都正常的话 很少会有 pending 的,pending 时间久了就应该会有 down peer 了。。。。。
WalterWj
2023 年1 月 9 日 09:09
6
看了一眼监控 你集群里面确实有 down peer。
SoHuDrgon
2023 年1 月 9 日 09:35
7
tikv-ctl 这个是每个tikv都需要安装吗?还是说只需要在其中一台上面执行就可以了?麻烦了。
SoHuDrgon
2023 年1 月 9 日 09:42
8
没有做lighting和修改,只是开发那边经常批量删除,用的那个batch delete命令。应该是那个影响的,就是不知道这个pending-peer多久会消失。
SoHuDrgon
2023 年1 月 9 日 09:45
9
并且我给一段时间执行region check pending-peer后的内容都是不一样的,但是pending-peer的条数都是14条,也不知道里面在干什么。集群只是每天会定时导入数据,大部分时间都是空闲的。
WalterWj
2023 年1 月 9 日 09:48
10
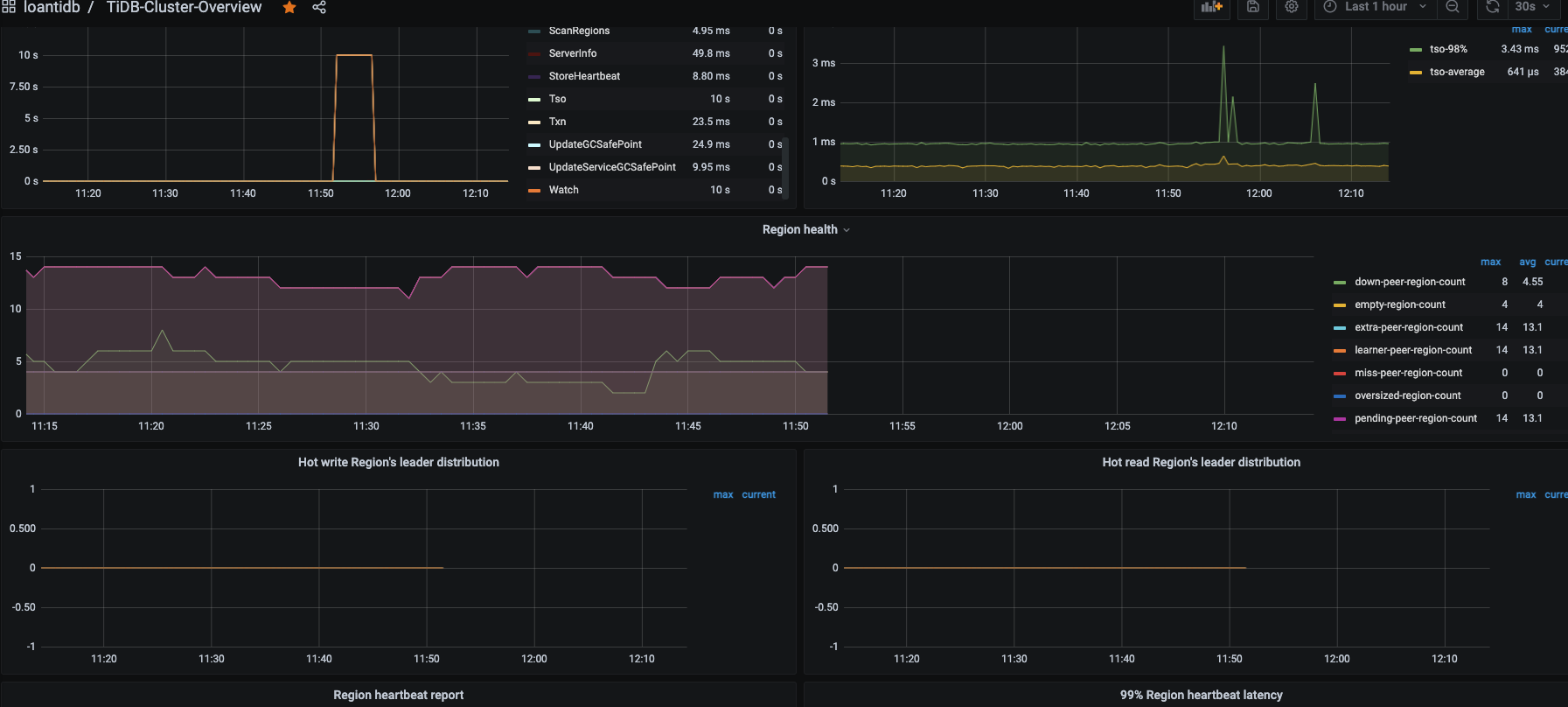
你可以拉开监控 比如看个 3 天的,看看有没有什么时间段 down 和 pending peer 都是消失的,有的话挑那个时间段去升级。
tikv 当前有做什么特殊配置么?也可以发来看看呐。
或者手动做下集群的 tikv compact:https://docs.pingcap.com/zh/tidb/dev/tikv-control#通用参数
WalterWj
2023 年1 月 9 日 09:49
11
SoHuDrgon
2023 年1 月 9 日 10:09
13
数据导入是开发写了一个java项目从其他地方拉取数据文件,然后再项目里面进行清洗后生成一个csv文件,每天执行一次每次大概300M的csv文件,java项目读取csv后生成sql,然后insert进TIDB的。
WalterWj
2023 年1 月 10 日 03:36
14
看了一眼 调整了好多 tikv 的配置,一般不推荐自己调整 raft 和 rocksdb 相关配置的 哎。
WalterWj
2023 年1 月 10 日 03:41
15
split-region-check-tick-interval – 没有必要调整 300 吧
检查 region 是否需要分裂的时间间隔,0 表示不启用。
默认值:10s
最小值:0
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file/#disable-auto-compactions
而且你关闭了 compact,调整下,开启 compact,手动可以用 tikv-ctl 做下 cluster compact。
不推荐改这些东西。
WalterWj
2023 年1 月 10 日 03:43
16
compact 不能关的,compact 是底层数据文件整理压缩,你关了 数据连 gc 都没法做的。
SoHuDrgon
2023 年1 月 10 日 03:52
17
好的,谢谢大佬,我马上改了重启一下tidb,然后观察一下。
SoHuDrgon
2023 年1 月 10 日 04:14
18
改了你说的两个参数:
WalterWj
2023 年1 月 10 日 05:03
19
感觉你的监控有点问题,compact 应该没那么快搞完
SoHuDrgon
2023 年1 月 10 日 05:27
20
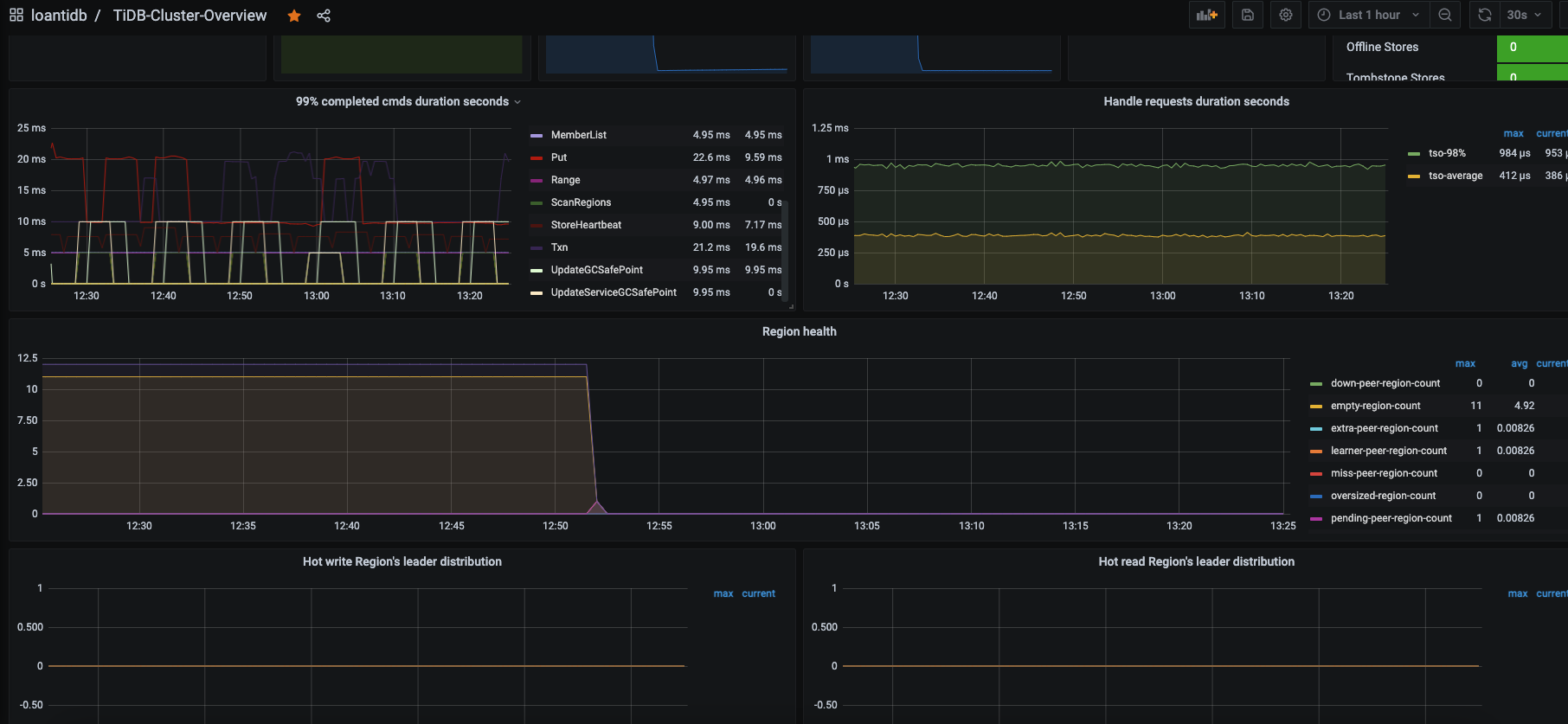
看着好像可以了,我重启了一下prometheus。
然后check了一下pending-peer:
Starting component ctl: /root/.tiup/components/ctl/v6.1.0/ctl pd -i -u http://127.0.0.1:2379
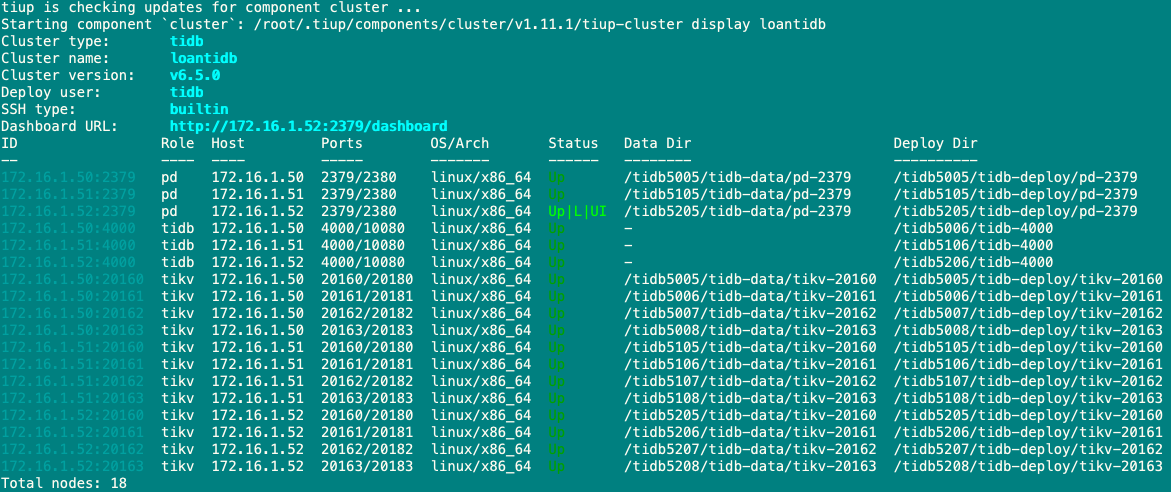
升级也快速完成了: