japson
2023 年1 月 6 日 10:02
1
【 TiDB 使用环境】生产环境github.com/pingcap/tidb/parser/terror.Log \n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/parser/terror/terror.go:307\ngithub.com/pingcap/tidb/server.(*Server).onConn\n\t/home/jenkins/agent/workspace/build-common/go/src/github.com/pingcap/tidb/server/server.go:516”]
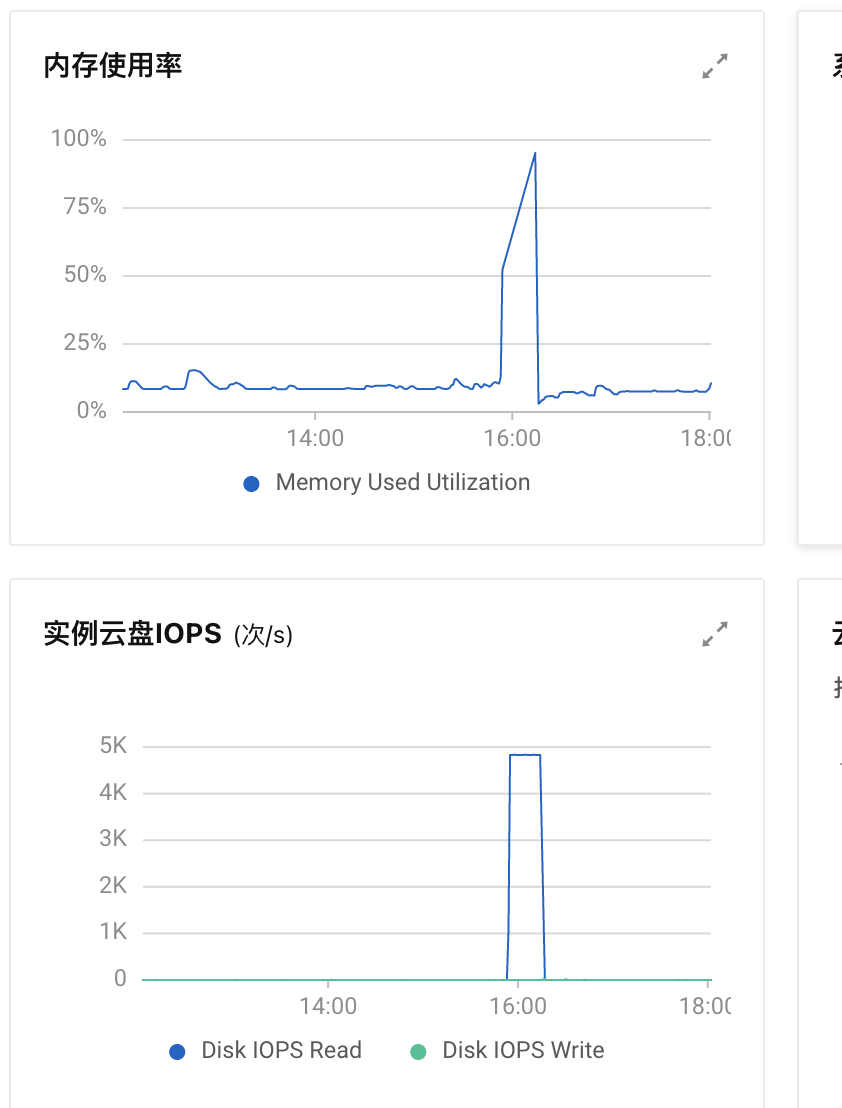
问题二:这个集群,今天突然一瞬间内存被打满,然后tidb server io也被打满,导致无法响应业务。
磁盘满了,内存也满了,明显有扫描表的动作,检查下是不是有新的sql上线。
japson
2023 年1 月 6 日 11:08
4
在dashboard上没有看到特别的慢sql,但是我在日志里面看到有个比较特别的慢sql,
ffeenn
2023 年1 月 7 日 01:43
5
没有特别慢的,并发很多的查询几十万的表也很可怕,看看cpu使用率怎么样
japson
2023 年1 月 9 日 02:08
7
cpu使用率很低,并且这个集群是内部系统,并发不高,目前看来最有怀疑的就是sql="SELECT * from parts_status\r\n where ORDER_NO in (,。。。。),这张表很小,只有几十万,但是这个in里面内容有点多。我们把这个改掉了,再持续观察。
japson
2023 年1 月 9 日 02:34
9
确实是的,但是有一点奇怪的是,tikv并没有大的流量,集群也没有高的负载,如果单存是慢sql的问题,我想tikv的流量或性能一定会有特别的不一样的
这个报错是 TiDB 到其他组件连接,主动断开以后的日志输出。可以先忽略,不影响集群的正常服务和使用。
瞬间打满常见全表扫或者 Hashjoin 聚合计算在 TiDB Sever 汇聚大量数据进行计算时候,可以排查一下 slow query 中统计信息不准确或者全表扫的 Slow query ,可以参考一下查询 SQL 的问题。https://docs.pingcap.com/zh/tidb/stable/identify-slow-queries#查询-slow_querycluster_slow_query-示例
system
2023 年3 月 19 日 10:46
12
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。