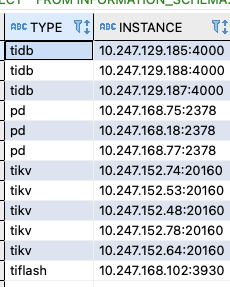
2023-01-10T07:31:22.234Z ERROR CheckPoint {“host”: “10.247.168.75”, “port”: 22, “user”: “tidb”, “sudo”: true, “cmd”: “systemctl daemon-reload && systemctl enable node_exporter-9100.service”, “stdout”: “”, “stderr”: “Failed to execute operation: No such file or directory\n”, “error”: “executor.ssh.execute_failed: Failed to execute command over SSH for ‘tidb@10.247.168.75:22’ {ssh_stderr: Failed to execute operation: No such file or directory\n, ssh_stdout: , ssh_command: export LANG=C; PATH=$PATH:/bin:/sbin:/usr/bin:/usr/sbin /usr/bin/sudo -H bash -c "systemctl daemon-reload && systemctl enable node_exporter-9100.service"}, cause: Process exited with status 1”, “errorVerbose”: “executor.ssh.execute_failed: Failed to execute command over SSH for ‘tidb@10.247.168.75:22’ {ssh_stderr: Failed to execute operation: No such file or directory\n, ssh_stdout: , ssh_command: export LANG=C; PATH=$PATH:/bin:/sbin:/usr/bin:/usr/sbin /usr/bin/sudo -H bash -c "systemctl daemon-reload && systemctl enable node_exporter-9100.service"}, cause: Process exited with status 1\n at github.com/pingcap/tiup/pkg/cluster/executor.(*EasySSHExecutor).Execute()\n\tgithub.com/pingcap/tiup/pkg/cluster/executor/ssh.go:174\n at github.com/pingcap/tiup/pkg/cluster/executor.(*CheckPointExecutor).Execute()\n\tgithub.com/pingcap/tiup/pkg/cluster/executor/checkpoint.go:85\n at github.com/pingcap/tiup/pkg/cluster/module.(*SystemdModule).Execute()\n\tgithub.com/pingcap/tiup/pkg/cluster/module/systemd.go:98\n at github.com/pingcap/tiup/pkg/cluster/operation.systemctl()\n\tgithub.com/pingcap/tiup/pkg/cluster/operation/action.go:376\n at github.com/pingcap/tiup/pkg/cluster/operation.systemctlMonitor.func1()\n\tgithub.com/pingcap/tiup/pkg/cluster/operation/action.go:286\n at golang.org/x/sync/errgroup.(*Group).Go.func1()\n\tgolang.org/x/sync@v0.0.0-20210220032951-036812b2e83c/errgroup/errgroup.go:57\n at runtime.goexit()\n\truntime/asm_amd64.s:1581”, “hash”: “ce8eb0a645cc3ead96a44d67b1ecd5034d112cf0”, “func”: “github.com/pingcap/tiup/pkg/cluster/executor.(*CheckPointExecutor).Execute”, “hit”: false}