【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.3
【复现路径】
业务代码中开启一个事务:
先通过select for update 拿到指定数值,然后再update 一下数据。
这种事务会有上百个并发

CREATE TABLE `tb_task` (
`task_id` varchar(64) NOT NULL COMMENT '任务ID',
`type` tinyint(3) unsigned NOT NULL COMMENT '任务类型',
`status` tinyint(3) unsigned NOT NULL COMMENT '任务状态',
`trigger_type` tinyint(3) unsigned NOT NULL COMMENT '任务触发类型 online/offline',
`size` bigint(20) NOT NULL COMMENT '大小',
`zos_file` text NOT NULL COMMENT '模板下载地址',
`params` text NOT NULL COMMENT '请求内容',
`expect_time` datetime NOT NULL COMMENT '期望转换时间',
`start_time` datetime NOT NULL COMMENT '转换开始时间',
`end_time` datetime NOT NULL COMMENT '转换结束时间',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '插入时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`task_id`) /*T![clustered_index] NONCLUSTERED */,
KEY `idx_status` (`status`),
KEY `idx_trigger_status` (`trigger_type`,`expect_time`,`status`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T! SHARD_ROW_ID_BITS=4 */
SELECT * FROM `tb_task` WHERE status IN (0) AND `trigger_type` = 2 ORDER BY expect_time asc LIMIT 1 FOR UPDATE;
【遇到的问题】
某个tikv 节点cpu load 很高
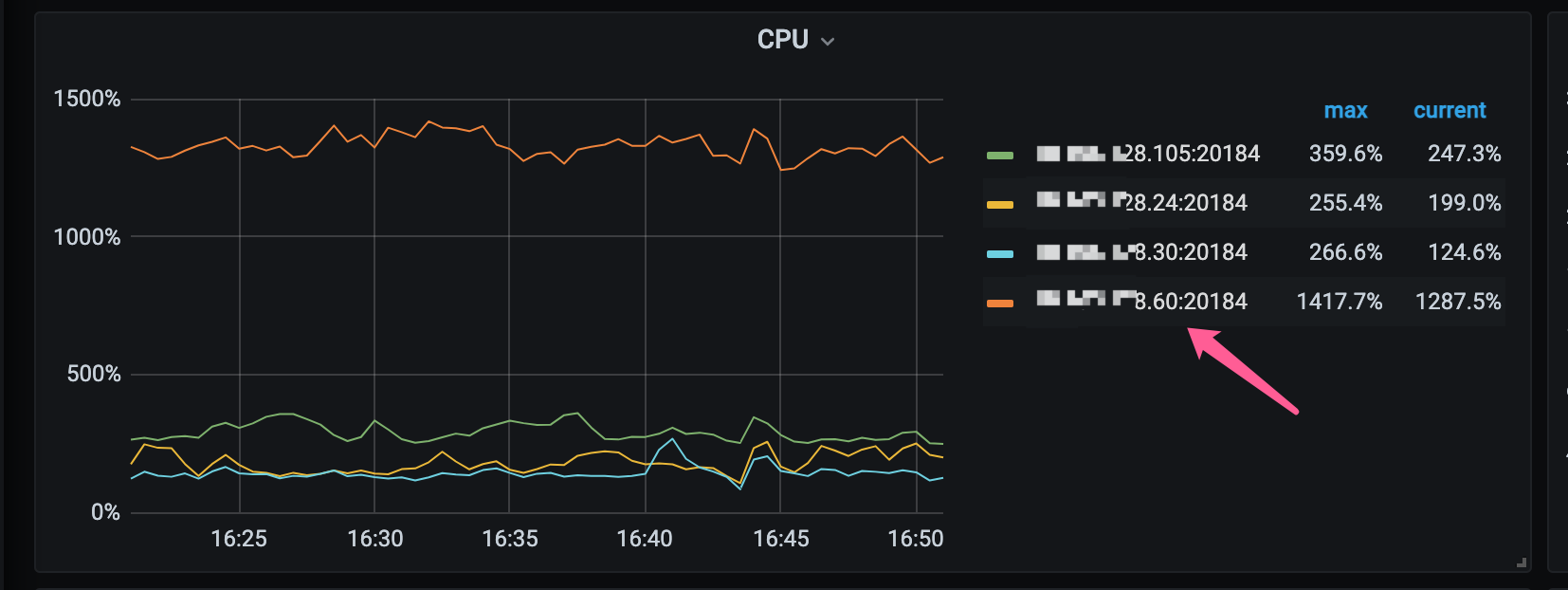
【资源配置】
384G 96C
【附件:截图/日志/监控】
我把写写冲突的重试参数改成了1 pessimistic-txn.max-retry-count 1
tidb.log
[2022/12/27 16:13:58.094 +08:00] [INFO] [conn.go:1121] ["command dispatched failed"] [conn=7231] [connInfo="id:7231, addr:10.96.13.165:34360 status:11, collation:utf8mb4_general_ci, user:officeser_app"] [command=Execute] [status="inTxn:1, autocommit:1"] [sql="SELECT * FROM `tb_task` WHERE status IN (?) AND `trigger_type` = ? ORDER BY expect_time asc LIMIT 1 FOR UPDATE [arguments: (0, 2)]"] [txn_mode=PESSIMISTIC] [err="pessimistic lock retry limit reached
tikv.log
[2022/12/27 16:53:12.092 +08:00] [WARN] [endpoint.rs:606] [error-response] [err="Key is locked (will clean up) primary_lock: 7480000000000000E95F7280000000000B4D4B lock_version: 438339158937698344 key: 7480000000000000E95F6980000000000000030400000000000000020419AEB55E670000000400000000000000000380000000000B4D4B lock_ttl: 3719 txn_size: 2 lock_type: Del lock_for_update_ts: 438339159121461437 min_commit_ts: 438339159121461438"]
问题:
1、为什么这种操作会导致tikv 的cpu load 这么高呢 ?
2、如果是因为写写冲突的重试,但是我在相关的指标上看好像不太符合文章中的描述

3、我在tikv 的大盘上看到 index 操作量异常大 ,如何解读这个指标?

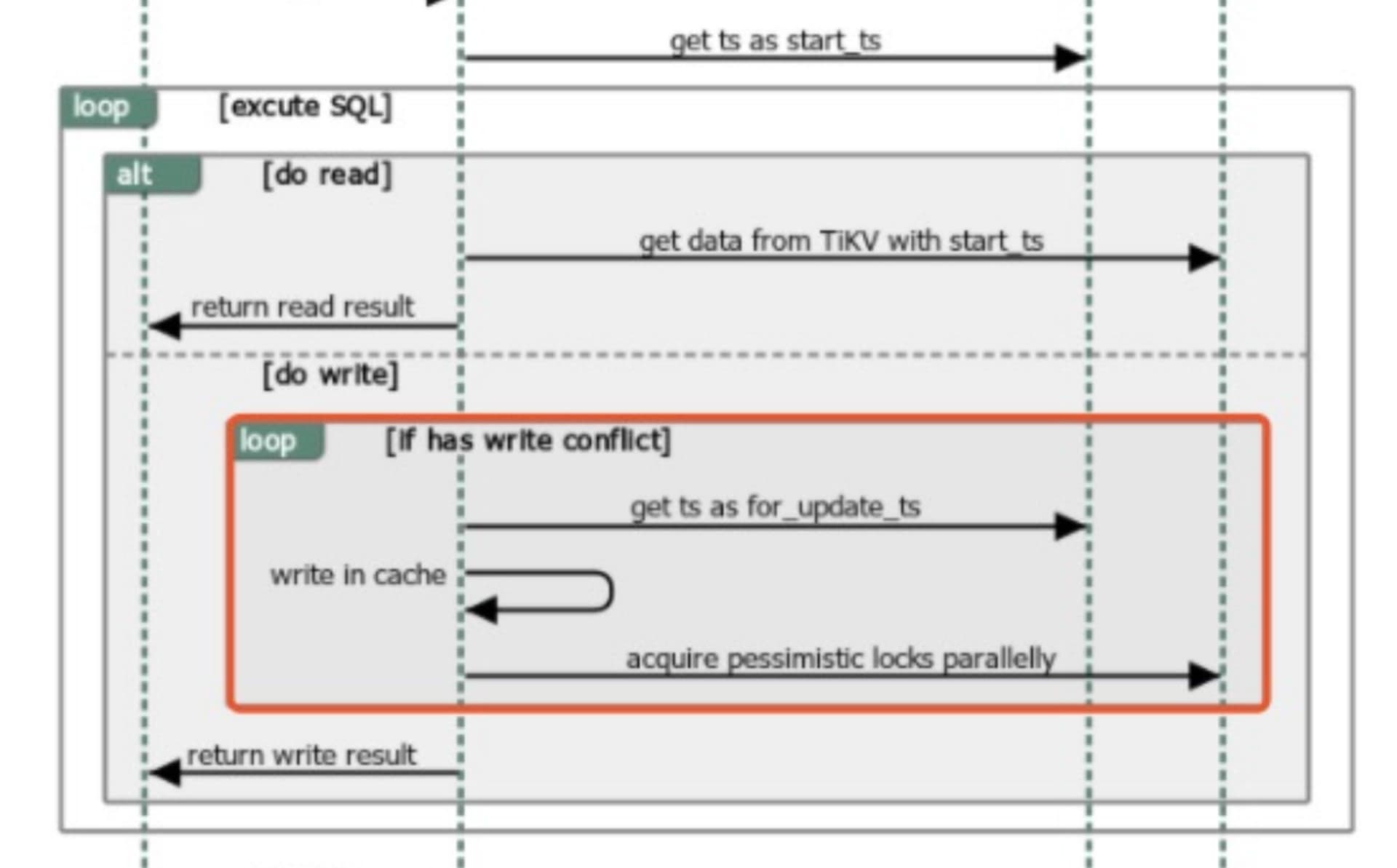
上面的index 操作能否对应到下图的其中某一步中 ?