【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】5.3.3
【遇到的问题:问题现象及影响】
生产系统这两天一直莫名其妙的告警,pd和tidb均有,报节点重启的告警。
func (s ProcStat) StartTime() (float64, error) {
fs := FS{proc: s.proc}
stat, err := fs.Stat()
if err != nil {
return 0, err
}
return float64(stat.BootTime) + (float64(s.Starttime) / userHZ), nil
}
看了下代码,取值是系统时间点+进程启动时系统已分配的clock ticket对应的时长=进程启动时间点。
0 */6 * * * /usr/sbin/ntpdate ntp.cloud.aliyuncs.com ntp7.cloud.aliyuncs.com > /dev/null 2>&1
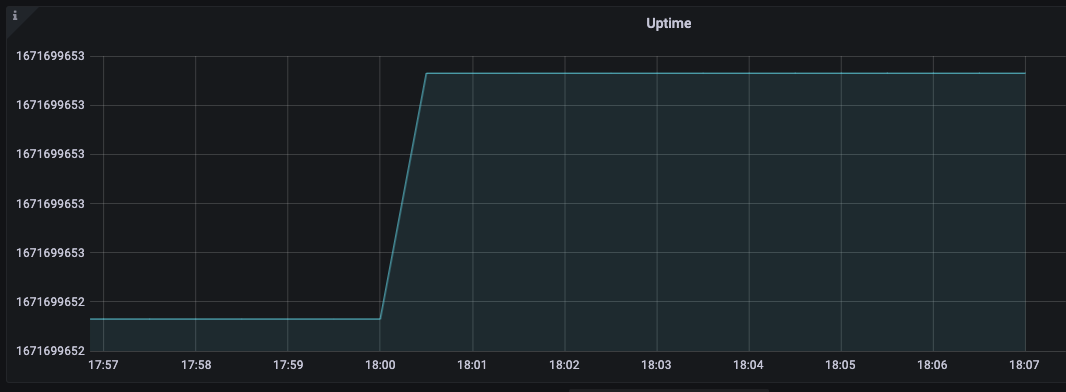
正好ntpdate每隔6个小时会同步一次,在18:00强行同步设置了系统时间,增大了1s,但不会修改clock ticket。

导致StartTime函数返回的值也大了1s,对应上grafana图:
官方对应pd或者tidb的restart的rule为
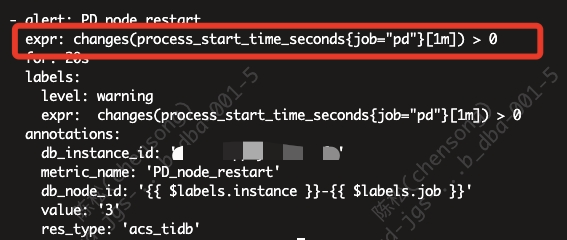
这边要改一下逻辑,再加一下间隔时间>10s优化一下这个问题。 process_start_time_seconds{job=“tidb”} - (process_start_time_seconds{job=“tidb”} offset 1m) >= 10