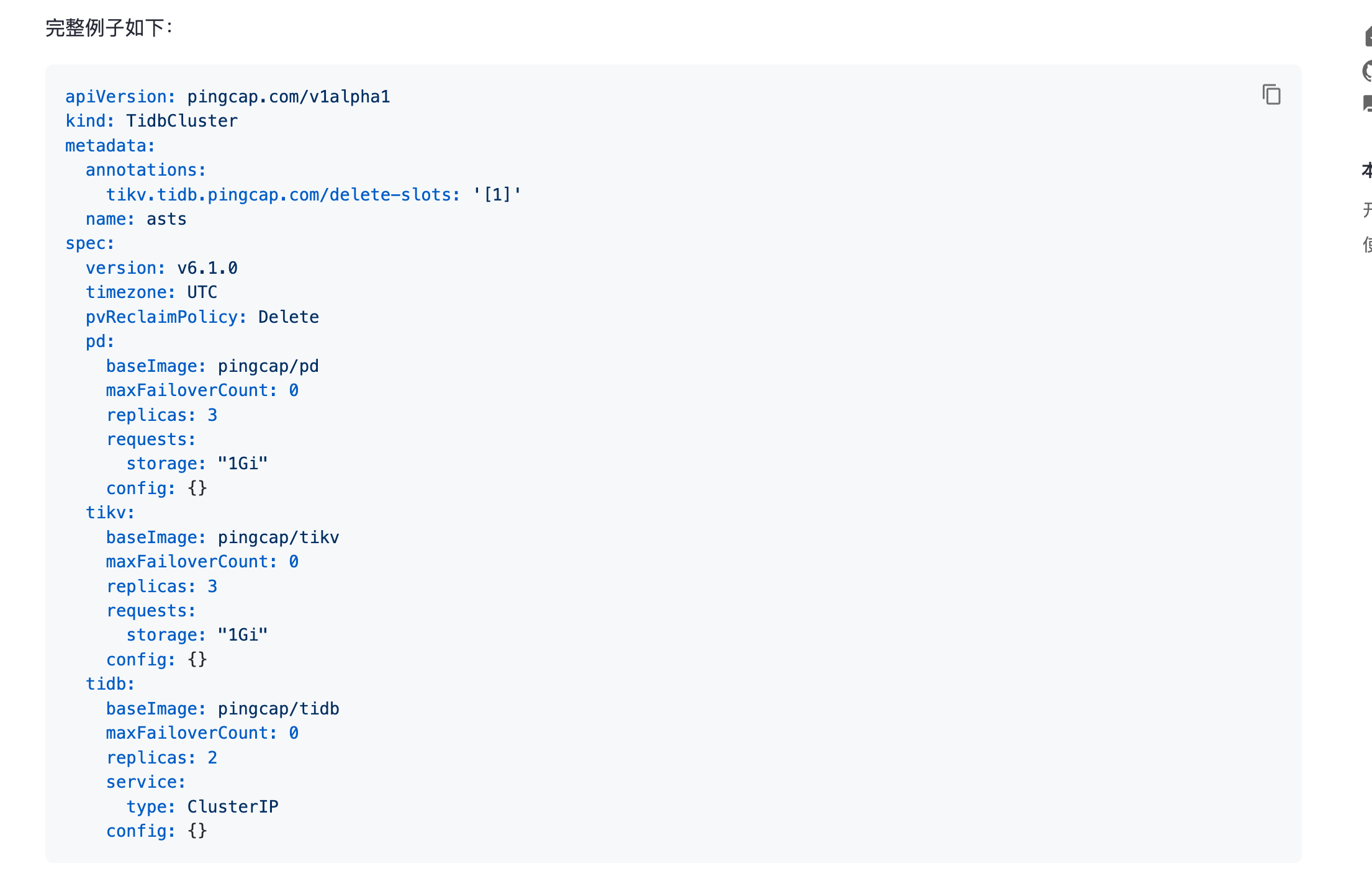
kubectl -n tidb-cluster get tc pre-test -ojson
{
“apiVersion”: “pingcap.com/v1alpha1”,
“kind”: “TidbCluster”,
“metadata”: {
“annotations”: {
“meta.helm.sh/release-name”: “pre-test”,
“meta.helm.sh/release-namespace”: “tidb-cluster”,
“pingcap.com/ha-topology-key”: “kubernetes.io/hostname”,
“pingcap.com/pd.pre-test-pd.sha”: “cfa0d77a”,
“pingcap.com/tidb.pre-test-tidb.sha”: “866b9771”,
“pingcap.com/tikv.pre-test-tikv.sha”: “1c8d5543”
},
“creationTimestamp”: “2022-11-24T03:30:41Z”,
“generation”: 5747,
“labels”: {
“app.kubernetes.io/component”: “tidb-cluster”,
“app.kubernetes.io/instance”: “pre-test”,
“app.kubernetes.io/managed-by”: “Helm”,
“app.kubernetes.io/name”: “tidb-cluster”,
“helm.sh/chart”: “tidb-cluster-v1.3.9”
},
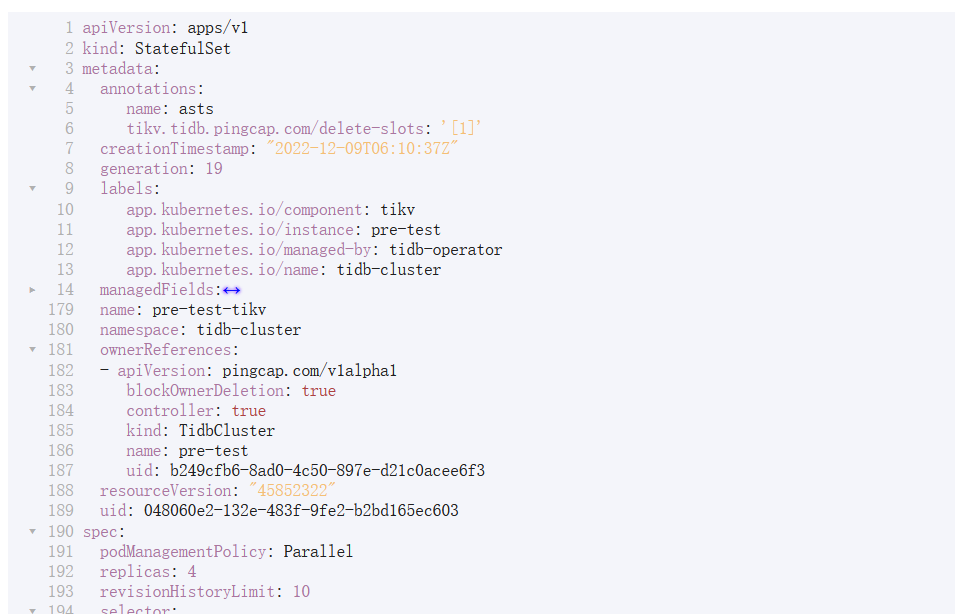
“name”: “pre-test”,
“namespace”: “tidb-cluster”,
“resourceVersion”: “46472491”,
“uid”: “b249cfb6-8ad0-4c50-897e-d21c0acee6f3”
},
“spec”: {
“discovery”: {},
“enablePVReclaim”: false,
“helper”: {
“image”: “busybox:1.34.1”
},
“imagePullPolicy”: “IfNotPresent”,
“pd”: {
“affinity”: {},
“baseImage”: “pingcap/pd”,
“hostNetwork”: false,
“image”: “pingcap/pd:v6.1.0”,
“imagePullPolicy”: “IfNotPresent”,
“maxFailoverCount”: 3,
“replicas”: 3,
“requests”: {
“storage”: “5Gi”
},
“storageClassName”: “longhorn”
},
“pvReclaimPolicy”: “Retain”,
“schedulerName”: “default-scheduler”,
“services”: [
{
“name”: “pd”,
“type”: “ClusterIP”
}
],
“tidb”: {
“affinity”: {},
“baseImage”: “pingcap/tidb”,
“binlogEnabled”: false,
“hostNetwork”: false,
“image”: “pingcap/tidb:v6.1.0”,
“imagePullPolicy”: “IfNotPresent”,
“maxFailoverCount”: 3,
“replicas”: 2,
“separateSlowLog”: true,
“slowLogTailer”: {
“image”: “busybox:1.33.0”,
“imagePullPolicy”: “IfNotPresent”,
“limits”: {
“cpu”: “100m”,
“memory”: “50Mi”
},
“requests”: {
“cpu”: “20m”,
“memory”: “5Mi”
}
},
“tlsClient”: {}
},
“tikv”: {
“affinity”: {},
“baseImage”: “pingcap/tikv”,
“hostNetwork”: false,
“image”: “pingcap/tikv:v6.1.0”,
“imagePullPolicy”: “IfNotPresent”,
“maxFailoverCount”: 3,
“replicas”: 3,
“requests”: {
“storage”: “110Gi”
},
“storageClassName”: “longhorn”
},
“timezone”: “UTC”,
“tlsCluster”: {},
“version”: “v6.1.0”
},
“status”: {
“clusterID”: “7169420034058589617”,
“conditions”: [
{
“lastTransitionTime”: “2022-12-09T06:27:02Z”,
“lastUpdateTime”: “2022-12-12T04:00:25Z”,
“message”: “TiKV store(s) are not up”,
“reason”: “TiKVStoreNotUp”,
“status”: “False”,
“type”: “Ready”
}
],
“pd”: {
“image”: “pingcap/pd:v6.1.0”,
“leader”: {
“clientURL”: “http://pre-test-pd-2.pre-test-pd-peer.tidb-cluster.svc:2379”,
“health”: true,
“id”: “6858210497469881484”,
“lastTransitionTime”: “2022-11-24T03:37:24Z”,
“name”: “pre-test-pd-2”
},
“members”: {
“pre-test-pd-0”: {
“clientURL”: “http://pre-test-pd-0.pre-test-pd-peer.tidb-cluster.svc:2379”,
“health”: true,
“id”: “7715448974209056711”,
“lastTransitionTime”: “2022-11-24T03:38:11Z”,
“name”: “pre-test-pd-0”
},
“pre-test-pd-1”: {
“clientURL”: “http://pre-test-pd-1.pre-test-pd-peer.tidb-cluster.svc:2379”,
“health”: true,
“id”: “13787701961152413026”,
“lastTransitionTime”: “2022-11-24T03:37:41Z”,
“name”: “pre-test-pd-1”
},
“pre-test-pd-2”: {
“clientURL”: “http://pre-test-pd-2.pre-test-pd-peer.tidb-cluster.svc:2379”,
“health”: true,
“id”: “6858210497469881484”,
“lastTransitionTime”: “2022-11-24T03:37:24Z”,
“name”: “pre-test-pd-2”
}
},
“phase”: “Normal”,
“statefulSet”: {
“collisionCount”: 0,
“currentReplicas”: 3,
“currentRevision”: “pre-test-pd-6f74b4fbff”,
“observedGeneration”: 6,
“readyReplicas”: 3,
“replicas”: 3,
“updateRevision”: “pre-test-pd-6f74b4fbff”,
“updatedReplicas”: 3
},
“synced”: true,
“volumes”: {
“pd”: {
“boundCount”: 3,
“currentCapacity”: “5Gi”,
“currentCount”: 3,
“name”: “pd”,
“resizedCapacity”: “5Gi”,
“resizedCount”: 3
}
}
},
“pump”: {},
“ticdc”: {},
“tidb”: {
“image”: “pingcap/tidb:v6.1.0”,
“members”: {
“pre-test-tidb-0”: {
“health”: true,
“lastTransitionTime”: “2022-11-24T03:40:44Z”,
“name”: “pre-test-tidb-0”,
“node”: “amj-3”
},
“pre-test-tidb-1”: {
“health”: true,
“lastTransitionTime”: “2022-11-24T03:39:33Z”,
“name”: “pre-test-tidb-1”,
“node”: “amj-2”
}
},
“phase”: “Normal”,
“statefulSet”: {
“collisionCount”: 0,
“currentReplicas”: 2,
“currentRevision”: “pre-test-tidb-6dfc65fff7”,
“observedGeneration”: 5,
“readyReplicas”: 2,
“replicas”: 2,
“updateRevision”: “pre-test-tidb-6dfc65fff7”,
“updatedReplicas”: 2
}
},
“tiflash”: {},
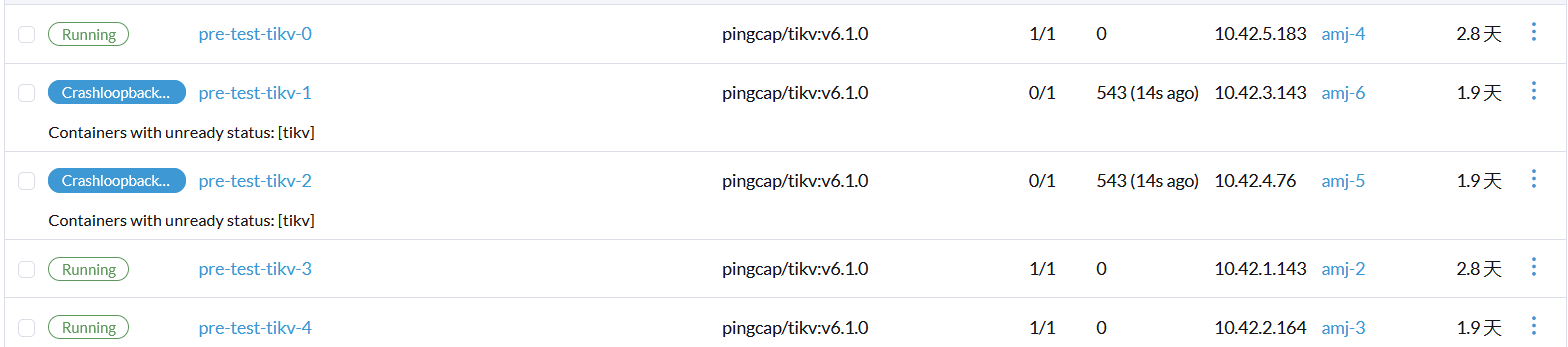
“tikv”: {
“bootStrapped”: true,
“image”: “pingcap/tikv:v6.1.0”,
“phase”: “Scale”,
“statefulSet”: {
“collisionCount”: 0,
“currentReplicas”: 5,
“currentRevision”: “pre-test-tikv-78b778fcb”,
“observedGeneration”: 3,
“readyReplicas”: 3,
“replicas”: 5,
“updateRevision”: “pre-test-tikv-78b778fcb”,
“updatedReplicas”: 5
},
“stores”: {
“1”: {
“id”: “1”,
“ip”: “pre-test-tikv-0.pre-test-tikv-peer.tidb-cluster.svc”,
“lastTransitionTime”: “2022-12-12T04:00:49Z”,
“leaderCount”: 4,
“podName”: “pre-test-tikv-0”,
“state”: “Up”
},
“4”: {
“id”: “4”,
“ip”: “pre-test-tikv-1.pre-test-tikv-peer.tidb-cluster.svc”,
“lastTransitionTime”: “2022-12-12T02:59:04Z”,
“leaderCount”: 8,
“podName”: “pre-test-tikv-1”,
“state”: “Down”
},
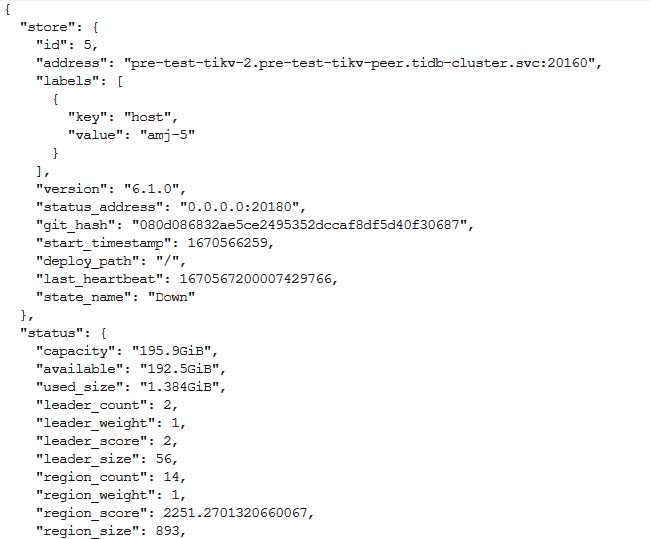
“5”: {
“id”: “5”,
“ip”: “pre-test-tikv-2.pre-test-tikv-peer.tidb-cluster.svc”,
“lastTransitionTime”: “2022-12-12T02:59:04Z”,
“leaderCount”: 2,
“podName”: “pre-test-tikv-2”,
“state”: “Down”
},
“72180”: {
“id”: “72180”,
“ip”: “pre-test-tikv-3.pre-test-tikv-peer.tidb-cluster.svc”,
“lastTransitionTime”: “2022-12-12T04:03:59Z”,
“leaderCount”: 0,
“podName”: “pre-test-tikv-3”,
“state”: “Up”
},
“72223”: {
“id”: “72223”,
“ip”: “pre-test-tikv-4.pre-test-tikv-peer.tidb-cluster.svc”,
“lastTransitionTime”: “2022-12-12T04:03:59Z”,
“leaderCount”: 0,
“podName”: “pre-test-tikv-4”,
“state”: “Up”
}
},
“synced”: true,
“tombstoneStores”: {
“79736”: {
“id”: “79736”,
“ip”: “pre-test-tikv-5.pre-test-tikv-peer.tidb-cluster.svc”,
“lastTransitionTime”: null,
“leaderCount”: 0,
“podName”: “pre-test-tikv-5”,
“state”: “Tombstone”
}
},
“volumes”: {
“tikv”: {
“boundCount”: 5,
“currentCapacity”: “110Gi”,
“currentCount”: 5,
“name”: “tikv”,
“resizedCapacity”: “110Gi”,
“resizedCount”: 5
}
}
}
}
}
日志
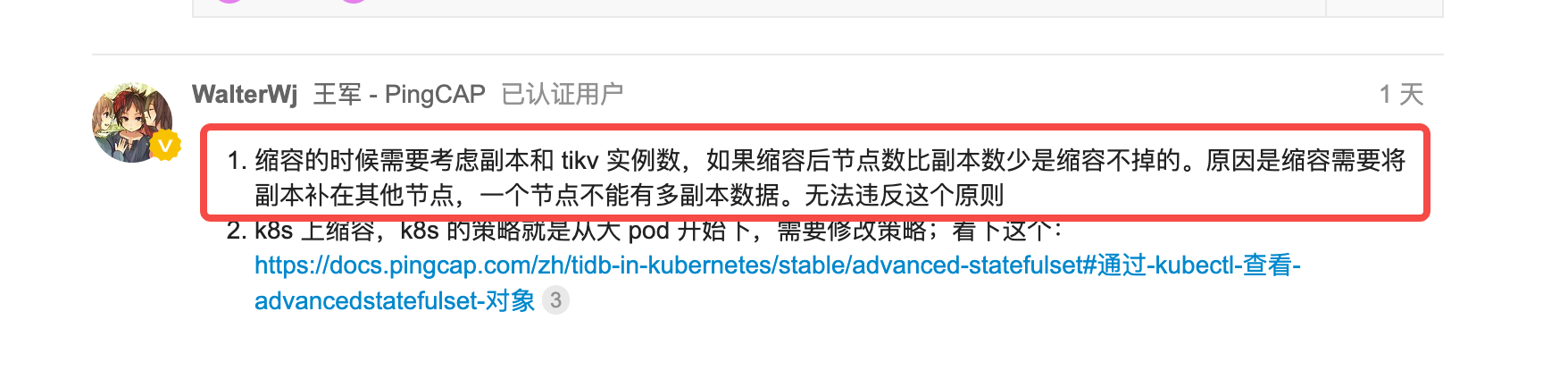
I1213 07:29:34.989188 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:34.997998 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:34.998262 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46472491”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.724813 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:45.732652 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.732806 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46472491”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.754481 1 tidbcluster_control.go:69] TidbCluster: [tidb-cluster/pre-test] updated successfully
I1213 07:29:45.865868 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:45.875868 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:45.876047 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46474051”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.843729 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:51.851744 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.852085 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46474051”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.869532 1 tidbcluster_control.go:69] TidbCluster: [tidb-cluster/pre-test] updated successfully
I1213 07:29:51.965092 1 tikv_scaler.go:90] scaling in tikv statefulset tidb-cluster/pre-test-tikv, ordinal: 4 (replicas: 4, delete slots: )
E1213 07:29:51.972914 1 tikv_scaler.go:250] can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
I1213 07:29:51.973294 1 event.go:282] Event(v1.ObjectReference{Kind:“TidbCluster”, Namespace:“tidb-cluster”, Name:“pre-test”, UID:“b249cfb6-8ad0-4c50-897e-d21c0acee6f3”, APIVersion:“pingcap.com/v1alpha1”, ResourceVersion:“46474101”, FieldPath:“”}): type: ‘Warning’ reason: ‘FailedScaleIn’ can’t scale in TiKV of TidbCluster [tidb-cluster/pre-test], cause the number of up stores is equal to MaxReplicas in PD configuration(3), and the store in Pod pre-test-tikv-4 which is going to be deleted is up too
版本号:1.3.9