【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.4
【遇到的问题:问题现象及影响】
原始需求:主动暂停ticdc 同步任务changefeed时,发出告警。
问题:
查看grafana中有一个dashboard 显示“changefeed status”,但是没数据,查询mertics也没数据。
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.0.4
【遇到的问题:问题现象及影响】
原始需求:主动暂停ticdc 同步任务changefeed时,发出告警。
问题:
查看grafana中有一个dashboard 显示“changefeed status”,但是没数据,查询mertics也没数据。
看一下 Prometheus 里面有没有数据,prometheus 默认平台端口是 9090。
感谢回复:
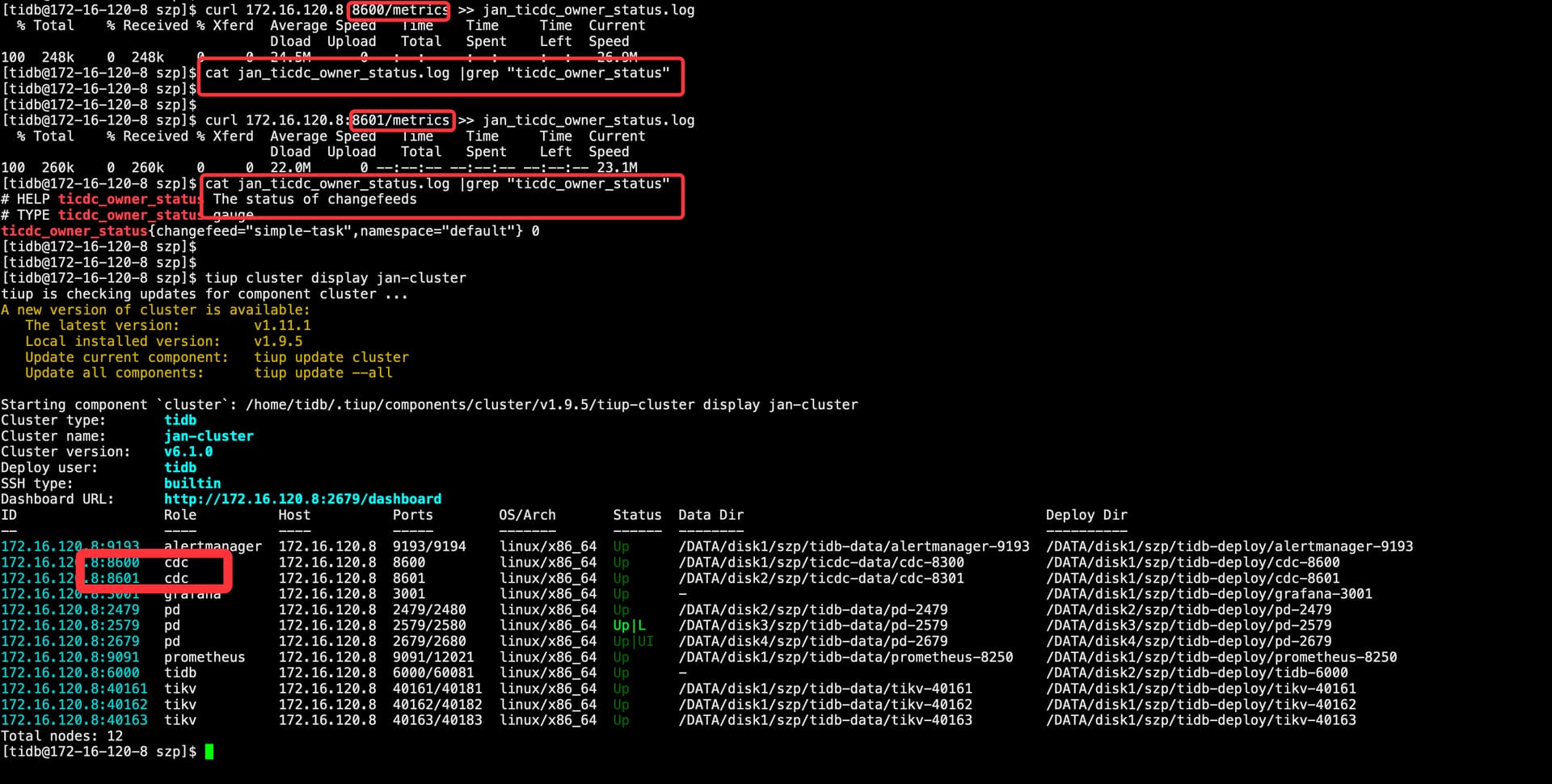
promehtues 中没有指标 ticdc_owner_status
curl curl -i http://127.0.0.1:8300/metrics |grep ticdc_owner_status
有其他办法定制cdc告警规则查看changefeed 状态么
你好,

只有是 owner 的 capture 才会打该指标,随机找一个 capture 可能不是 capture owner。 所以这么看不一定有价值,至于 owner 的定义可以看下 → 专栏 - TiCDC系列分享-02-剖析同步模型与基本架构 | TiDB 社区
我觉得这块不太可能出问题,如果出了问题说明 同步功能 大概率出了问题。
curl 172.16.0.1:8300/metrics
curl 172.16.0.2:8300/metrics
[2022/12/08 00:31:29.256 +08:00] [ERROR] [owner.go:1354] ["watch owner campaign key failed, restart the watcher"] [error="etcdserver: mvcc: required revision has been compac
ted"]
[2022/12/08 00:31:29.288 +08:00] [WARN] [owner.go:1726] ["watch capture returned"] [error="[CDC:ErrOwnerEtcdWatch]etcdserver: mvcc: required revision has been compacted"] [errorVerbose="[CDC:ErrOwnerEtcdWatch]etcdserver: mvcc: required revision has been compacted\ngithub.com/pingcap/errors.AddStack\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/errors.go:174\ngithub.com/pingcap/errors.(*Error).GenWithStackByCause\n\tgithub.com/pingcap/errors@v0.11.5-0.20201126102027-b0a155152ca3/normalize.go:279\ngithub.com/pingcap/ticdc/pkg/errors.WrapError\n\tgithub.com/pingcap/ticdc@/pkg/errors/helper.go:30\ngithub.com/pingcap/ticdc/cdc.(*Owner).watchCapture\n\tgithub.com/pingcap/ticdc@/cdc/owner.go:1636\ngithub.com/pingcap/ticdc/cdc.(*Owner).startCaptureWatcher.func1\n\tgithub.com/pingcap/ticdc@/cdc/owner.go:1713\nruntime.goexit\n\truntime/asm_amd64.s:1357"]
ErrEventFeedEventError 应该按理说不会干扰 Owenr 选举,监控中显示当前的 Owenr 是哪个 Capture?
方便上传下 TiCDC 面板和 Owner 日志吗(最近一段时间的)?
综上,目前建议,重启下所有 capture 看看是否能恢复,感觉重启下就好了。
另外:
大佬,capture 怎么重启?tiup cluster restart cluster_name -R cdc?
重启capture有什么影响么?
其实影响不大,重启之后 Capture 和 tikv 之间的连接会重连,会有一定开销(为每个 Region 重新构建 connect stream)。
这个过程中,同步进度会受到一定影响,其他方面还好,找业务低峰期重启吧。
线下环境单节点重启Capture后,没有ticdc_owner_status 指标。
我再想想其他办法。
通过python脚本完成capture监控
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。