【 TiDB 使用环境】生产环境
【 TiDB 版本】49
【复现路径】未复现
【遇到的问题:问题现象及影响】
TiDB节点有配置开启 ignore-error ,集群共有三个TiDB节点,有两个节点触发 critical error 告警 ,后续不再写入binlog。
将写 binlog 失败的 tidb节点 reload 之后恢复 binlog 的写入,我们该怎么确认是因为什么操作导致tidb无法写入binlog失败触发critical error的?
参考:
https://docs.pingcap.com/zh/tidb/v4.0/alert-rules#tidb_server_event_error 里面介绍的是 (目前只有 Binlog 写不进去一种情况),这里的写不进入指的是TiDB磁盘满了导致无法写入Binlog还是因为Drainer节点同步到下游的时候出现报错导致的?
【资源配置】
线上TiDB集群
【附件:截图/日志/监控】

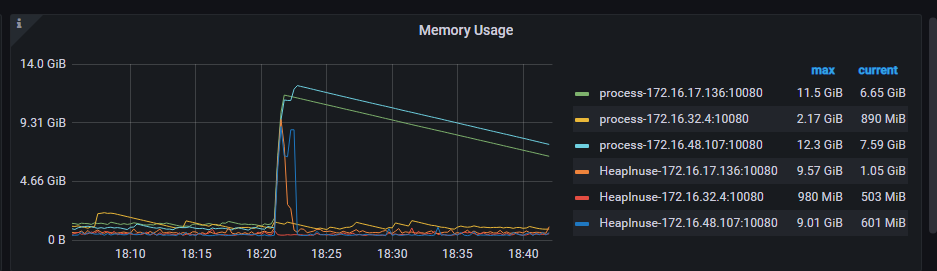
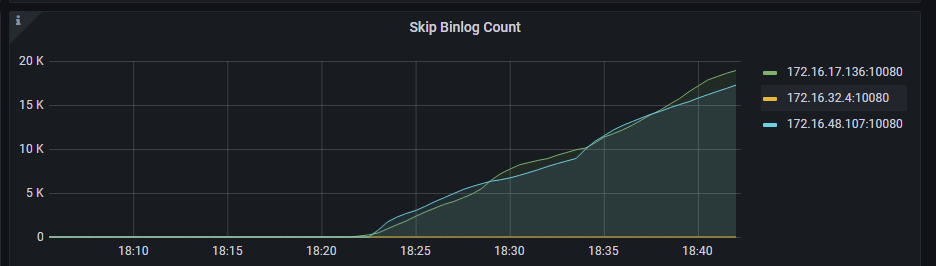
看对应的tidb.log文件里有没有相应报错
具体查到的日志是[WARN]级别的日志里面有提示binlog写入失败:
[2022/11/11 18:22:06.116 +08:00] [INFO] [region_cache.go:839] ["switch region leader to specific leader due to kv return NotLeader"] [regionID=1133841] [currIdx=2] [leaderStoreID=4]
[2022/11/11 18:22:06.635 +08:00] [INFO] [client.go:570] ["[pumps client] write detect binlog to unavailable pump success"] [NodeID=172.16.17.53:8250]
[2022/11/11 18:22:06.636 +08:00] [WARN] [client.go:573] ["[pumps client] write detect binlog to pump failed"] [NodeID=172.16.32.16:8250] [error="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial tcp 172.16.32.16:8250: connect: connection refused\""]
[2022/11/11 18:22:06.636 +08:00] [INFO] [client.go:397] ["[pumps client] set pump available"] [NodeID=172.16.17.53:8250] [available=true]
[2022/11/11 18:22:07.336 +08:00] [INFO] [gc_worker.go:237] ["[gc worker] there's already a gc job running, skipped"] ["leaderTick on"=610a90fcf340091]
所以可以确认是网络问题导致的对吧?
看着像网络问题
明白怎么去排查确认了,感谢~
你这个 skip binlog count 还在持续的增长啊。
你需要处理一下。
对binlog进行recover,curl http://{TiDBIP}:10080/binlog/recover
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。