【 TiDB 使用环境】生产环境
【 TiDB 版本】3.0.19
【遇到的问题:问题现象及影响】
早上5点多收到告警,显示一个集群的所有pd-server集体失联,尝试重启集群(失败)和重启服务器都无用。
【资源配置】48c189m物理机,3节点pd集群。
【附件:截图/日志/监控】
早5:08左右,leader发生选举,选举后pd_PD_6依然为leader:
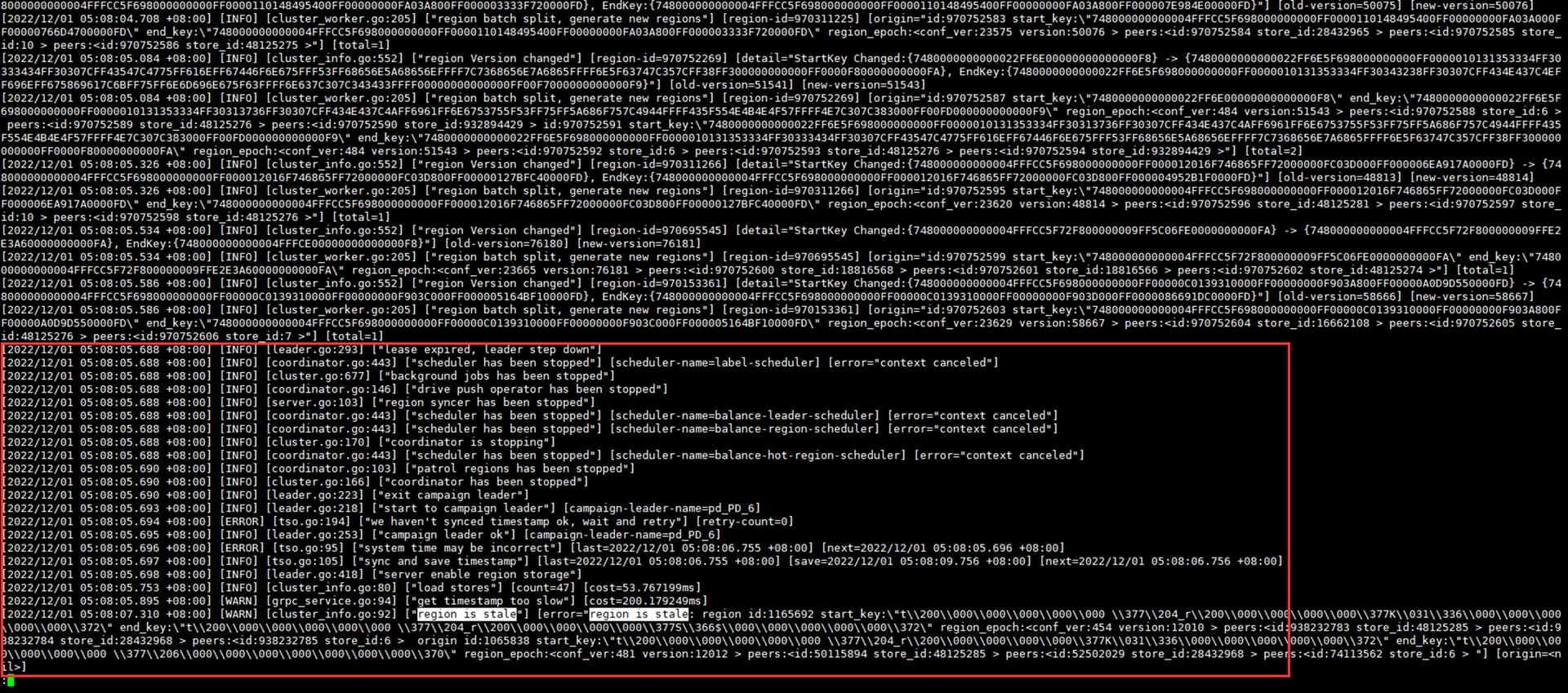
随后发生长约51min37s的load region流程,直到此流程完毕集群才恢复(5:08-6:58包含:故障发生->收到告警->告警处理->最终恢复 的全部时间,期间有重启集群和服务器的操作):
load region过程中日志全部是上图中的“region is stale”报错。
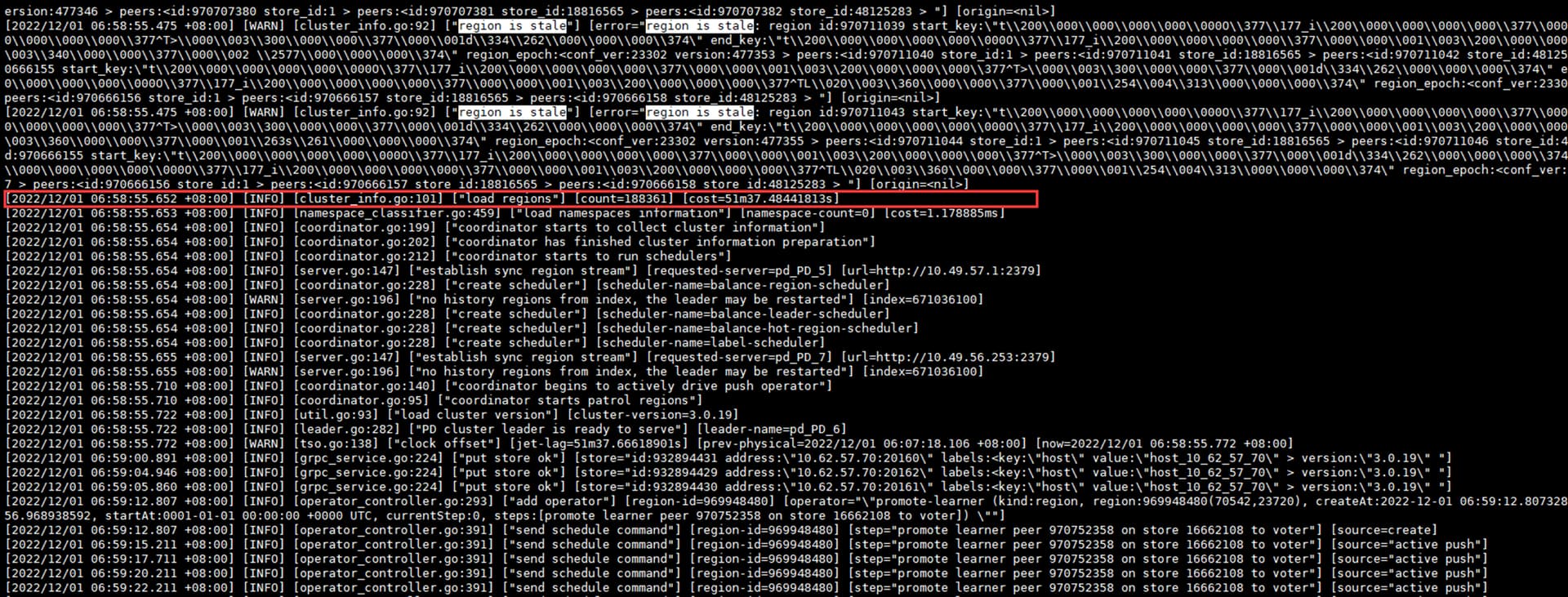
初步怀疑是时间同步问题导致的BUG,现在问题有3:
-
问题是否由时间同步问题引发?如果不是还可能是什么原因?需要什么其他资料探寻?
-
如果是时间同步问题那么3.0.19之后的版本是否有修复?(因为时间不同步这种事情总会发生,即便有时间同步服务存在)
-
region很多时load region的流程过长,之后的版本是否有优化?
之后尝试进行版本升级,重启pd过程中依然会出现长时间的load region导致重启pd失败,目前只能等load完毕后再次尝试一下,集群处于不可用状态。
问题:
4. 现在如何实现平滑升级,以往的3.0.19升级并未遇到此类超长load耗时。