Jolyne
1
【 TiDB 使用环境】生产环境 /测试/ Poc
生产环境
【 TiDB 版本】
5.2.1
【复现路径】做过哪些操作出现的问题
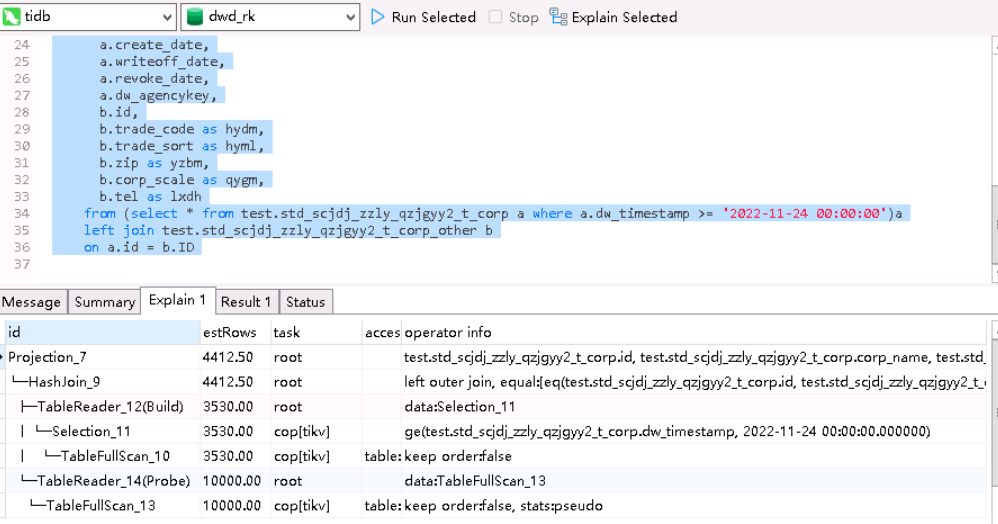
tidb的sql执行计划是与mysql不一样么,写了两种不同写法,发现执行计划是一样的,查询速度却不一样,想问下是为什么。
这是mysql执行计划的顺序
【遇到的问题:问题现象及影响】
【资源配置】
【附件:截图/日志/监控】
h5n1
(H5n1)
2
explain analyze的执行计划贴全些吧。
我是咖啡哥
4
stats:pseudo 统计信息可能不准。用一楼说的方式:explain analyze 输出执行计划
h5n1
(H5n1)
5
explain analyze 不是explain
h5n1
(H5n1)
7
能否放到文本文档里,想看下execution/operator info的具体差异
Jiawei
(渔不是鱼)
8
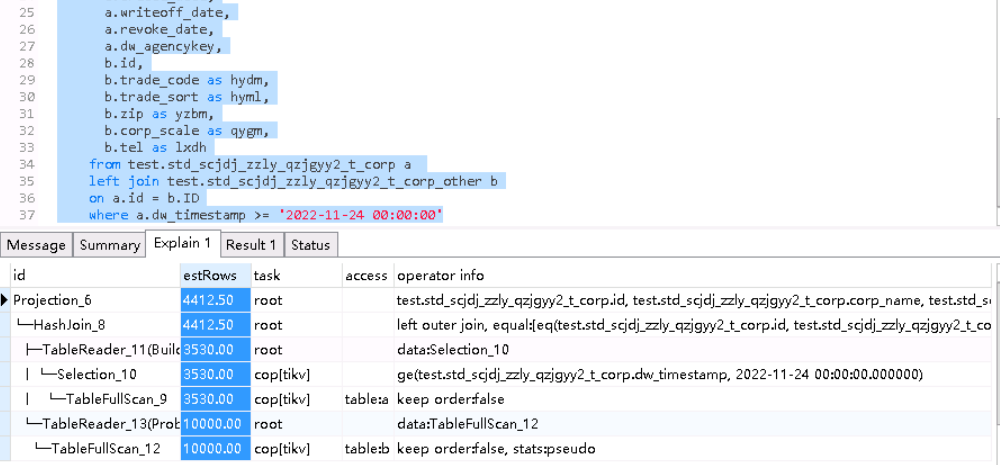
我猜测是不是tidb优化器做了优化,对于第二种方式,先把where条件加入减少left join 左表数量,来减少表left join的成本。
Jolyne
9
1.xls (11 KB)
2.xls (11.5 KB)
Kongdom
(Kongdom)
10
看见有stats:pseudo,直接对表做analyze就可以了
h5n1
(H5n1)
11
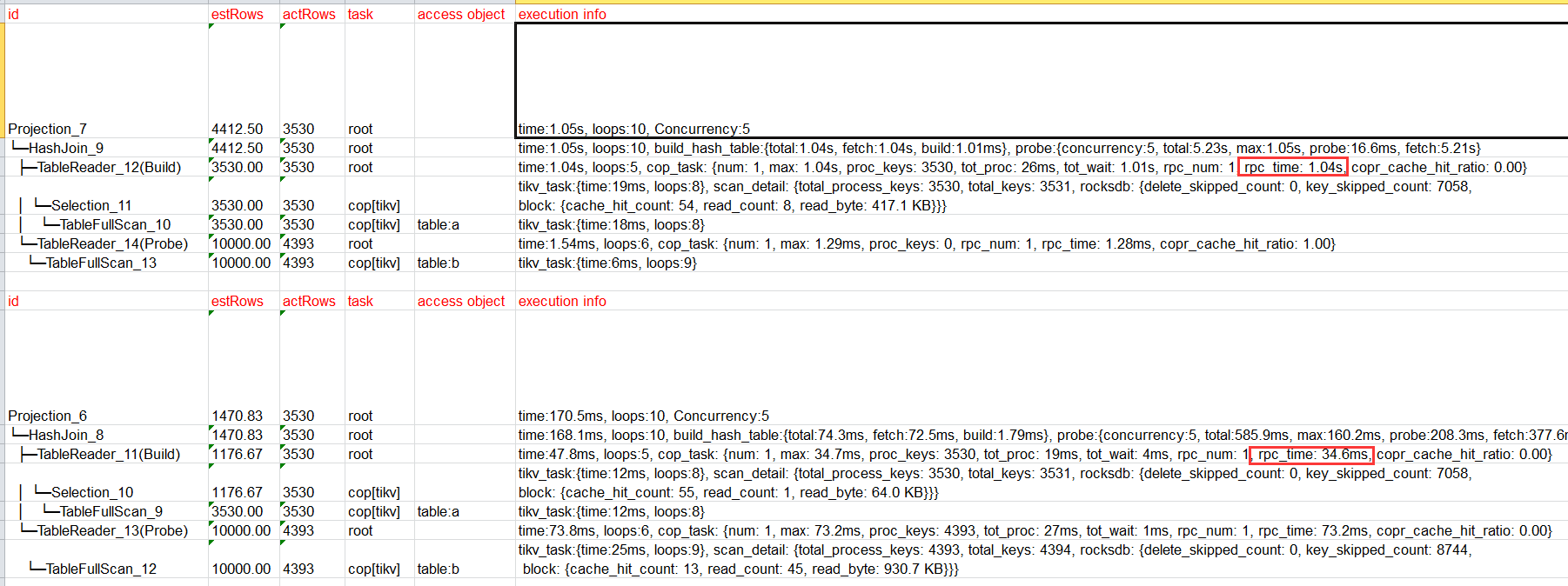
看着2个计划rpc时间有差异,每次都是先执行第1个慢SQL 然后执行第二个吗,第一个慢的SQL 第二次执行也是慢的吗? 你那还有其他tidb的环境不,把2个表数据导进去试试其他环境执行结果。
Jolyne
14
有缓存了,查询都快。有可能是楼上所说的tidb内部先把where条件加入减少left join 左表数量,来减少表left join的成本。
h5n1
(H5n1)
15
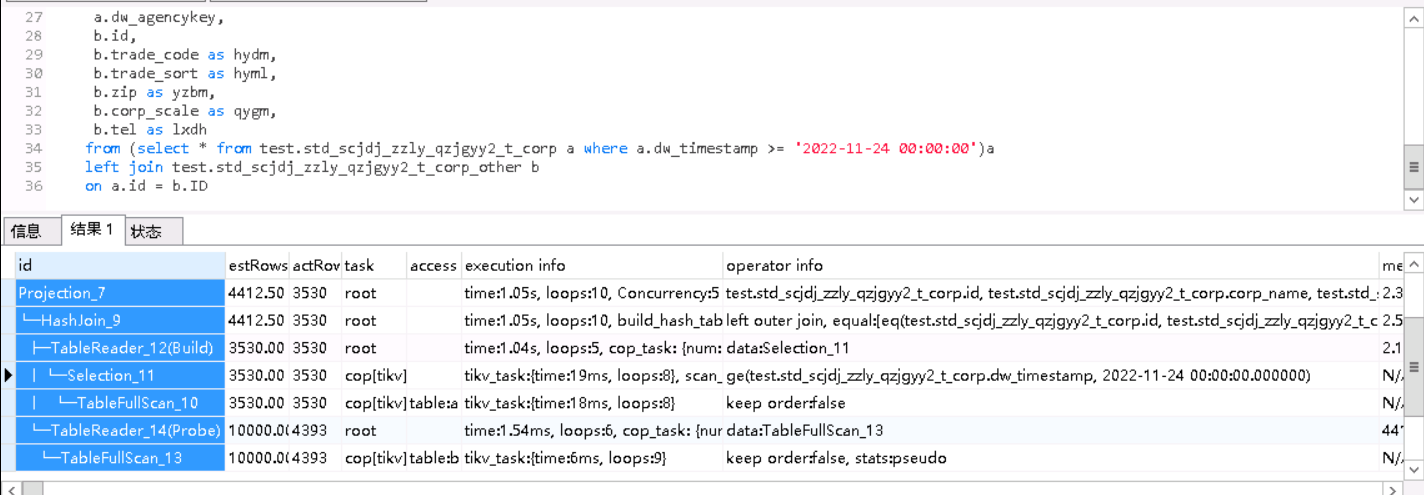
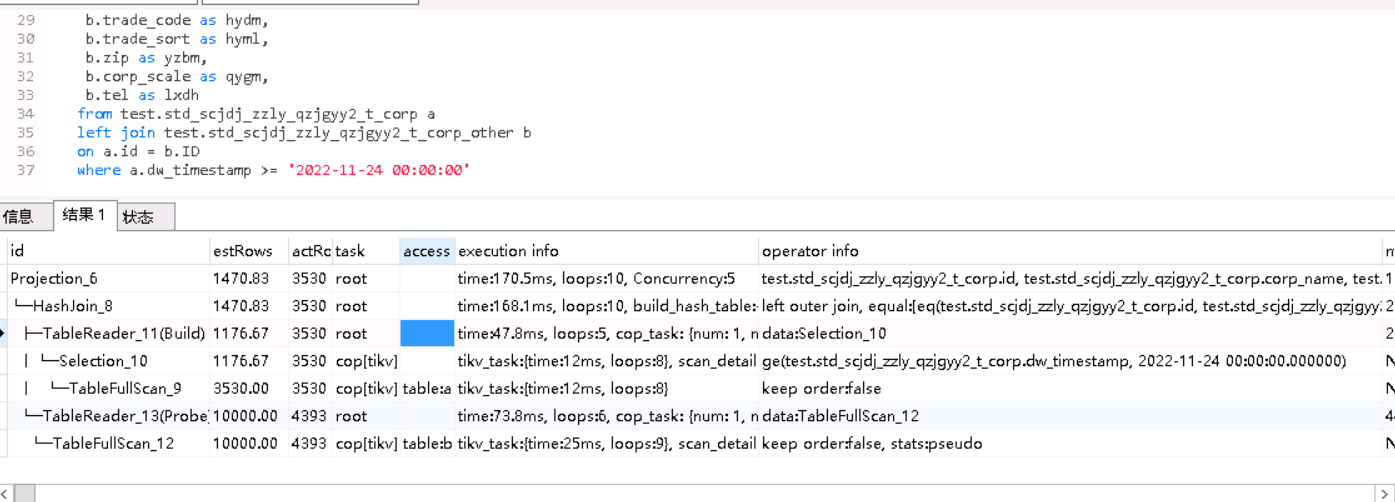
2个执行计划里相同算子的actrows 扫描key的数量是一样的
Aric
(Jansu Dev)
16
+1, 跟 join 关系不大,主要问题在 rpc_time 上;
- rpc_time 表示 “向 TiKV 发送 Cop 类型的 RPC 请求总时间”, 在 tikv-client go 中记录 runtime 信息合并而来;
- rpc_num 表示 “同上 RPC 请求个数”;
- rocksdb: {delete_skip_count …} : 源自 protobuf,是 tikv 传过来的 → 详见定义
- tikv_task: {time …} 也是 tikv 传过来的,–> 详见定义
- 这个问题又只有 1 个 rpc_num,说明同样是一个请求,在 tikv 执行 task 的时候时快时慢;
一般这种问题有 2 种可能:
- 时间耗在 网络抖动上
- 属于长尾情况,大部分请求都在 ms 级,时不时蹦到 s 级,s 级的比例并不高,不改监控看不出来(p99,p999),但是从 rocksdb 相关信息看 tikv 回传信息对应点位 不太可能慢在 tikv 处理流程。 也就是说,慢在 grpc request end + network + grpc response end。 要么是 rust grpc 慢了(概率低),要么是 tikv grpc goroutine 慢了(概率低),要么是网络抖了。
感觉这种情况应该占比 该 SQL 总执行次数比重不大吧?
- 网络抖 看 ping latency
- 如果要细查 grpc request end 和 grpc response end 执行情况,tikv 测可以看看 tikv-details → grpc 下面的面板,可能还要改下 分位数曲线,想看极端情况,把 99 线改 1 看极端情况。
- 如果能稳定复现的话,最好 trace 一下,这个同时观察 这 1 个 region 的 request 发给哪个 tikv 了,然后沿着请求链路的面板,看看是否有蛛丝马迹。
Aric
(Jansu Dev)
17
比如:在只有 1 个请求的静态环境下,用 TiDB → KV request → KV request duration 减去 TiKV Details → Grpc → grpc message duration 的时间,应该和 rpc_time 对应得上,但 生产 就比较负载。
可以先把以上信息,先查一遍。
system
(system)
关闭
18
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。