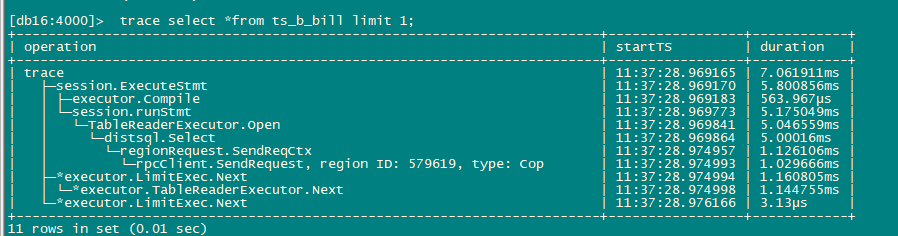
【问题】 测试环境,测试一张表Limit1操作,表中有2171个非index region,trace SQL发现首次执行时看着会将全量region信息进行load

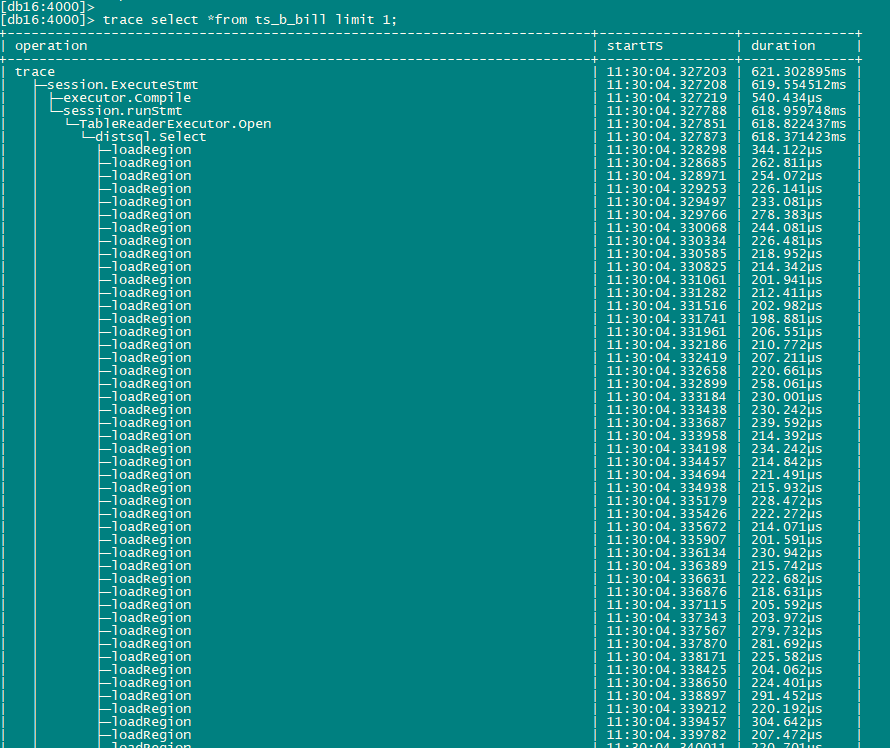
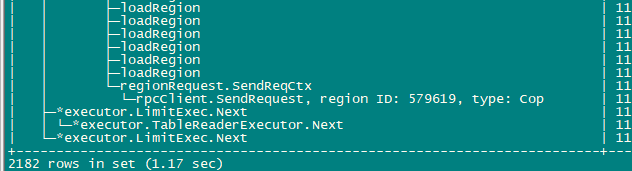
为什么limit 1时会load所有region信息,即使是 region cache里没有该表的region信息是不是 也只Load几个足够limit的region信息就够了?
第二次执行就不会Load了
【问题】 测试环境,测试一张表Limit1操作,表中有2171个非index region,trace SQL发现首次执行时看着会将全量region信息进行load
为什么limit 1时会load所有region信息,即使是 region cache里没有该表的region信息是不是 也只Load几个足够limit的region信息就够了?
第二次执行就不会Load了
![]()
就这一个region。
你可以把limit 去掉看看,这里就会显示很多region
调用链路 (大概):func Select → func (c *CopClient) Send → func buildCopTasks → SplitKeyRangesByLocations → LocateKey → findRegionByKey → loadRegion 调用点位
为什么limit 1时会load所有region信息,即使是 region cache里没有该表的region信息是不是 也只Load几个足够limit的region信息就够了?
a. region cache 信息会基于 函数中 传入的 ranges 操作,在这条 SQL 情况下 tableReader 算子的 ranges 是 table start_key + end_key ,也就造成了后面 load 这么多 key。
b. 不过,load 是个比较轻的操作,就是发 request 给 PD,也还好。
c. 其实如果想 少 loadregion,在 where 限制范围,手动改变构建算子时的扫描范围,在 regionCache 中内容过期后,应该也会少扫。
为什么第二次不 load 了?
在 findRegionByKey 中,先基于 CachedRegion 搜索,搜索不到才会真实 load。
像这种全表limit x是不是可以进行下优化,表比较大load region 耗时也有1秒多钟。可能实际业务这种场景不多,
晚上我提个 enhancement issue 吧,我只能尝试解释这种现象的原因,但具体要不要优化,怎么优化还要研发们考量。
晚些(版主会前):我把链接贴上来。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。