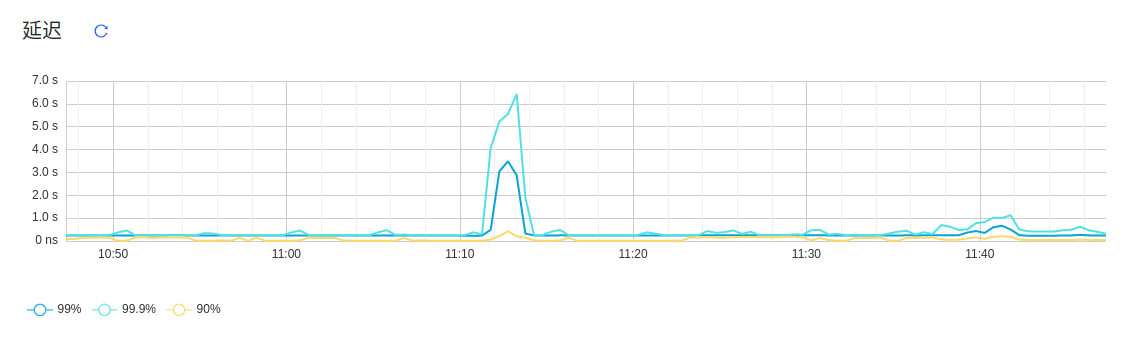
上周五早上 11点左右,在 dashboard 中发现集群的延迟比较高,99.9% 延迟为 6 s ,99% 请求的延迟为 3 s,
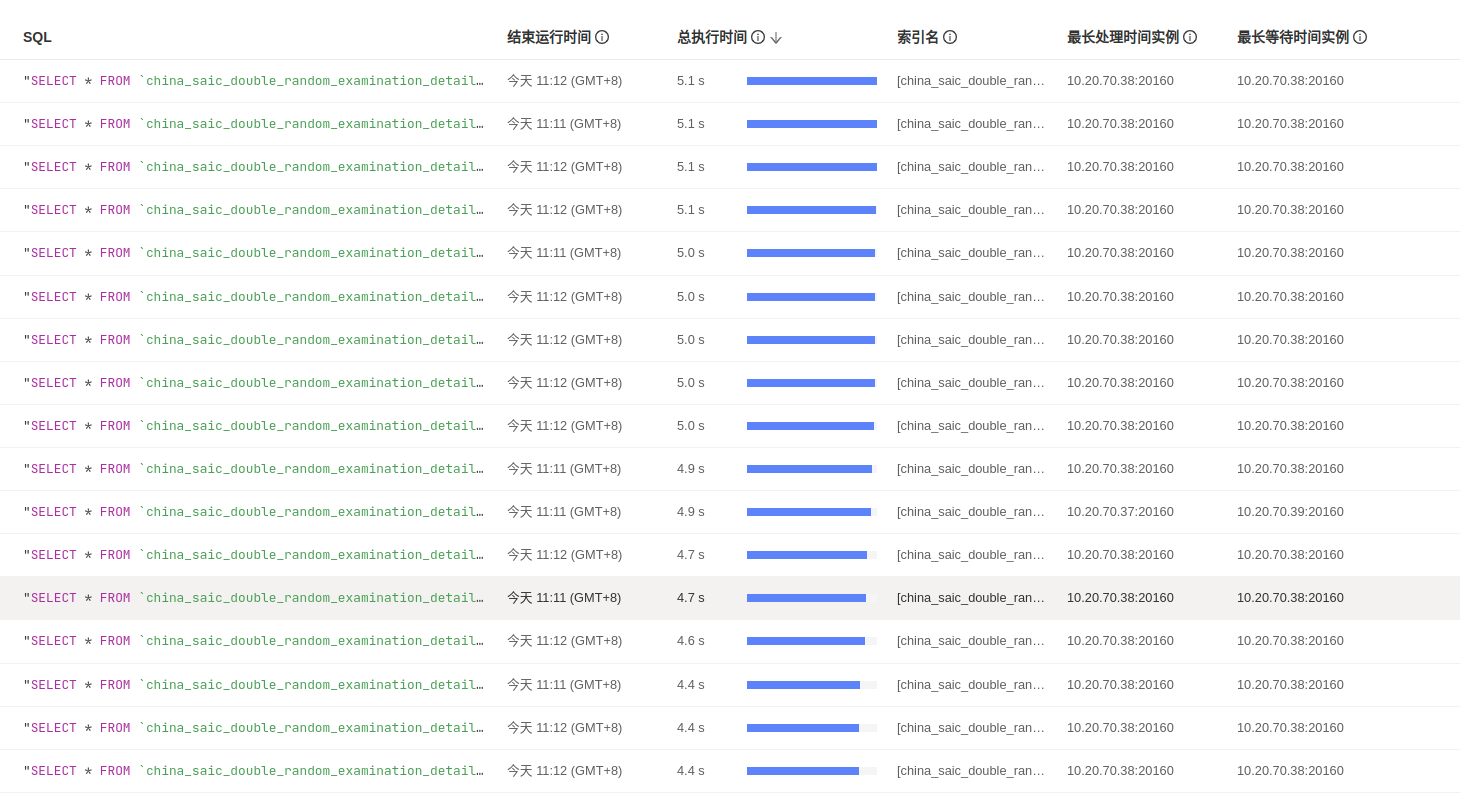
然后看了一下慢sql,发现是其中一个表的查询导致的,
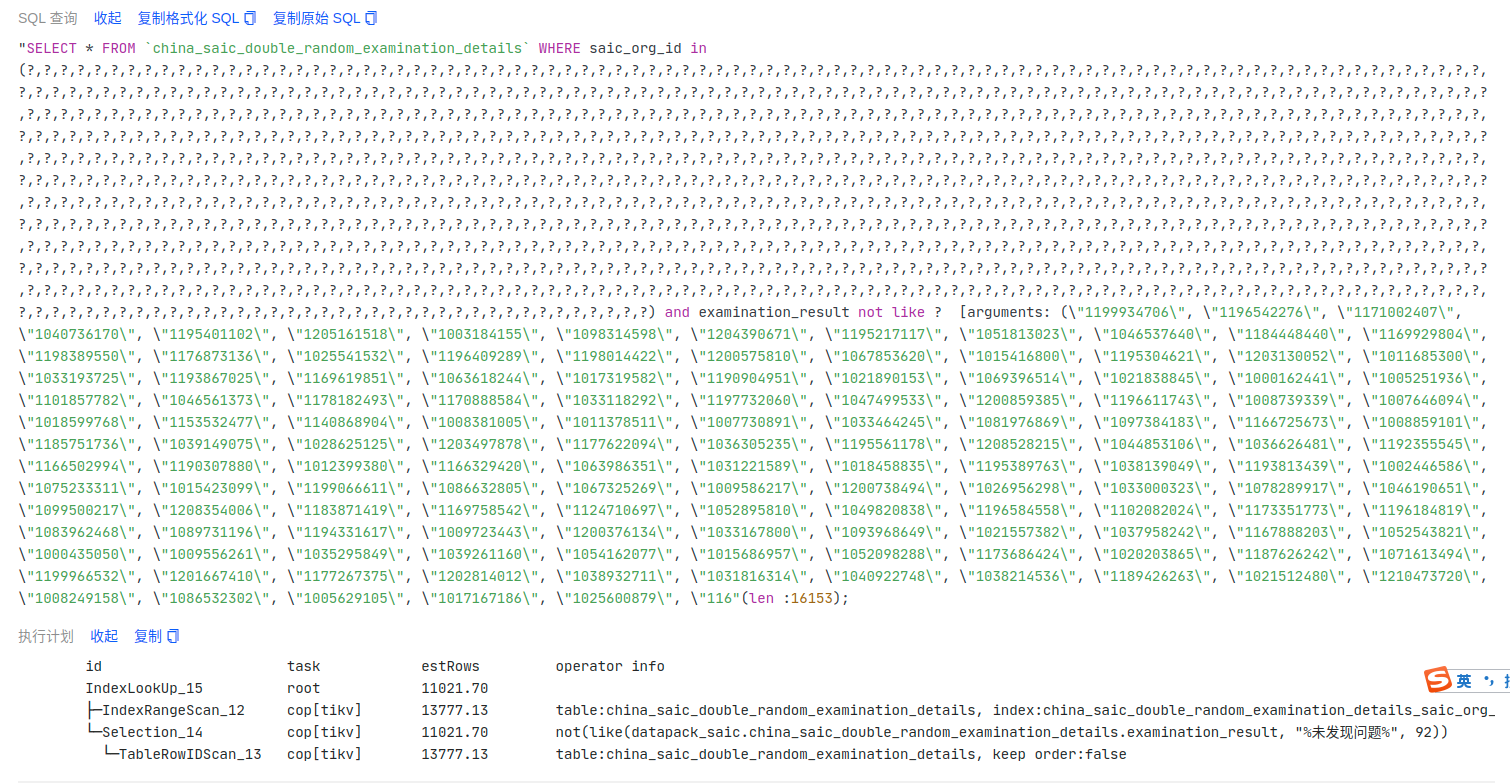
该 sql 很简单,就是一个普通的 IN 条件查询,通过 explain analyze 可以看到也是走了索引的。
详细的 explain analyze 信息
explain.txt (144.9 KB)
集群有 3 个 tikv ,3个 tidb, 3 个 pd ,通过 numa 解核混合部署的,其中 tikv 部署在 numa_node 0: 32 VCore 64 G, tidb 和 pd 一起部署在 numa_node 1: 32 VCore 64G,
之前也有发生过类似的,当大表(亿级)有大量的 IN 条件查询(查询的 ID 数量在 500 - 2000)时,系统的延迟都会比较高。
h5n1
(H5n1)
2
QPS、这个SQL的并发有增加吗? 看看慢的时候资源清理。系统正常后单独执行这个SQL速度怎么样
这条语句那个点并发高,cpu估计压力大,有延迟了。
现在单独执行的延迟是正常的
上周五这个时间段,集群的 qps 也是比较低的,不到 1k,但其中有比较多的 IN 条件查询,都是类似的 SQL
h5n1
(H5n1)
7
Jiawei
(渔不是鱼)
8
tidb dashboard上看下 慢sql到底是在哪个部分耗时最久了 ,然后根据对应的点去看对应模块的监控来定位下问题
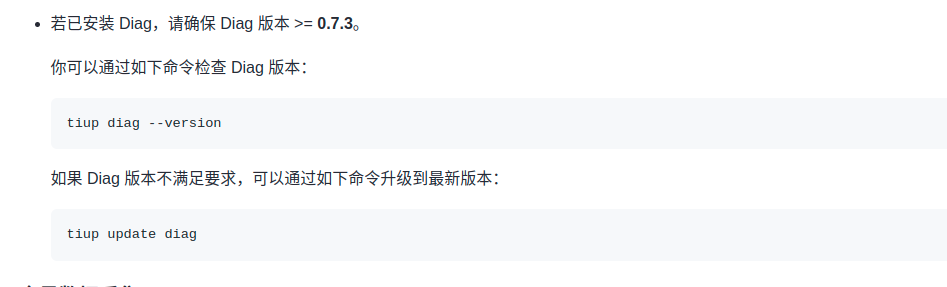
这边 diag 只能更新到 v.0.3.2, 文档中要求更新到 v0.7.3 , tiup 是离线安装的

这边的 tidb 集群是 v5.3.0 , 是不是需要升级后才能用 diag 客户端呀
Jiawei
(渔不是鱼)
12
tikv-details-coprocessor 看下异常 ,不过还是最好按照楼上的采集一下clinic信息,这样方便排查。
buddyyuan
(Buddyyuan)
13
tikv-details → Thread CPU 都看看。是不是到瓶颈了。
h5n1
(H5n1)
14
可以先试试你这个版本的能收集不: tiup diag collect -f 开始时间 -t 结束时间 。 不行就下一个高版本的tidb 离线包 然后 tiup mirror set /离线包目录 然后在更新diag(可能需要更新tiup)
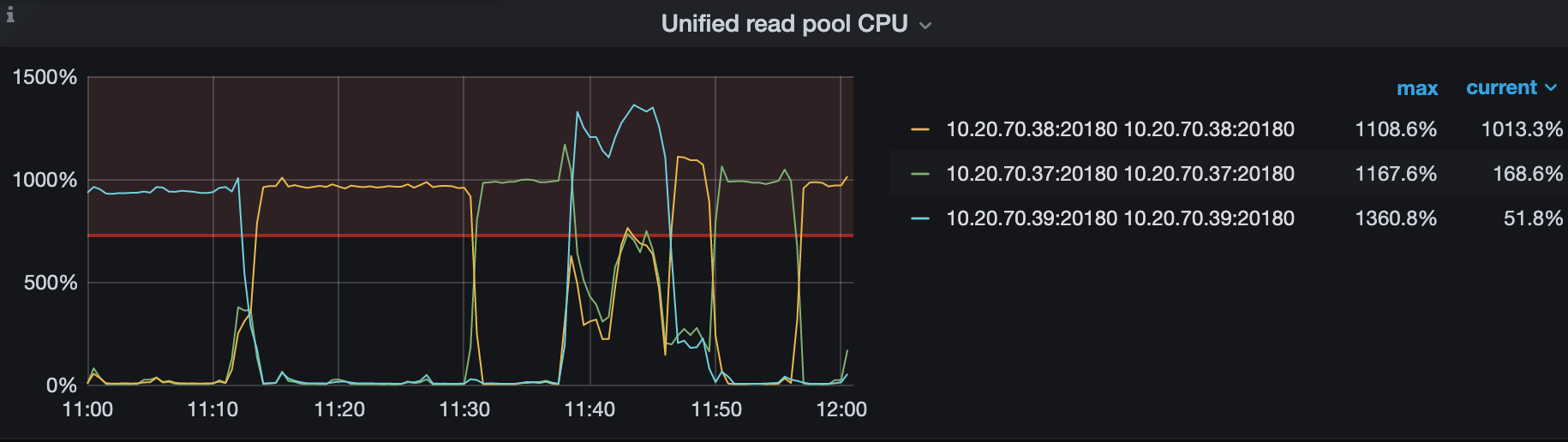
这个是最近 30 分钟的 Unified Read Pool 的 CPU ,发现很不平衡,某一台机器很高,其他两台机器很低,这个集群用 haproxy 做了负载均衡的
人如其名
(人如其名)
20
赞同,看那个慢SQL的执行信息,应该花费在排队等待上的时间比较多,应该排队在这里了。