explain analyze 之后的,estRows 和 actRows 差距大不大,如果很大的话,先解决表健康度的问题,在重新跑跑看
loops:19, index_task: {total_time: 8.89s, fetch_handle: 187.4ms, build: 391.9µs, wait: 8.7s}, table_task: {total_time: 45.5s, num: 213, concurrency: 5}
这个处理不是下推计算,直接是 tidb 循环了 19 次,通过index 找到行标识后,通过标识在获取的行记录
遍历了17315 条记录…
想要优化的话,得费点心思了
我先梳理梳理哈。
SQL:
FROM
history_wti_alarm AS h
LEFT JOIN
vehicle_profile AS p ON h.vehicle_id = p.id
LEFT JOIN
const_wti AS c ON h.wti_code = c.wti_code
WHERE
h.start_time >= '2022-11-01 00:00:00'
AND h.start_time < '2022-11-02 02:00:00'
AND h.alarm_tag = 0
ORDER BY h.start_time DESC
LIMIT 20;
主表history_wti_alarm 约18亿分区表。
满足条件的数据在p42分区,该分区6kw数据。
| remote_vehicle_prod | history_wti_alarm | p42 | 2022-11-25 10:37:23 | 12419 | 61910958 |
主表过滤后数据4169713。

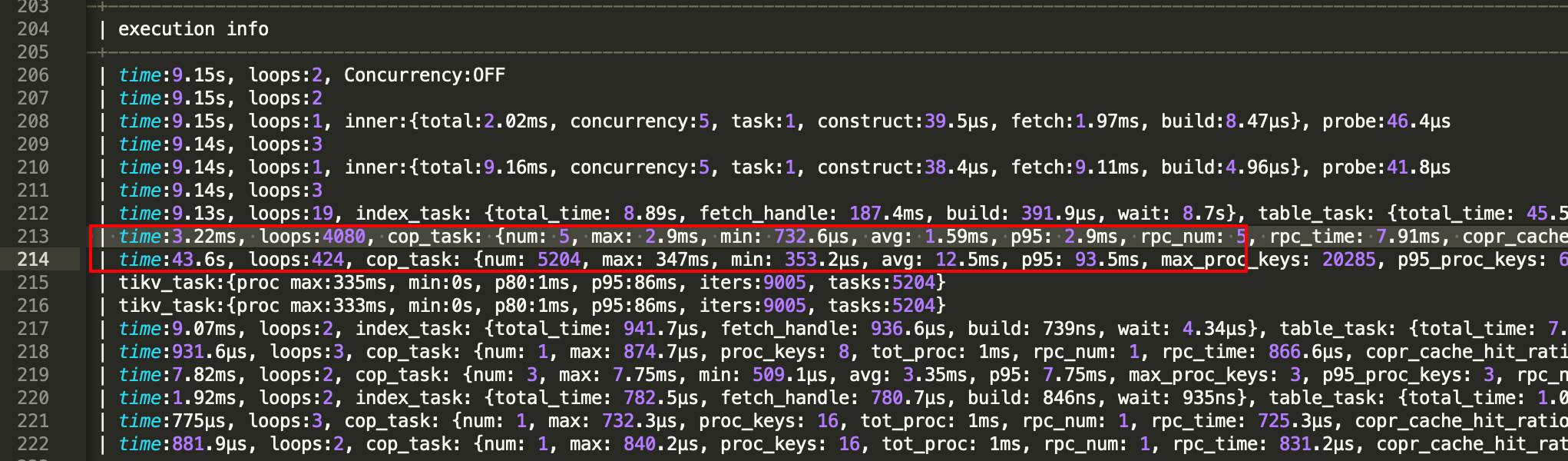
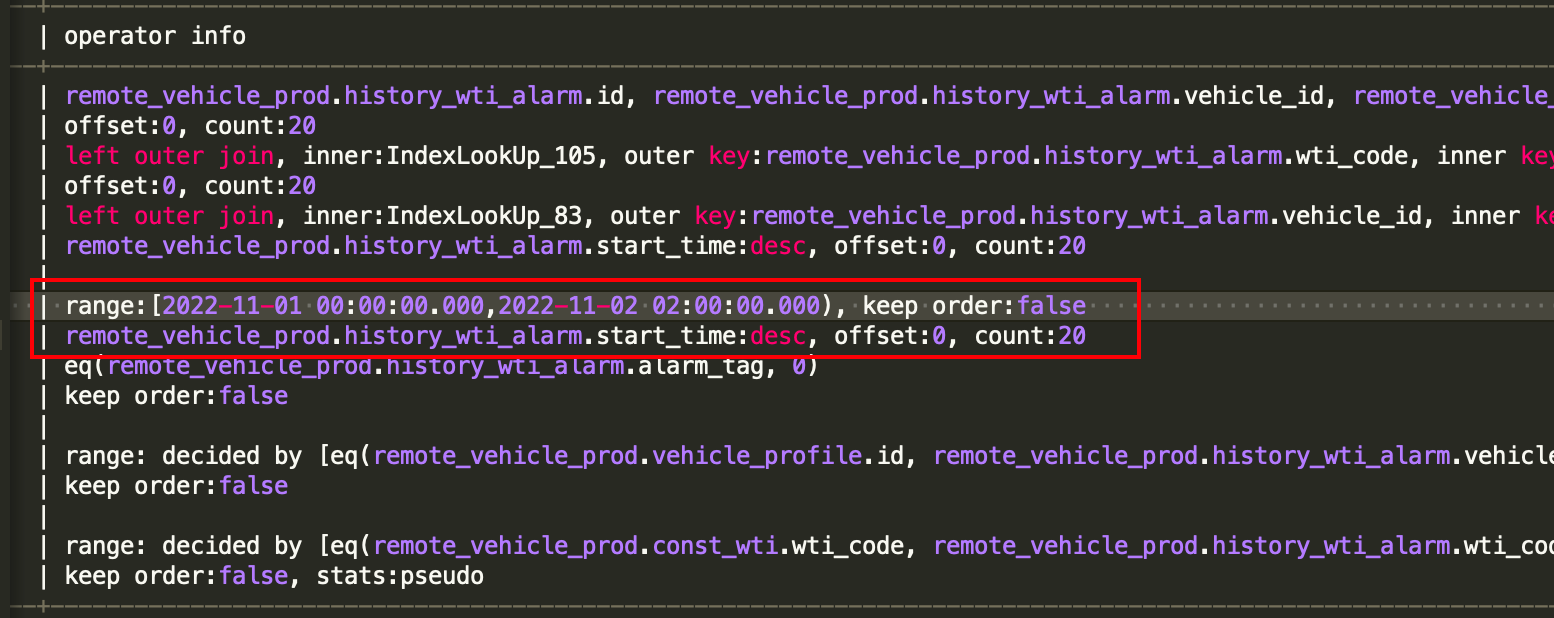
主要时间花费在根据时间过滤完数据后按时间排序,取20条。
└─TopN_99(Probe) | 20.00 | 17315
| cop[tikv] | time:43.6s, loops:424,
cop_task: {num: 5204, max: 347ms, min: 353.2µs, avg: 12.5ms, p95: 93.5ms, max_proc_keys: 20285, p95_proc_keys: 6771, tot_proc: 55.6s, tot_wait: 1.62s, rpc_num: 5204, rpc_time: 1m5s, copr_cache_hit_ratio: 0.00},
tikv_task:{proc max:337ms, min:0s, p80:1ms, p95:86ms, iters:9005, tasks:5204},
scan_detail: {total_process_keys: 4164712, total_process_keys_size: 1564260996, total_keys: 4374855,
rocksdb: {delete_skipped_count: 1, key_skipped_count: 3680023,
block: {cache_hit_count: 27810055, read_count: 2117, read_byte: 38.1 MB}}}
| remote_vehicle_prod.history_wti_alarm.start_time:desc, offset:0, count:20
另外一个问题,你这个建表SQL没发错的话,下面这两组索引不是重复了吗?
PRIMARY KEY (`alarm_id`,`start_time`) /*T![clustered_index] NONCLUSTERED */,
UNIQUE KEY `uniq_alarm_id` (`alarm_id`,`start_time`),
KEY `idx_start_time` (`start_time`),
KEY `idx_end_time` (`start_time`),
使用覆盖索引,过滤后的结果排序 效果会更理想一些吧
select 列很多,覆盖是覆盖不了。可以加个(alarm_tag,start_time)组合索引看看。
tidb现在好像不支持降序索引哈。不然可以这样建:
alter table history_wti_alarm add index idx01(alarm_tag,start_time desc);
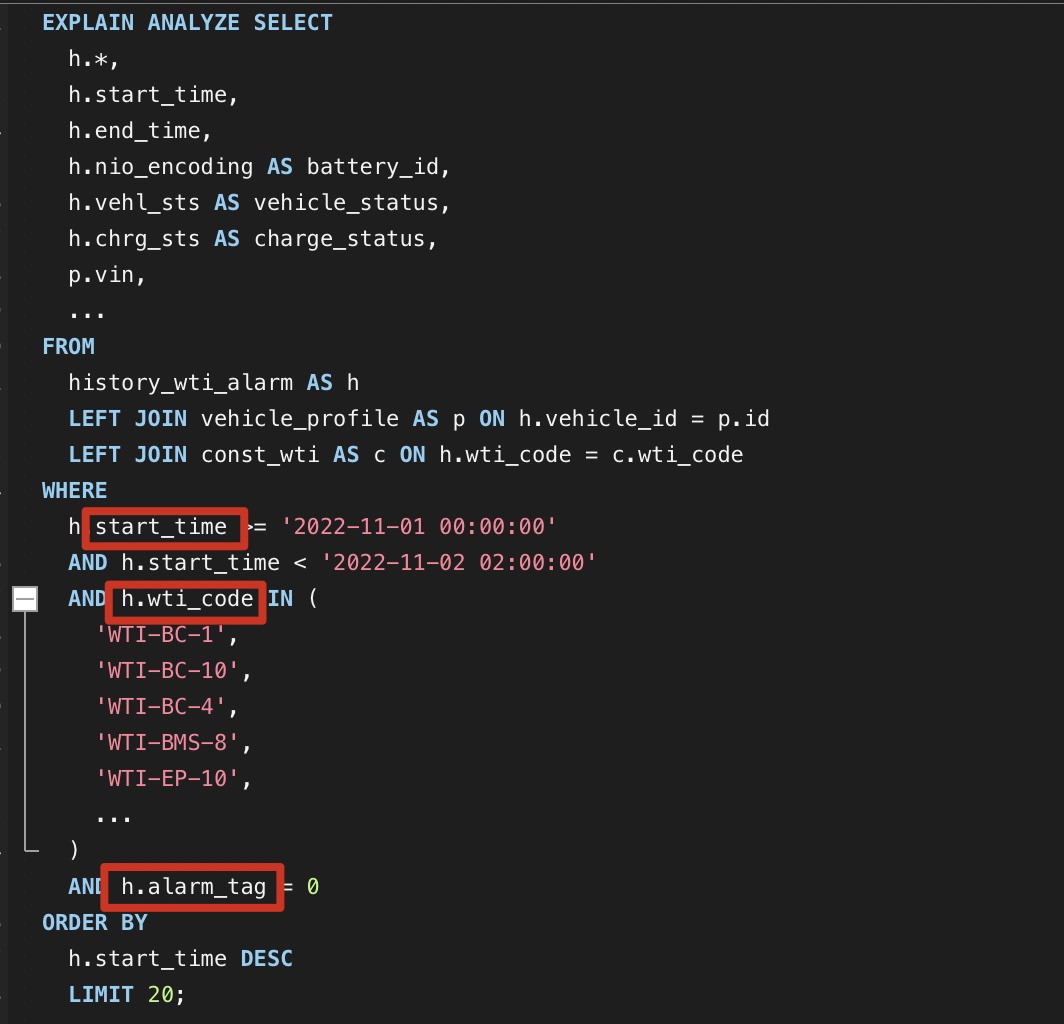
又加了个条件啊?之前发的没有code这个
大佬有什么优化的思路吗?
大佬,这里确实有点问题
大佬再指点下思路呗
优化方向还是有的:
-
优先获取结果后,在考虑 join
-
限定结果获取的范围,尽量命中索引
-
二级索引不如一级索引,效率上肯定 pointGet 和 batchGet 更高(点查)
-
id 是否是递增的,如果是,order By id 就可以了
- 最后的话,还可以拆分查询,让查询更有效
我的硬件在sql执行时,cpu ,内存都很空闲,有没有这一块的思路
上 tiflash 么? 可以考虑试试 ![]() 不知道效果怎么样
不知道效果怎么样
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。