qhd2004
(Qhd2004)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.4.1
【遇到的问题:问题现象及影响】
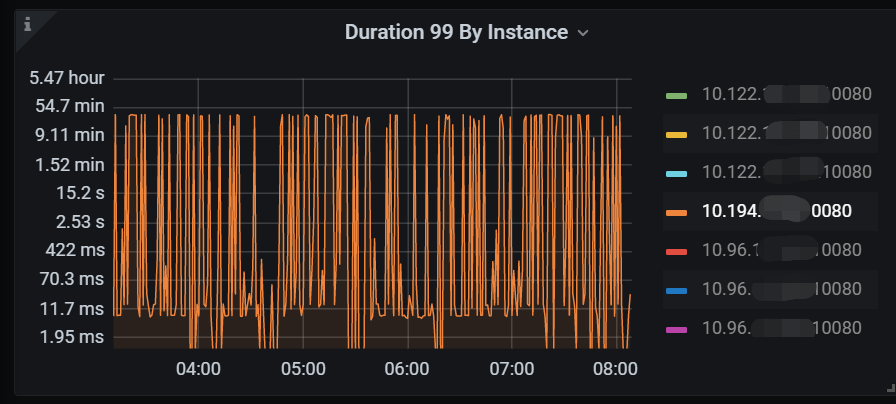
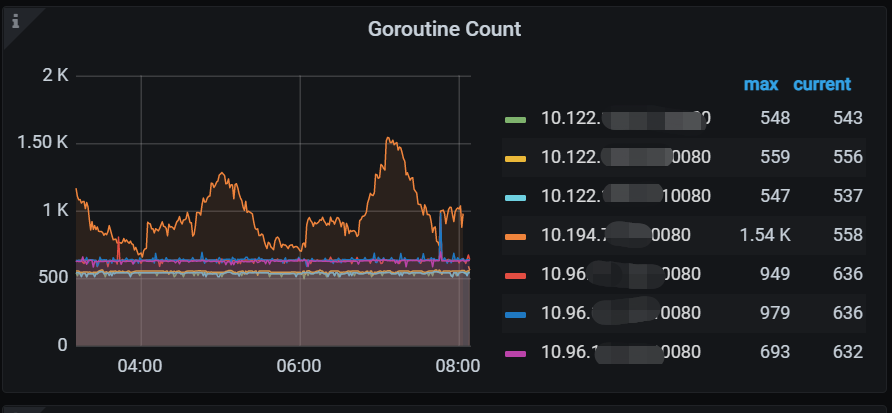
我们环境是两地三中心,北京两个机房,沈阳一个机房。现在是,在开发同事运行任务时,如果任务落到了北京的顺义机房,那顺义机房的tidb节点会hang住,只能是重启才可以。
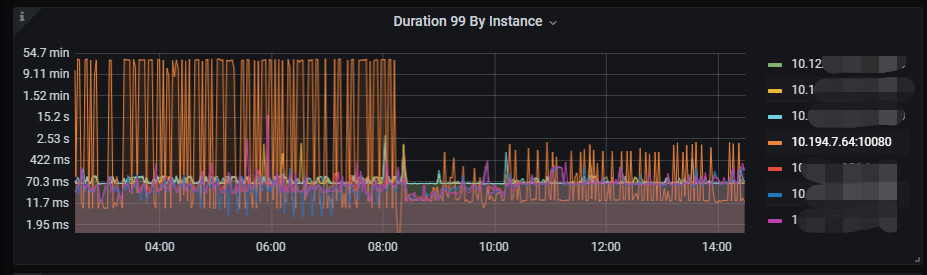
这个图中,10.122是沈阳,10.194是顺义,其中顺义这个节点的duration很高。
也是顺义这个节点高
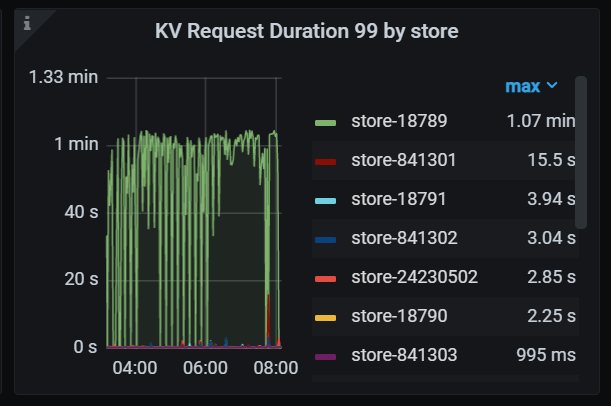
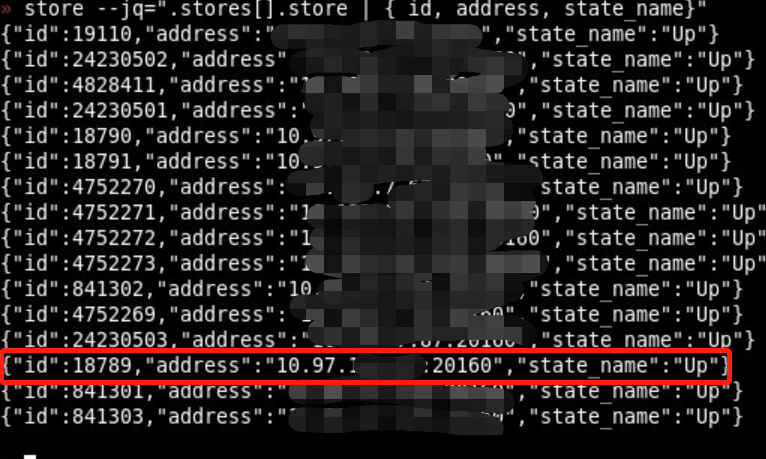
访问某个tikv节点duration超高,这个tikv节点在北京另一个机房
开发同事运行的任务我们做过一些优化:
大事务拆分
sql做了一些优化
对表的键进行了打散
请帮忙看看我们还可以从哪些方面入手?如果信息不全,我们还需要提供哪些信息?
谢谢各位。
【资源配置】
【附件:截图/日志/监控】
xfworld
(魔幻之翼)
2
收集下 tidb 节点的日志,特别是 hand住 前后的。 需要特别关注 slow query,以及内存 和 cpu 的消耗
另外可以针对 profile 做个快照,方便找到问题
觉得麻烦的话,也可以用官方的诊断工具
https://docs.pingcap.com/zh/tidb/stable/clinic-introduction
2 个赞
qhd2004
(Qhd2004)
3
此帖子长期有效,目前我们优化了一些sql后,问题有缓解。
谢谢各位!
qhd2004
(Qhd2004)
4
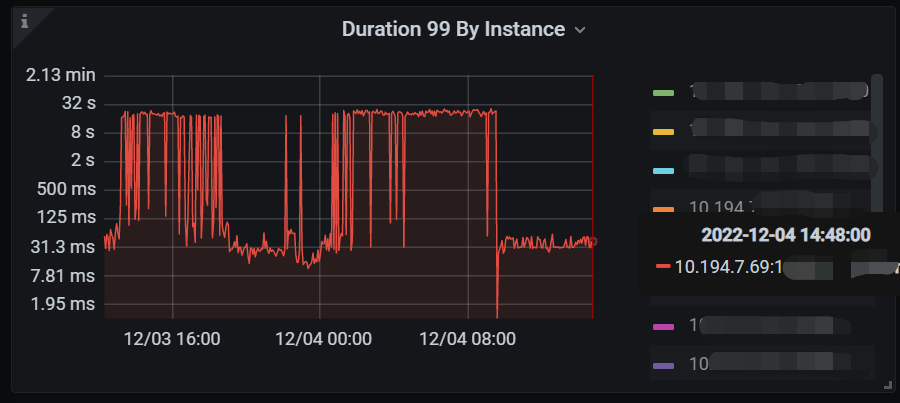
这两天又出现了某个tidb节点duration高,如下图
我把这个节点的tidb日志放附件
[tidb_log.tar.gz|attachment] (20.3 MB)
xfworld
(魔幻之翼)
7
我是咖啡哥
9
1 个赞
qhd2004
(Qhd2004)
10
pd的leader与region leader都在北京,并且也进行了相关参数调整,如下:
server_configs:
tidb:
binlog.enable: true
binlog.ignore-error: false
log.query-log-max-len: 12288
log.slow-threshold: 300
mem-quota-query: 524288000
new_collations_enabled_on_first_bootstrap: true
oom-action: cancel
performance.server-memory-quota: 17179869184
tikv:
readpool.coprocessor.use-unified-pool: true
readpool.storage.use-unified-pool: true
readpool.unified.max-thread-count: 10
server.concurrent-recv-snap-limit: 64
server.concurrent-send-snap-limit: 64
server.grpc-compression-type: gzip
server.grpc-keepalive-time: 120s
server.grpc-keepalive-timeout: 120s
server.grpc-raft-conn-num: 16
storage.block-cache.capacity: 40GB
pd:
label-property:
reject-leader:
- key: dc
value: shenyang
replication.enable-placement-rules: true
replication.isolation-level: zone
replication.location-labels:
- zone
- rack
- host
replication.max-replicas: 5
schedule.tolerant-size-ratio: 20.0
请问hang 住时候,内存占用情况什么样?另外检查一下 overcommit_memory=0 还是 1 ? 如果是设置 0 ,不会主动 kill 进程的,所以会hang
qhd2004
(Qhd2004)
12
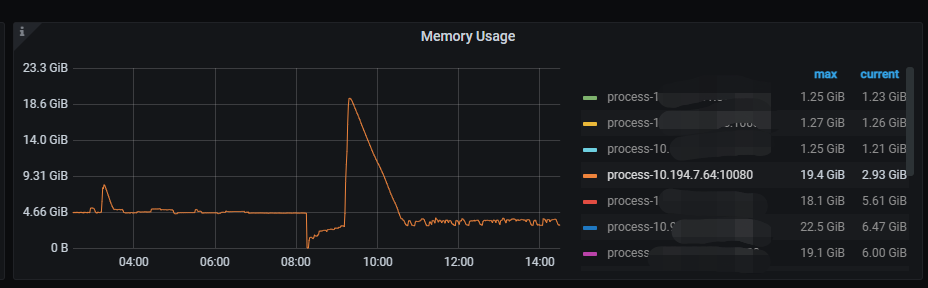
今天从04-08又出现了一次,从grafana上来看,内存并不高。
至于overcommit_memory参数我们没有配置,如下
[root@tidbolap-tidb06-194-7-64 ~]# grep ^[^#] /etc/sysctl.conf
net.ipv4.conf.all.accept_redirects = 0
net.ipv4.icmp_echo_ignore_broadcasts = 1
[root@tidbolap-tidb06-194-7-64 ~]#
附件是这个节点的tidb日志
[tidb_log_20221209.tar.gz|attachment] (7.5 MB)
system
(system)
关闭
13
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。