【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.9
【遇到的问题:问题现象及影响】
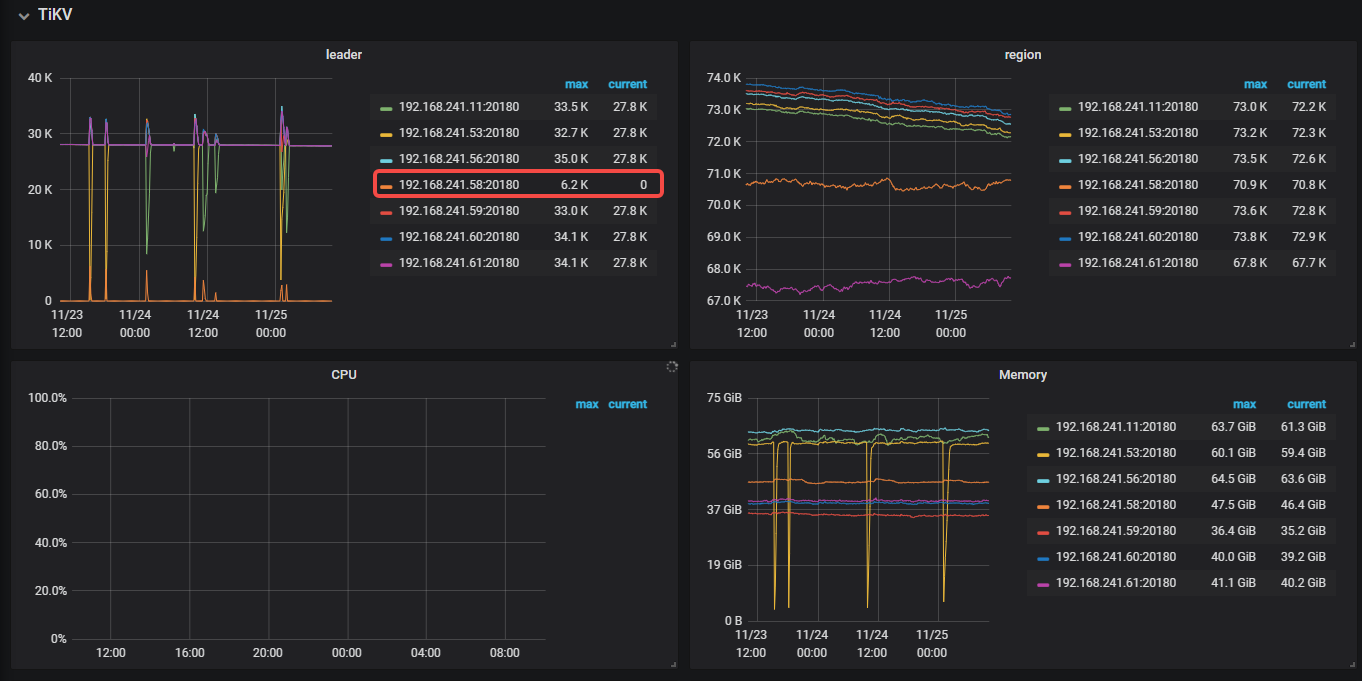
tikv节点192.168.241.58:20180 leader region频繁掉线(如下图,不知我描述的是否准确),请问这个情况是杂回事触发的呢?我看过系统日志,没发现啥异常的,谢谢~
这个tikv上的region数量在集群中不算少,但leader经常一直是0,偶尔增加一些leader很快就会下来。比较奇怪~
【资源配置】
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境
【 TiDB 版本】v4.0.9
【遇到的问题:问题现象及影响】
tikv节点192.168.241.58:20180 leader region频繁掉线(如下图,不知我描述的是否准确),请问这个情况是杂回事触发的呢?我看过系统日志,没发现啥异常的,谢谢~
这个tikv上的region数量在集群中不算少,但leader经常一直是0,偶尔增加一些leader很快就会下来。比较奇怪~
【资源配置】
【附件:截图/日志/监控】
应该放上这个节点的日志
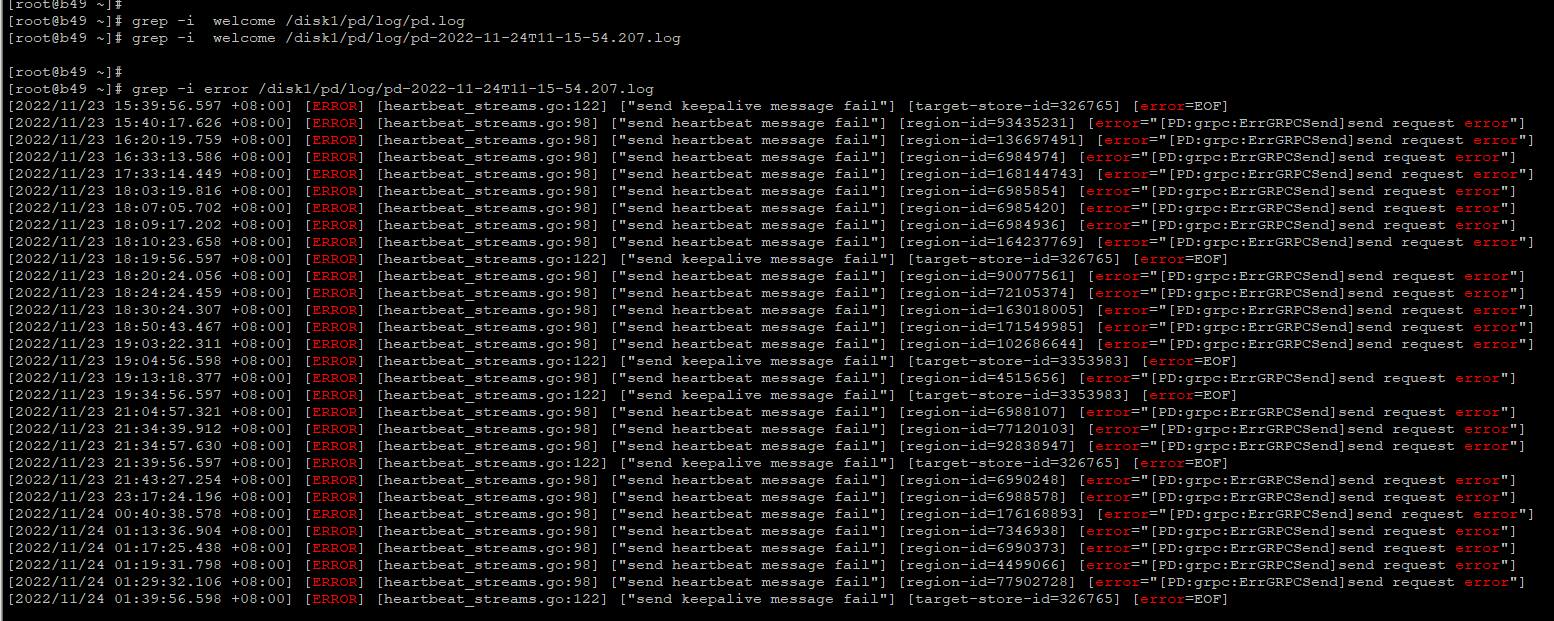
我看过pd的日志,没发现跟这个时间点一致的error日志。 或者我该怎么查呀?日志比较大怎么过滤关键词呢
找下 error,ERROR, warn,WARN 这些关键字
然后看看 tikv 是否有 welcome 的字样,表示有重启过…
估计是重启了… ![]()
检查网络问题
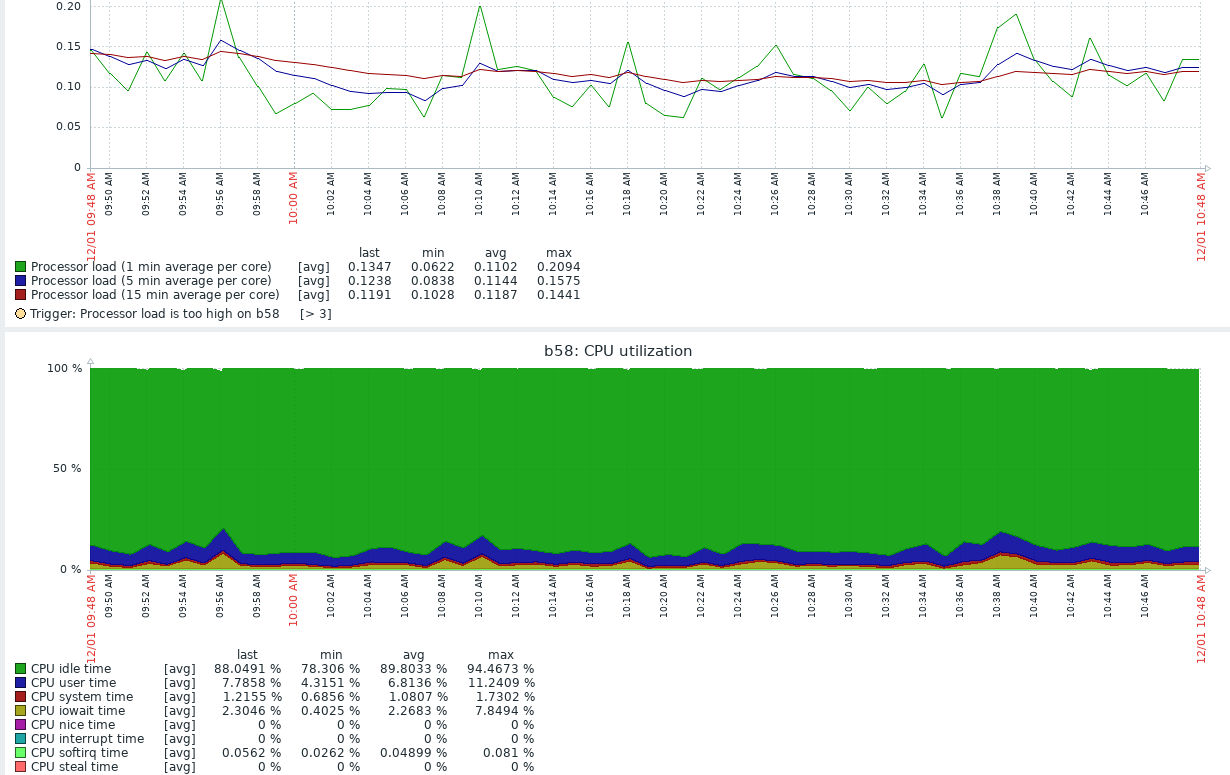
看过监控的取值,没发现异常的,但是监控一般采集数据周期较长1分/次
有啥好办法可以看吗? 我能想到的就是找个另的机器一直ping一下
有个最简单的办法,在找一台配置相同的服务器,直接扩容成 tikv 的节点实例
待扩容成功后,在下线这台有问题的即可
一般 PD 连接问题,heartbeat 心跳问题,基本上可以确定是网络不通畅导致的,会导致 PD 认为这个 节点挂了,要转移所有的 leader 和 副本,保持服务可用和副本的可用
如果是网络问题的话,那这个节点上的副本应该都会少的吧? 但现在是这个tikv上的region数量在集群中不算少的,并且region的数量还算稳定(没有突然的升降),但leader经常一直是0,偶尔增加一些leader很快就会下来。比较奇怪~
服务器资源比较紧张,没法扩容新机器哈~
怀疑是硬件问题导致的,具体的只能你自己考虑怎么查了…
好的。
周末我先ping两天看看延迟情况再说 ![]()
昨天刚处理了一个类似的时间,这个问题是gc导致的,gc的时候reslove lock ,会导致某些节点压力太大,导致假死,然后pd会立刻驱逐leader,然后节点之后恢复,pd又重新reblance-leader 导致这样的场景。
你可以看一下你的leader下掉的时间点和
tikv details监控里面 - GC里面 - reslovedlocks是否一致。
然后我猜测应该是一致的 ,然后你可以看到当时的io,GC scan_lock会导致io打满之类的问题。
感觉大佬解答,我看了下这个节点的监控,这个机器的iowait指标不高比较平衡,ioutil在集群中也不算是高的(我们机器都是普通的sata ssd,没有使用nvme,所以硬盘ioutil普遍较高),您说近个问题应该是tikv节点随机的吧?我现在问题是只是这1个tikv节点上的leader频繁掉线。
试试根据频繁 leader 掉线的 TiKV 的 store id 和具体一个 region id,通过 PD log 来分析一下 store 和 region 的状态变化。看看是否有非预期调度导致的。
你们是用什么方式部署的tidb?
你这个是虚拟机还是物理机,如果是我理解可以迁移下虚拟机到其它宿主机看看
resolve locks 为什么会导致tikv假死
看我上面评论的图片,reslove lock会导致大量的scan locks 请求,可能会导致IO满 ,从而导致TikV假死。