海石花47
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.1
【复现路径】同一个tidb环境,相同的参数设置,有一条sql 实际应用的scan算子就2个,立马就oom然后kill了sql???
【资源配置】
内存设置:
单条sql内存限制:tidb_mem_quota_query 为默认的1G
oom的动作:tidb_mem_oom_action 为默认的CANCEL
并发设置:
set session tidb_distsql_scan_concurrency =15; 都是默认值
SET session tidb_executor_concurrency = 5;
set session tidb_index_serial_scan_concurrency = 1;
【遇到的问题:问题现象及影响】
正常情况下,一条sql:
SELECT * FROM ods.tp_pay_order LIMIT 3000000;
他的结果是这样的:单条内存超限,然后15个算子,一个一个关,直到最后一个算子,还超,就kill sql。
但是,另一条sql:
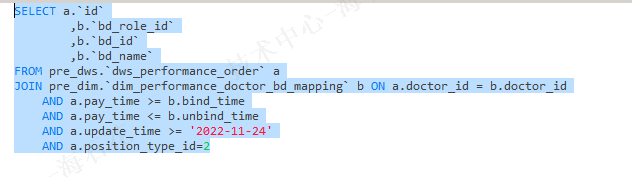
他的结果却是这样的:单条内存超限,然后2个算子,瞬间关完,直到最后一个算子,还超,就kill(截图中的时候 我已经改成oom action 为log了,不然影响了业务)
我的疑问就是,明明是同样的参数配置,为啥第二个sql 会有这样的表现,只有2个算子??
欢迎大神们讨论~
人如其名
(人如其名)
2
这句话说的不太清楚,只有2个算子还是2个token?
是否可以理解为你的疑问是:
为何不在remain token count最多的时候canel掉语句(毕竟这个时候占用内存可能是最多的),而是在最后一个的时候cancel掉语句?
如果是这个问题,那么我理解是这样的:
首先oomAction行为是有优先级的,cancel、log、rateLimit越来越高。在你这个设置中同时具有tidb_mem_oom_action=CANCEL 和 tidb_enable_rate_limit_action=ON,那么会先触发优先级高的行为,也就是先触发rateLimit行为,这个行为是为distsql做流控(一个distsql只作用于一个表上),当最后被流控到可以获得的token 只有1个的时候会fallback到次优先级的oomAction上,也就是你这里设置的cancel。所以在remain token limit=1的时候如果评估此时整个语句占用内存还是比tidb_mem_quota_query大,那么会cancel掉当前这个语句。此时虽然token 只剩下1个,也就是去做copTask的并发执行数只能是1了,但是如果之前获取到的copTask还没有被消费完那么内存还是不会释放,也就是内存占用会超过tidb_mem_quota_query的设置值。
关于第二个SQL为何有这样的表现,我理解的是:
在通常情况下(没有包含很大的region),开启了chunk_rpc,那么一个region在tidb侧的大小大约300左右的MB空间。如果只有2个copTask的response通常情况下是不会导致语句OOM的,但是你这个SQL语句时join,要看join的行为是什么,可能是join占用了较多内存,还有就是这里的total token count只是一张表的,另一张的没有体现出来,最好看下explain analyze ,看内存时怎么消耗的。
另外,在实际执行中表的并发扫描不一定完全依赖tidb_distsql_scan_concurrency 这个参数,这个参数值通用情况下最大表扫描的并发数。如果需要扫描的region数量少于tidb_distsql_scan_concurrency 设置的值,那么就不会用这么多。还有,如果对于有序的数据请求,扫描并发数也不会这么多(固定为2,避免tidb侧缓存太多数据等待有序执行导致增加oom概率)。
海石花47
3
感谢大佬又来回答我的问题~
其实我的疑问就是,为何第二个sql 的total token count = 2,而不是 默认的15 ( tidb_distsql_scan_concurrency)? 在我的理解里,这两个东西是同一个东西?
人如其名
(人如其名)
4
totaltoken count =2说明你的请求涉及到的copTask请求数是2。
有几个distsql并发扫描的概念我是这么理解的:
1、tidb_distsql_scan_concurrency代表的是最大扫描并行度(简单理解为对region的并发扫描数),如果表中并没有这么多region(或者请求扫描的region数<tidb_distsql_scan_concurrency),那么最大扫描并发数是有多少请求就并发做多少,假设实际的并发度即为:real_tidb_distsql_scan_concurrency(后续用)。
2、token limit,这个是流控用的主要手段,total token count是初始化时候池子中初始化的令牌数(等于real_tidb_distsql_scan_concurrency),remain token count是当前可用的令牌数(开始等于total token count),当触发了流控后会对remain token count一个一个销毁,直到语句内存小于tidb_mem_quota_query,最低保留1个,但是oomAction会fallback到次优先级的oomAction。
3、语句实际执行信息中会有copTask请求,这里的copTask请求是tikv的reponse回来后tidb应用后才统计的结果,比如:select * from table limit 1,假设表非常大,在执行信息中看到的copTask数也只有1,实际下发的copTask请求会有tidb_distsql_scan_concurrency个(在日志中应会有体现),也就是有一些场景下tikv资源略有浪费。
海石花47
5
前两个似乎听懂了
我看了一下,我第一个sql对应的表里 有上千个region,所以real并发就是默认的15了。
第二个sql里涉及两个表,表A 是6个region,表B 只有2个region,所以real最大并行度就是按最小的计算了吗?
海石花47
6
这个有点问题,又让我有点迷惑了。
我刚测试了一下,
explain analyze SELECT * FROM ods.tp_pay_order LIMIT 1000000,
看到结果:“cop_task: {num: 7” ,但是日志里: “total token count”=15。
copTask 和 totaltoken count 看样子不是对等关系?
人如其名
(人如其名)
7
并行度是distsql层面的,distsql层面是单表的请求。也就是每一张表一个distsql请求,一个distsql请求的并发度是根据tidb_distsql_scan_concurrency来的。这里的total token=2是单表的不是A表就是B表的。
1 个赞
人如其名
(人如其名)
8
参考这里。
你这个cop_task=7说明tidb接收到第7个response的时候正好满足了limit 1000000条件,limit算子满足需求后关闭了后续的动作。
system
(system)
关闭
11
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。

