Harvey
(Hacker E Pz K Lxax)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】4.0.12
【复现路径】针对一张有10个索引的表,进行数据删除
【遇到的问题:问题现象及影响】
环境:其中tidb 集群有6个KV节点,分布在3台机器,每个机器上有两个KV进程。
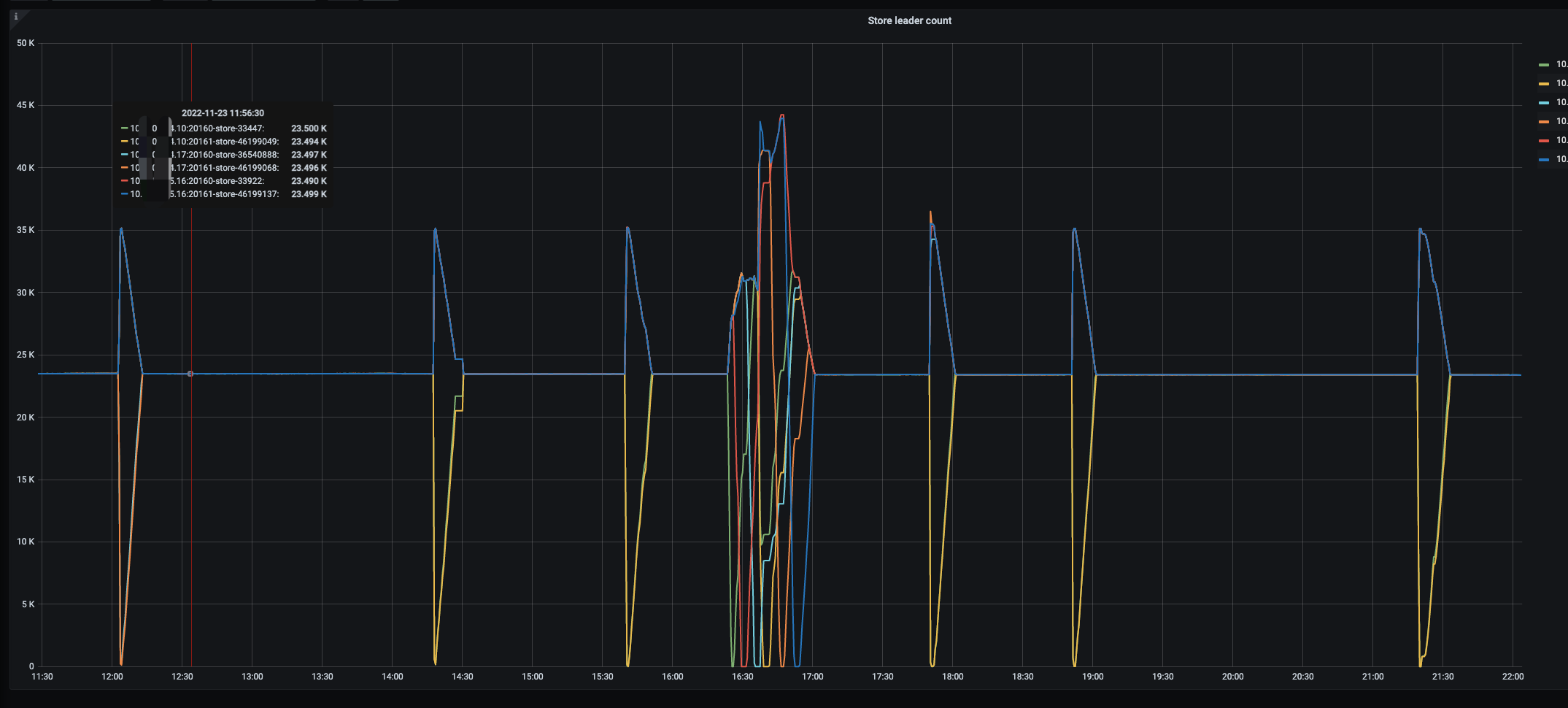
问题:KV 的三台机器分别为xxx.xxx.xxx.10,xxx.xxx.xxx.16,xxx.xxx.xxx.17。其中xxx.xxx.xxx.17和 xxx.xxx.xxx.10 ,频繁出现Leader 数量 跌为0,之后立马又开始balance leader,恢复到平衡状态。 其中,跌为0,为该机器上的两个实例一起出现该现象。
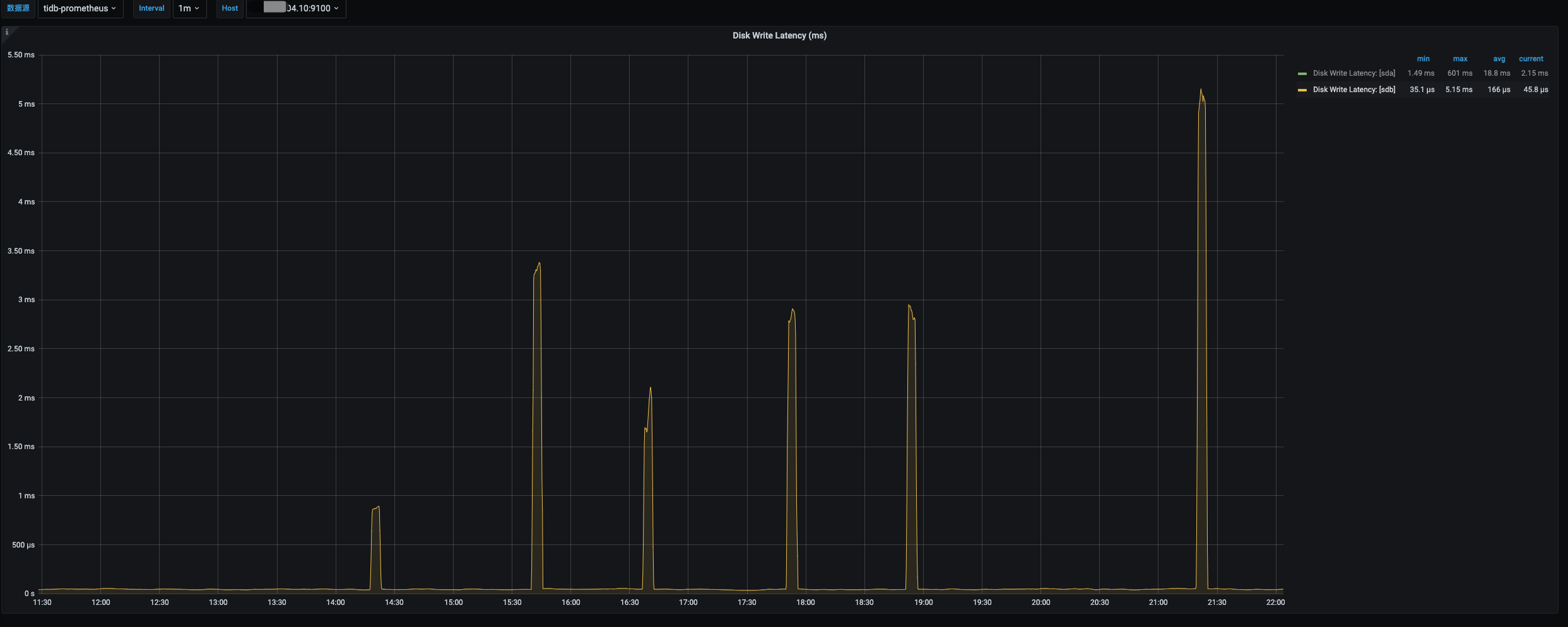
跌为0的时候到执行balance 的时候,存在一段时间数据盘 IO util 非常高,然后恢复正常。
没有删除数据的时候,不会出现Leader跌0 的状态。
查看出问题点的Leader跌0 的 TIKV 的日志,有出现比较多的
[2022/11/23 21:20:04.988 +08:00] [WARN] [store.rs:645] [“[store 33447] handle 971 pending peers include 917 ready, 1558 entries, 6144 messages and 0 snapshots”] [takes=39049]
有怀疑过机器的问题,但是查询硬件的磁盘均没有出现任何报错,而且两台机器交替出现比较奇怪。
监控信息 Clinic Service
【资源配置】
【附件:截图/日志/监控】
上述截图中间的图,交替数量变换,是在reload tikv 节点,可以忽略,观察左右的三个leader 跌0 的时间
xfworld
(魔幻之翼)
2
6个KV节点,分布在3台机器,每个机器上有两个KV进程
-
磁盘的性能是否无法撑住 两个 KV的实例?
-
网络是否有被打满的情况?(导致心跳无法有效传递)
dba-kit
(张天师)
7
可以看下是不是store的score是不是100,貌似慢节点达到100,上边所有的leader都会被驱逐
dba-kit
(张天师)
9
不过看描述应该只有一个慢节点时候,才会触发leader被驱逐的情况,你这里是两个节点同时被驱逐了,理论上不会被驱逐leader的。
额,忽略吧,没注意你的版本是4.X的。。。
Harvey
(Hacker E Pz K Lxax)
10
嗯,感谢,如果是scheduler的话,应该是慢慢驱逐,表现是一下子跌0,很像机器坏的,但是机器层面又没有相关的异常,就奇怪
Harvey
(Hacker E Pz K Lxax)
15
Jiawei
(渔不是鱼)
16
这个问题是gc导致的,gc的时候reslove lock ,会导致某些节点压力太大,导致假死,然后pd会立刻驱逐leader,然后节点之后恢复,pd又重新reblance-leader 导致这样的场景。
你可以看一下你的leader下掉的时间点和
tikv details监控里面 - GC里面 - reslovedlocks是否一致。
然后我猜测应该是一致的 ,然后你可以看到当时的io,GC scan_lock会导致io打满之类的问题。
Harvey
(Hacker E Pz K Lxax)
18
嗯,看着像是删除速度太快,GC 压力大,GC 的线程 一直100% 了
1 个赞
system
(system)
关闭
19
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。