【 TiDB 使用环境】生产环境
【 TiDB 版本】V6.1
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
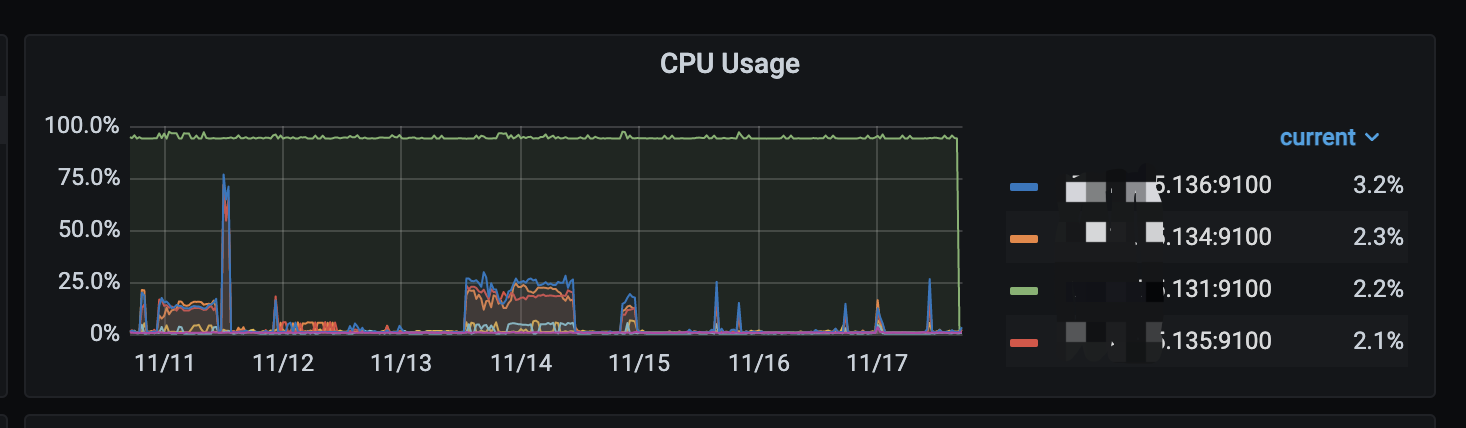
在3台tidb server 中的一台部署了一个节点的ticdc,监控了一些库的变更,跑了一阵监控发现 cdc节点 cpu 100%,查看进程发现是cdc进程占用,之后我们暂停cdc任务,kill cdc进程,重启任务得以恢复,但过一阵又出现cpu 100%,当时并无大量的增量数据
【资源配置】
3台 tidb/pd 16c * 64g, 其中第一个节点部署了一个cdc节点
3台 tikv 16c * 64g
【附件:截图/日志/监控】
Meditator
(Wendywong020)
2
1)看看cpu高的节点的 cdc server日志信息,有什么异常?
2)看看上游的tikv中的region,是否有一些异常的状态?
3)perf 看看 cdc server高的时候,内部发生哪些函数调用
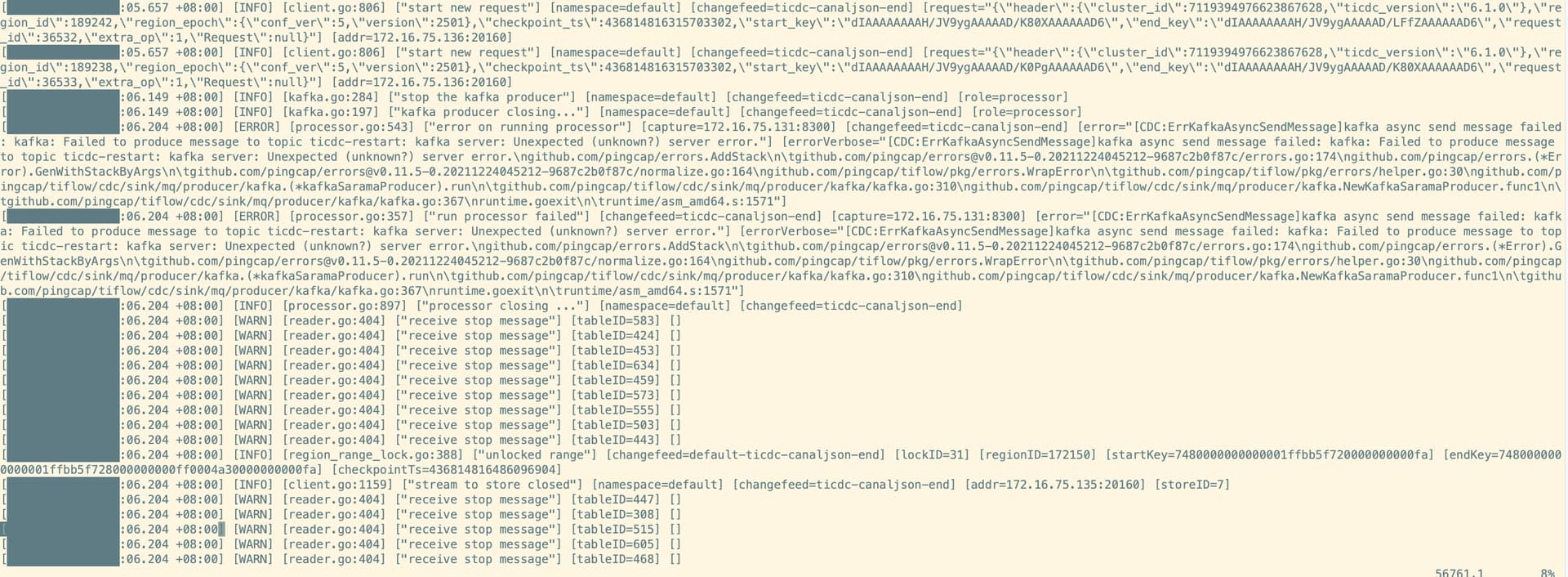
这个是刚开始发生异常的日志:
这个是cpu 100%后的日志:
看着是 kafka server 当时有点问题,那也不至于后面成这样吧?
另外perf怎么看函数调用呢,感谢赐教
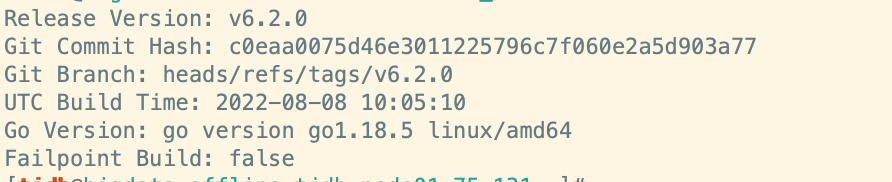
1.cdc版本:
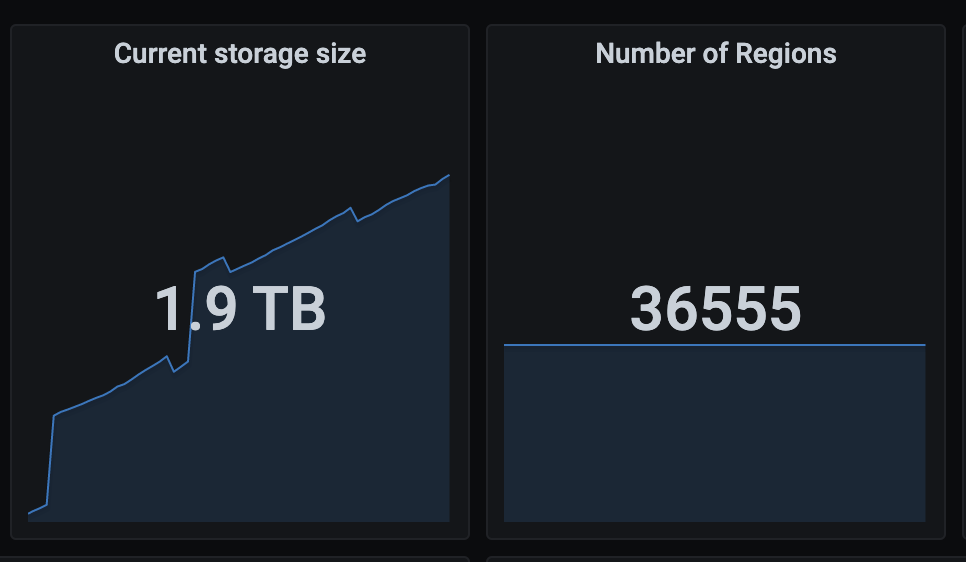
2.监听的集群表大概100-300个,region数量3w个
3.cdc当时异常日志见上面的回复
4.您说的cdc和tidb的热点时间重合是指什么?另外过了这个热点时间也应该下来了啊,但是现在的情况是我们不kill掉cdc,他会一直飙在100%
能帮忙在出现该问题的时候抓一下 profile 吗?
curl -X GET http://${host:port}/debug/pprof/profile?second=120s > cdc.profile # 抓取 cpu 采样时间 120s
curl -X GET http://${host:port}/debug/pprof/goroutine?debug=2 > cdc.goroutine # 抓取 goroutine
curl -X GET http://${host:port}/debug/pprof/heap > cdc.heap # 抓取 heap
目前怀疑是该 bug 导致,你可以尝试使用 v6.1.2 cdc 。
好的,我们的任务是6.2.0的cdc启动的,后面换到v6.1.2再重启服务是否会对之前的任务有影响呢?
不好意思我说错了,6.2.0 不能换成 6.1.2 ,麻烦你用 v6.3.0 。
我们集群版本不知道cdc 6.3.0,我们把cdc 降到6.1.2之后目前7天了没再出现该问题,看着应该是解决了,再观察观察,感谢
system
(system)
关闭
13
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。