【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】 v6.1.0
【遇到的问题:问题现象及影响】
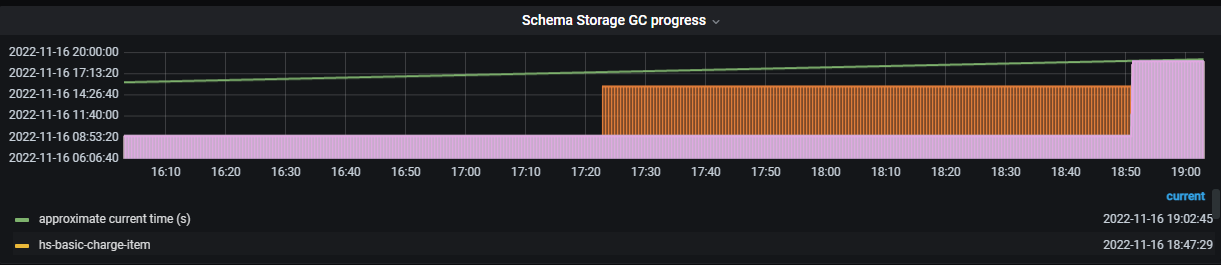
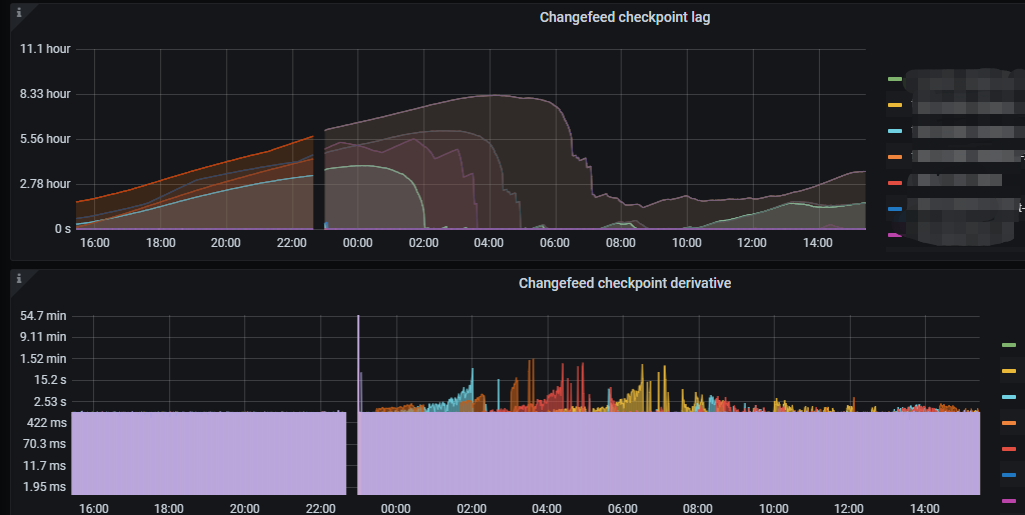
schema storage gc progress 代表什么意思,这个参数有一个表一直没有动,卡在哪里,是不是也有延迟问题,如何调优
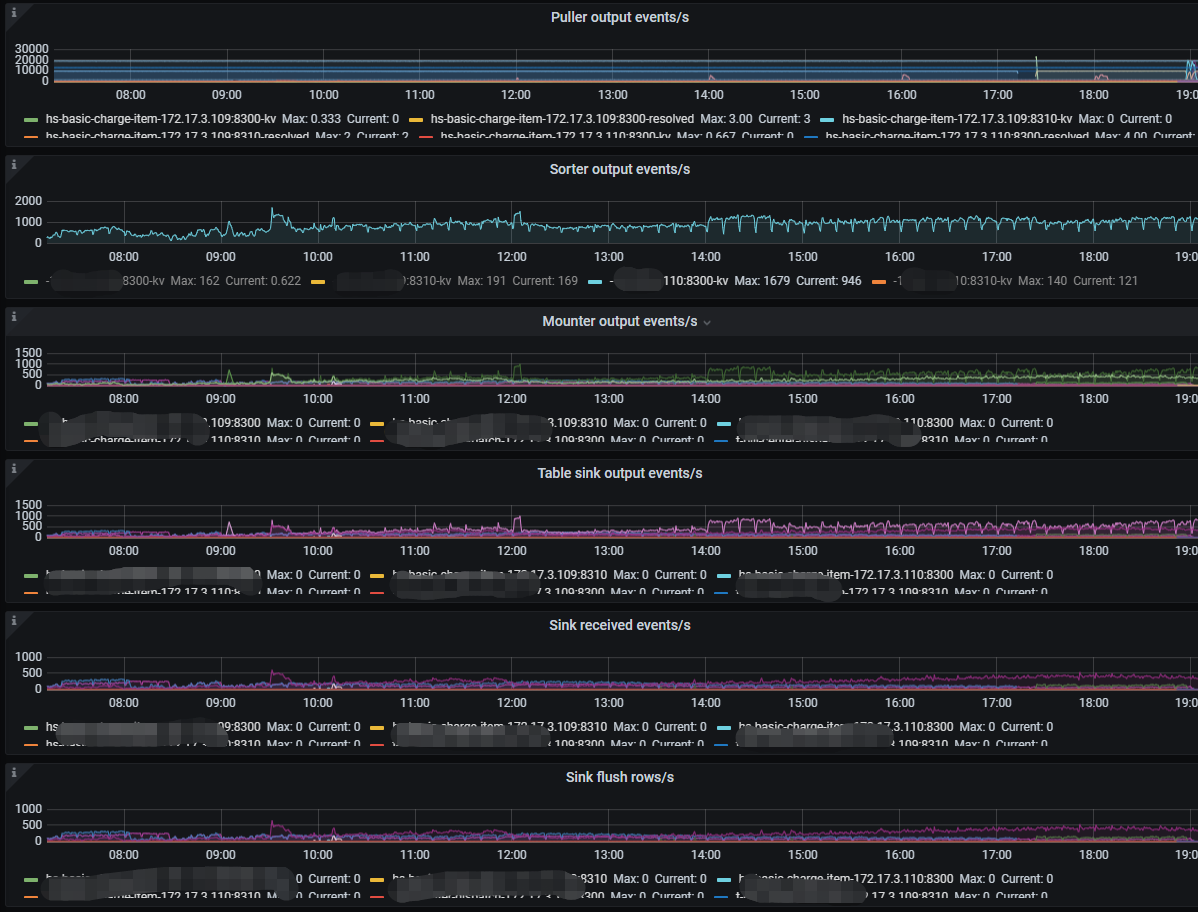
这种是不是说明cdc任务排序慢,如何调优
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】 v6.1.0
【遇到的问题:问题现象及影响】
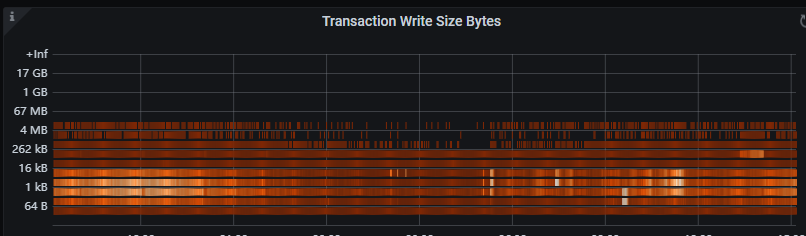
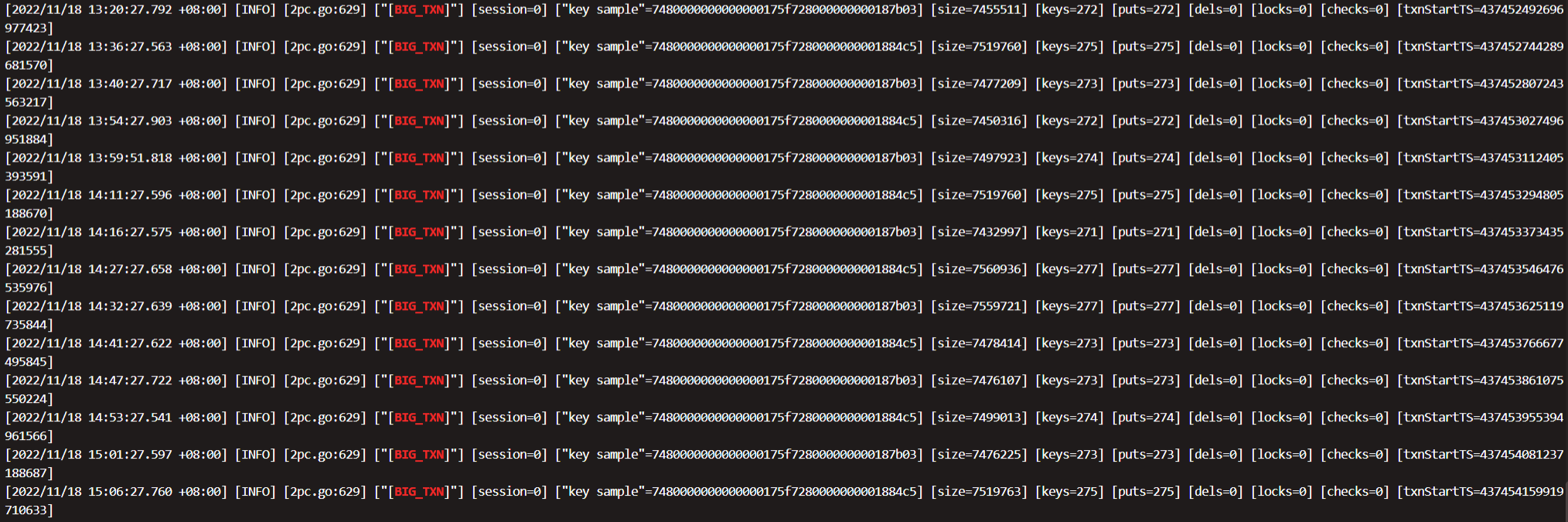
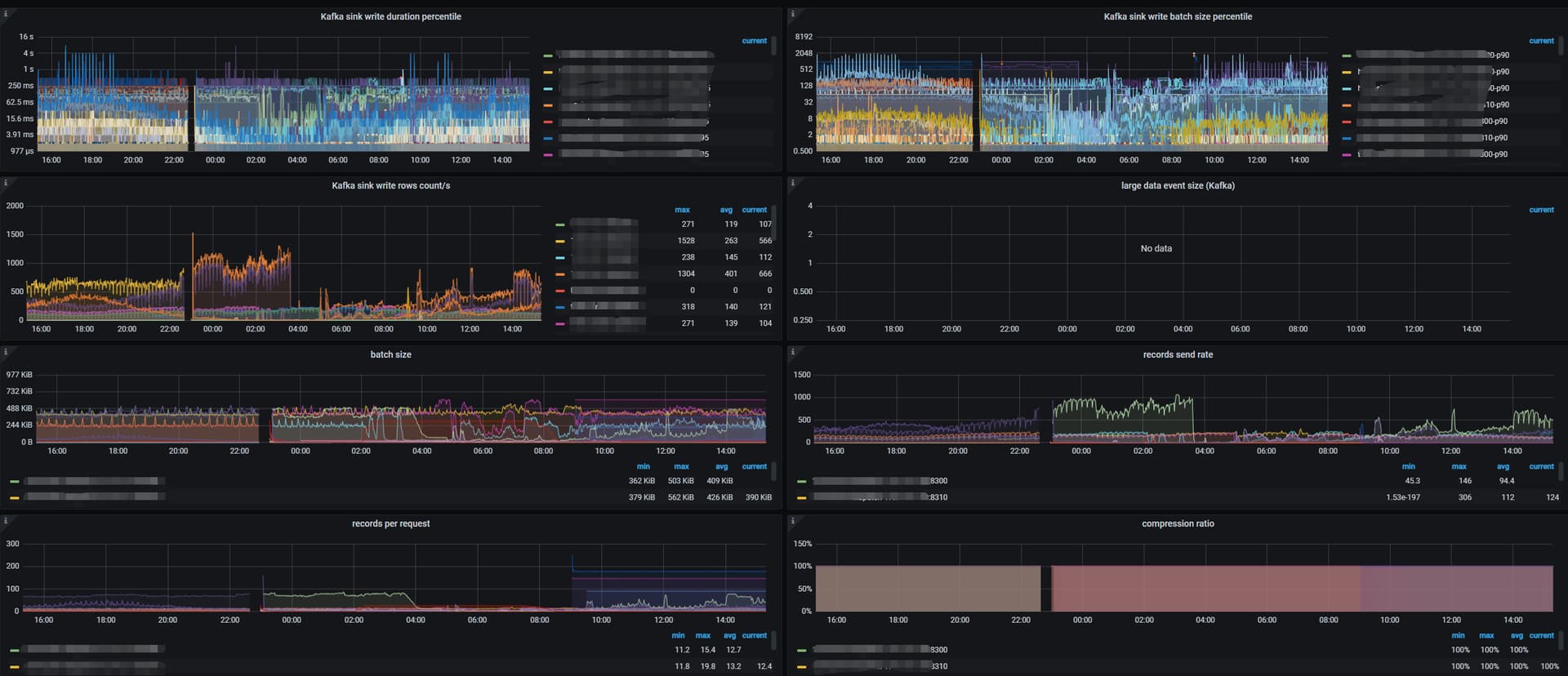
目前 TiCDC 是不是有一些 DDL 操作还在执行,另外内存占用应该会很高。另外如果是 sorter event 比较慢,要关注一下是不是大事务,通过 TiDB log 得 “BIG_TXN” 关键字和 TiDB “Trsaction Write Size Bytes” 的大小情况,再看看 TiCDC的监控 Sink write 监控。
如果确实是大事务,建议将这部分数据通过其他的备份方式同步到下游,比如使用 BR 或者 Lighting 的方式。
是有一些大事务的字样,但是量不是很多,可能是同步了一张宽表,300多个字段,日志上出现BIG_TXN每个tidb节点30-80条不等,这种情况下应该怎么调优cdc节点呢,目前是做增量同步,所以BR和lighting无法使用
Q1. 这种情况下应该怎么调优cdc节点呢?
Q2. 同一个表,建立两个测试任务同步到不同kafka,cdc端抽取延迟也不同,这是为什么呢?
最后,6.5.0 和 6.1.3 的 cdc 会对宽表的同步有针对性的优化,到时候你可以尝试使用。
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。