【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】5.4.1
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-tidb-oom#tidb-oom-故障排查

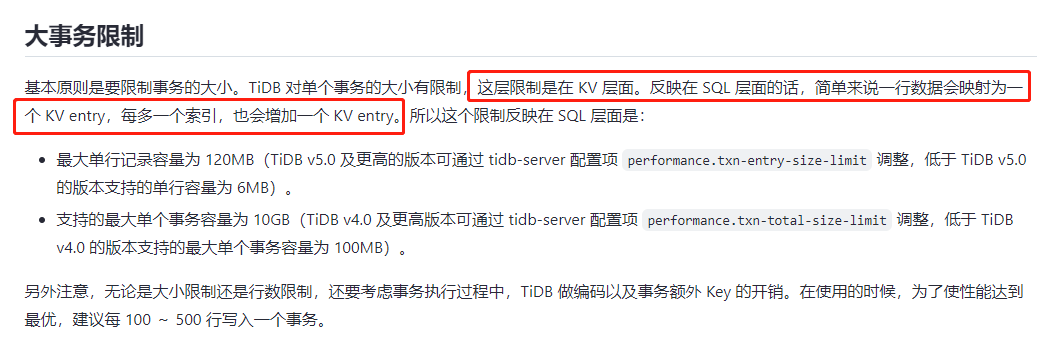
为什么会有2-3倍放大,有大佬解答下吗
【资源配置】
【附件:截图/日志/监控】
【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】5.4.1
【复现路径】做过哪些操作出现的问题
【遇到的问题:问题现象及影响】
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-tidb-oom#tidb-oom-故障排查
如果是单节点就很好理解,事务有多大,内存就有多大的占用,可能有一些优化的方式,会采用磁盘做了临时存储,用内存来进行局部回放进行处理。
但是分布式的,就存在多个节点,每个节点上都会分派一部分数据,然后数据又不是严格按照最佳的结构来的匹配,肯定会有放大的情况
参考官方的解释:
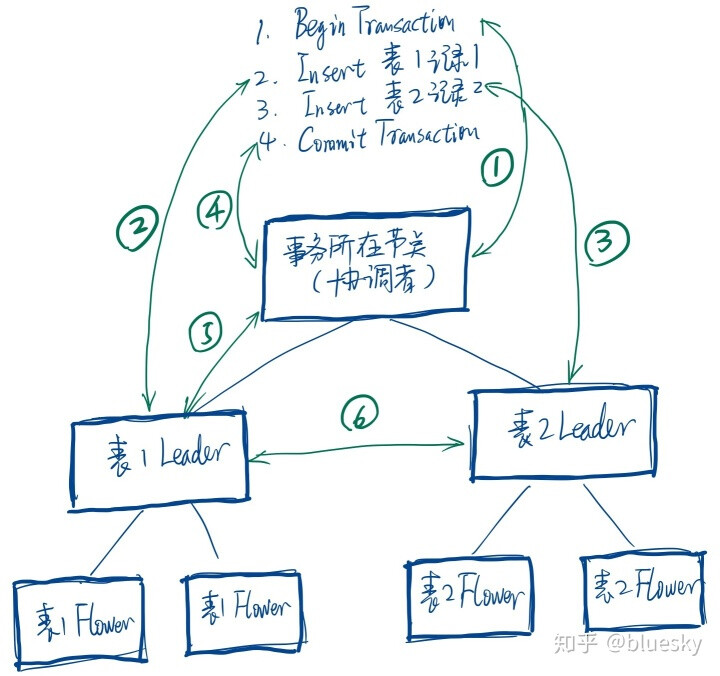
别人画的一张草图,借用一下
主要来表达二阶段提交中需要的多次协调,每次协调都需要保存状态,因为要保证一致性。如果提交成功,就一起写入。如果提交失败,就完全撤回。这个协调的过程,就需要内存来存放很多信息了
还是不太理解,您说的分布式存在多个节点,感觉这里的内存占用放大应该在kv层,那反应在tidb-server层会放大多少呢,写入场景下,会做一次do read,所以会有一次读出来的数据的内存占用,
二阶段提交前会有写内存的的一次占用,还有就是索引的写入(包含索引的do read)
编码key value的占用
这么理解对吗,do read那里是会读取行记录吗
打个比方,update 的时候,就会需要先读取整行的记录,这个时候整行的记录就需要放到内存
更新未提交,则会修改内存的数据,提交完成则数据会在 tikv持久化
那官网文档这里说的内存放大,其实是包含了tidb和tikv的对吗
当然,其实就是一份数据
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。