ojsl
(Ojsl)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
aws ec2 tiup部署
【概述】 场景 + 问题概述
数据资源使用率不高,不是硬件资源的瓶颈
【背景】 做过哪些操作
【现象】 业务和数据库现象
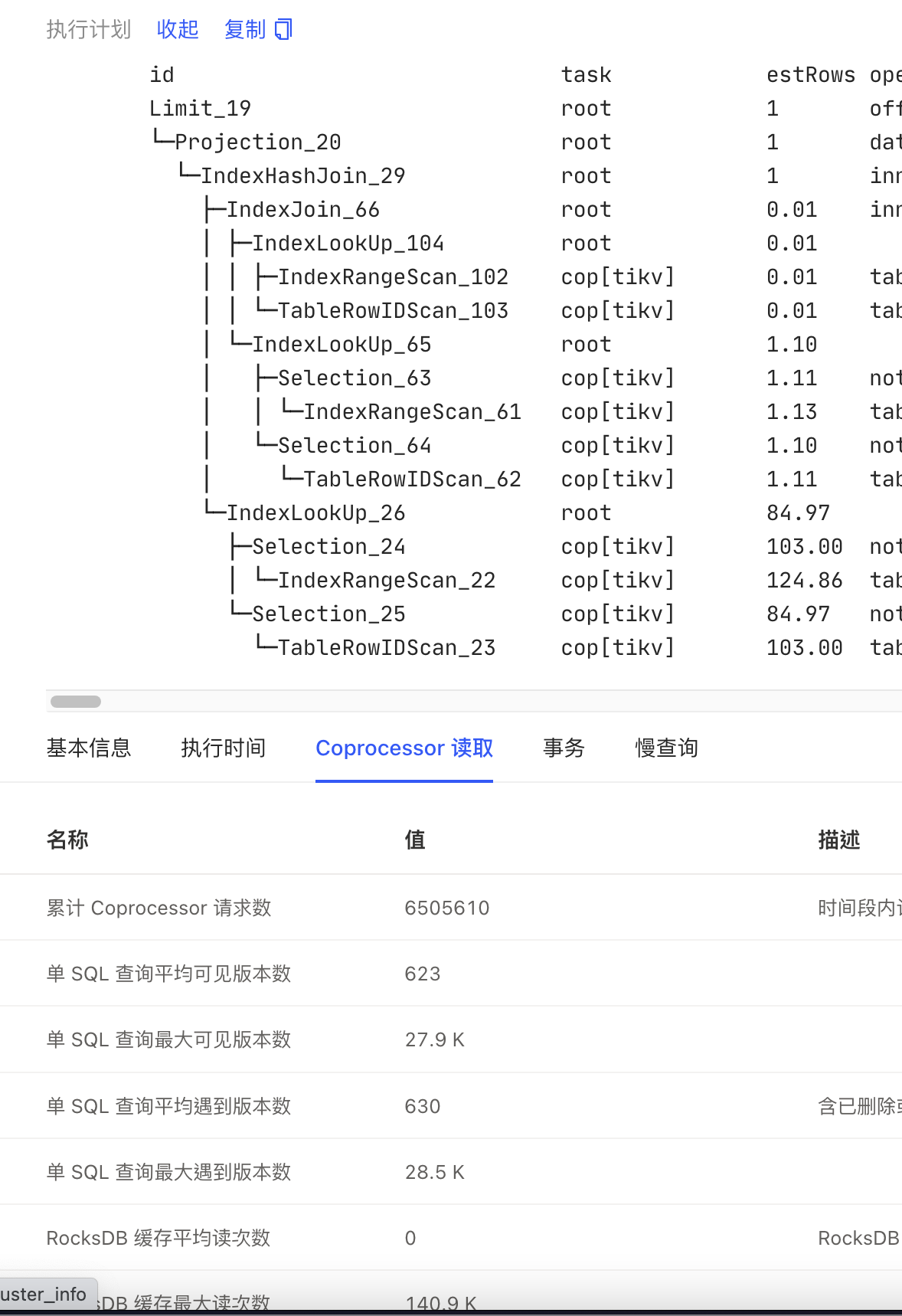
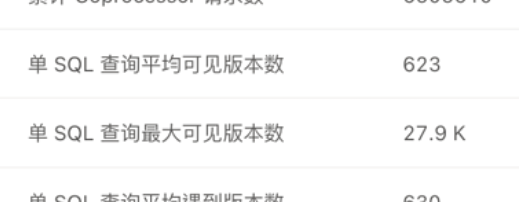
有一个并发较高的sql,平均查询时间50ms左右 但少部分查询大于1s。对比慢查询和平均查询,执行计划一致,慢查询的Coprocessor请求数 可见版本数 比平均值大一百倍以上。
【问题】 当前遇到的问题
sql超时
【业务影响】
导致部分sql在业务系统体现为超时。
【TiDB 版本】
5.2.1
【应用软件及版本】
spring boot
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
h5n1
(H5n1)
2
不同的条件扫描的数据范围不同,这个数据范围有大量历史版本未清理。另外你第二个图是累积值
ojsl
(Ojsl)
3
这个查询对应的数据是缓慢变化的,没有大量修改数据,但慢查询的可见版本数 也比平均值高很多。
ojsl
(Ojsl)
5
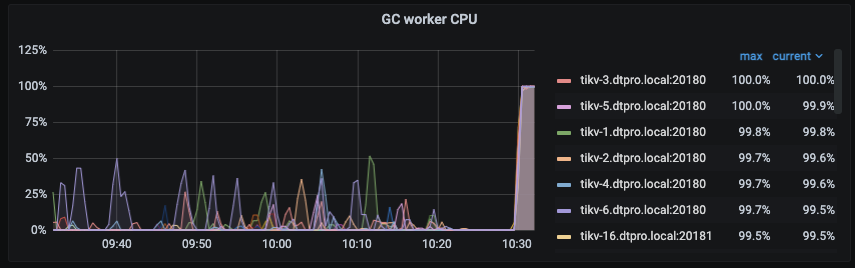
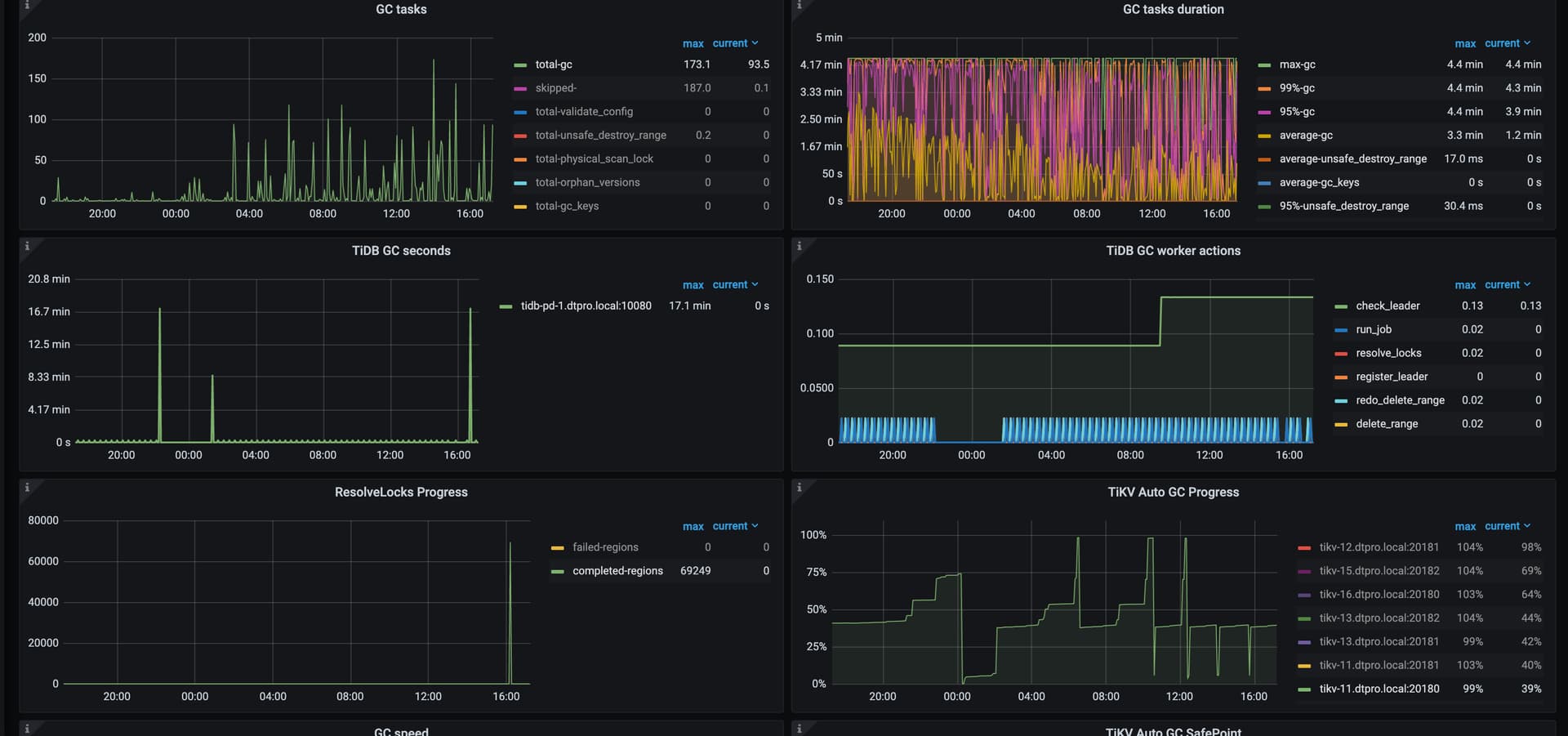
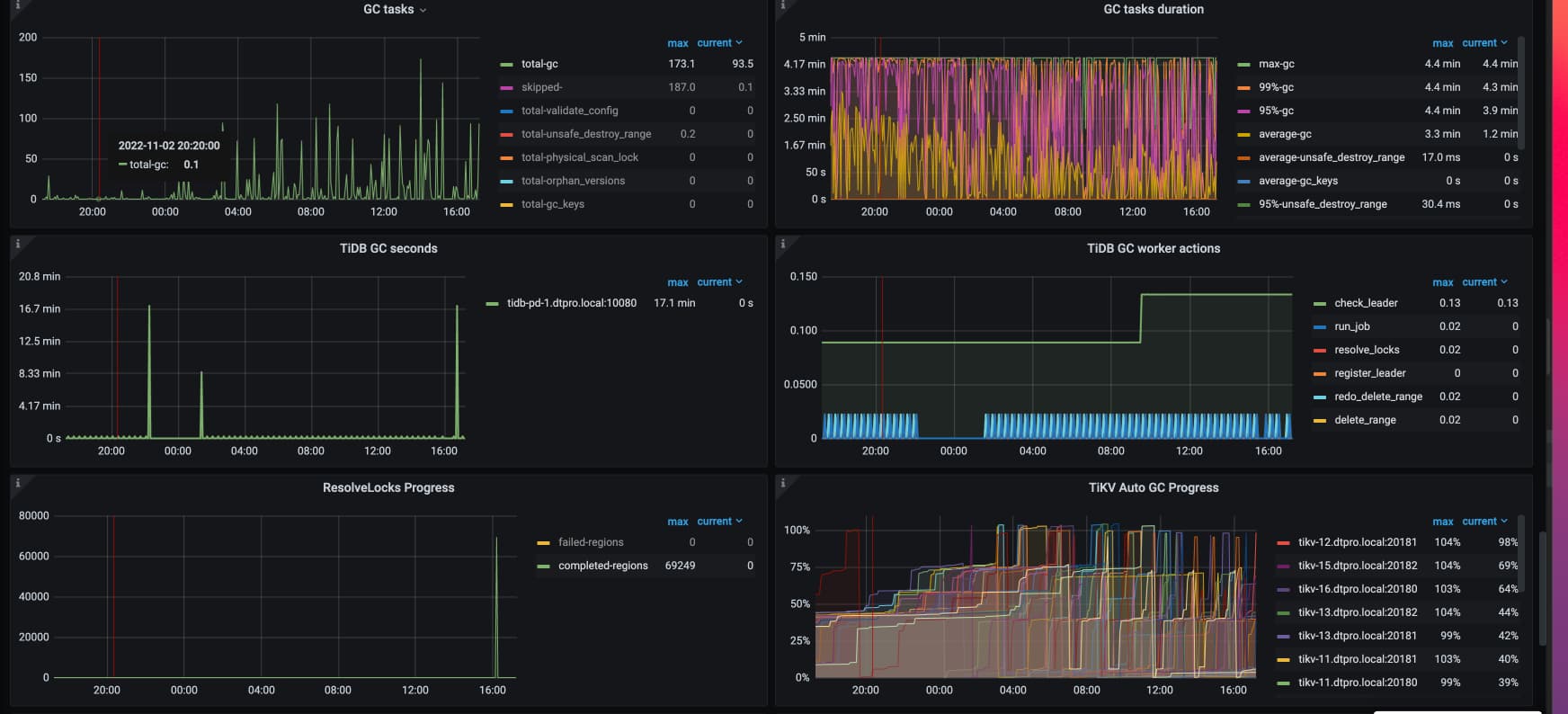
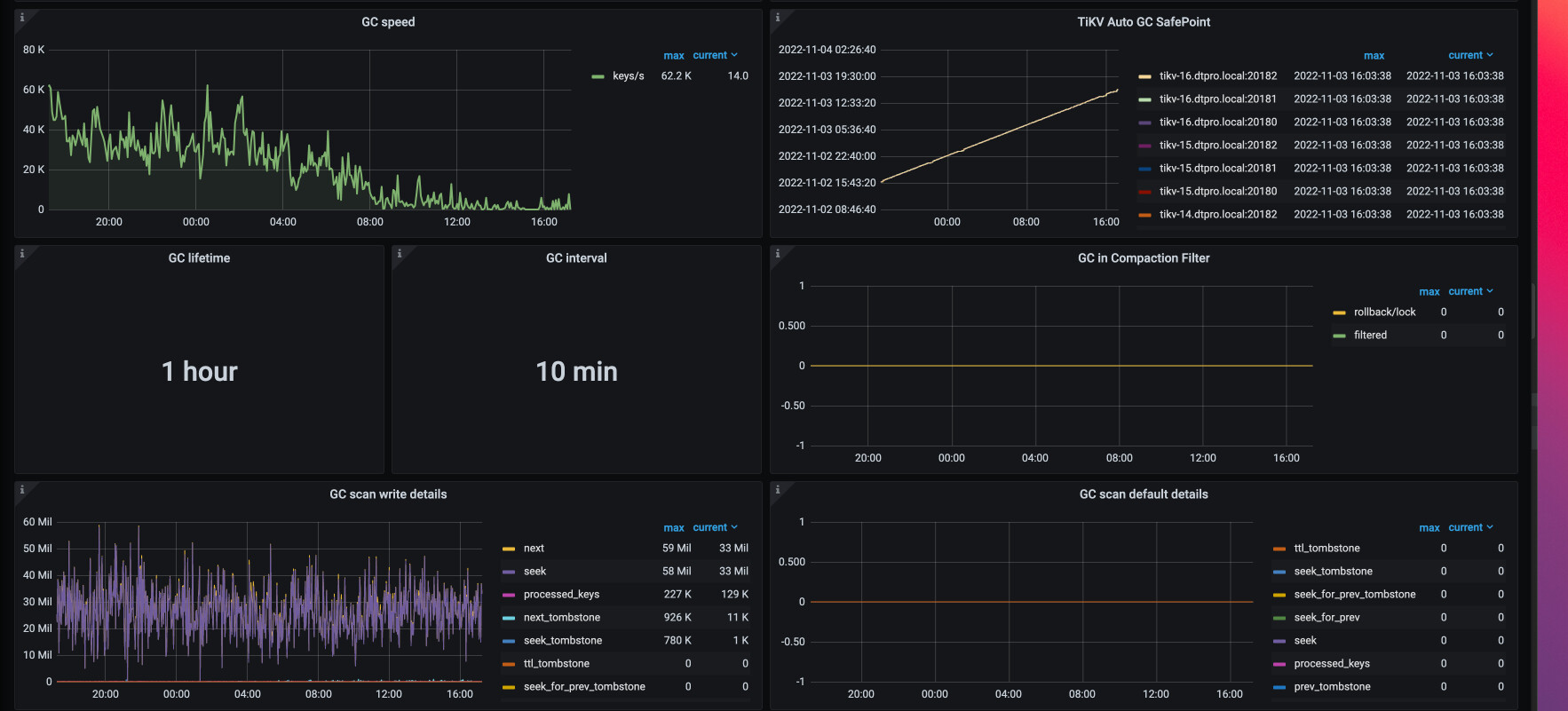
验证了相关数据符合这个bug,已经修改配置,gc cpu上来了
老哥觉得做个类似于pg vacuum的功能官方会不会做 
gc遇到bug的时候历史数据删除不掉,可以手工一条命令搞一下,或者类似于备份或什么操作的是先执行下是不是更好
ojsl
(Ojsl)
9
有专门的gc线程工作,现在是有版本bug,不能正确返回需要gc的内容。
ojsl
(Ojsl)
10
调整gc参数2天后,gc speed明显下降,但explain analyze table的统计信息中key_skipped_count并没有降低,请问现在的状态是正常的吗。
ojsl
(Ojsl)
11
我们查看一个5.4版本的集群 发现对其中一张表进行explain analyze table ,得到total_process_keys: 110686744 ,key_skipped_count: 276305791。但观察gc监控正在工作。我们对5.2的集群调整参数一个星期了,但explain analyze table得到的key_skipped_count并没有降低