【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.0
【遇到的问题】 tidb-server占用内存持续升高,频繁导致重启
【复现路径】tidb5.2.3升级到6.1.0后,新开业务线批量写入数据量比较大,负载较之前明显升高,这个问题就出现了
【问题现象及影响】
由于业务需要每天会有大量表批量写入,使用jdbc批量写入,具体参数如下
jdbc:mysql://***********:4000/database?useConfigs=maxPerformance&useServerPrepStmts=true&rewriteBatchedStatements=true&allowMultiQueries=true&prepStmtCacheSize=2000
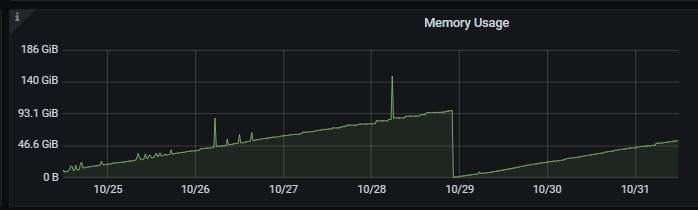
问题现象:tidb频繁重启,经过观察,tidb-server占用内存每天升高20g,最后达到内存限制,节点重启,然后内存占用仍会慢慢升高,陷入循环。
影响:批量写入任务一般运行时间在10m左右,写入期间节点重启会报连接拒绝,任务失败
tidb内存监控,为了避免业务影响,此次为手动重启,重启后内存仍在升高,如下图:
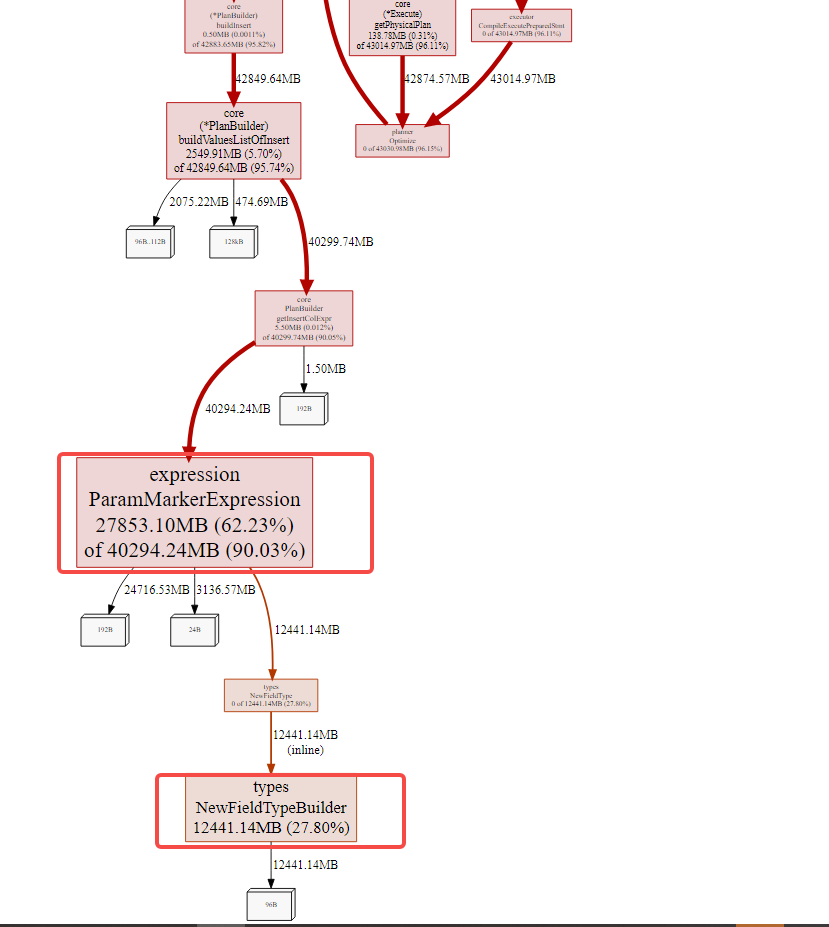
tidb doshboard的节点 heap 关系图如下:
从占用情况来看,明显 expression ParamMarkerExpression 、types NewFieldTypeBuilder 这两部分占用了近乎89%的内存
看这俩部分应该是使用prepare方式写入时用?代替具体字段值时产生的内存使用。
解决思路:
1、有没有参数设置这两块的内存使用大小?
2、使用的内存及时释放
不用看 不用问 这个tidb oom是正常现象。你去dashboard控制台上看一下在执行的慢sql 那个内存占用高。吧这个sql限制一下 设置2个参数 一个执行时间。一个内存大小 执行后重启tidb server
set global max_execution_time=2000;
set global `tidb_mem_quota_query=1073741824;
这两个参数设置好后 需要重启每个oom的tidb 重启好之后就不会发生oom了 。你再去日志里面查找被阻断的sql 这些sql是慢sql 导致数据库卡住了
可以看看是否开启了,如果是的可能是tidb_enable_prepared_plan_cache 的问题,可以尝试把先关闭看看
tidb_enable_prepared_plan_cache 从 v6.1.0 版本开始引入
- 作用域:GLOBAL
- 是否持久化到集群:是
- 默认值:
ON
- 这个变量用来控制是否开启 Prepared Plan Cache。开启后,对
Prepare、Execute 请求的执行计划会进行缓存,以便在后续执行时跳过查询计划优化这个步骤,获得性能上的提升。
- 在 v6.1.0 之前这个开关通过 TiDB 配置文件 (
prepared-plan-cache.enabled) 进行配置,升级到 v6.1.0 时会自动继承原有设置。
慢sql里 有 系统的ANALYZE TABLE ,业务上的 insert into values()、delete from 这些sql。
复杂sql引起的内存升高基本都是瞬时或者短暂的,sql停止或杀死之后内存就回落了。我们现在遇到的问题是在长期平稳的使用中出现的内存持续升高,一点点的升高。
2个参数是指:单个sql的使用内存限制 和 单条sql的执行时间 吗?
单条最大内存已经配置了4g,单条最大执行时间没有设置
就是慢sql引起的 你把慢sql解决了 就不会出现tidb内存慢慢变高了
近墨者zyl
10
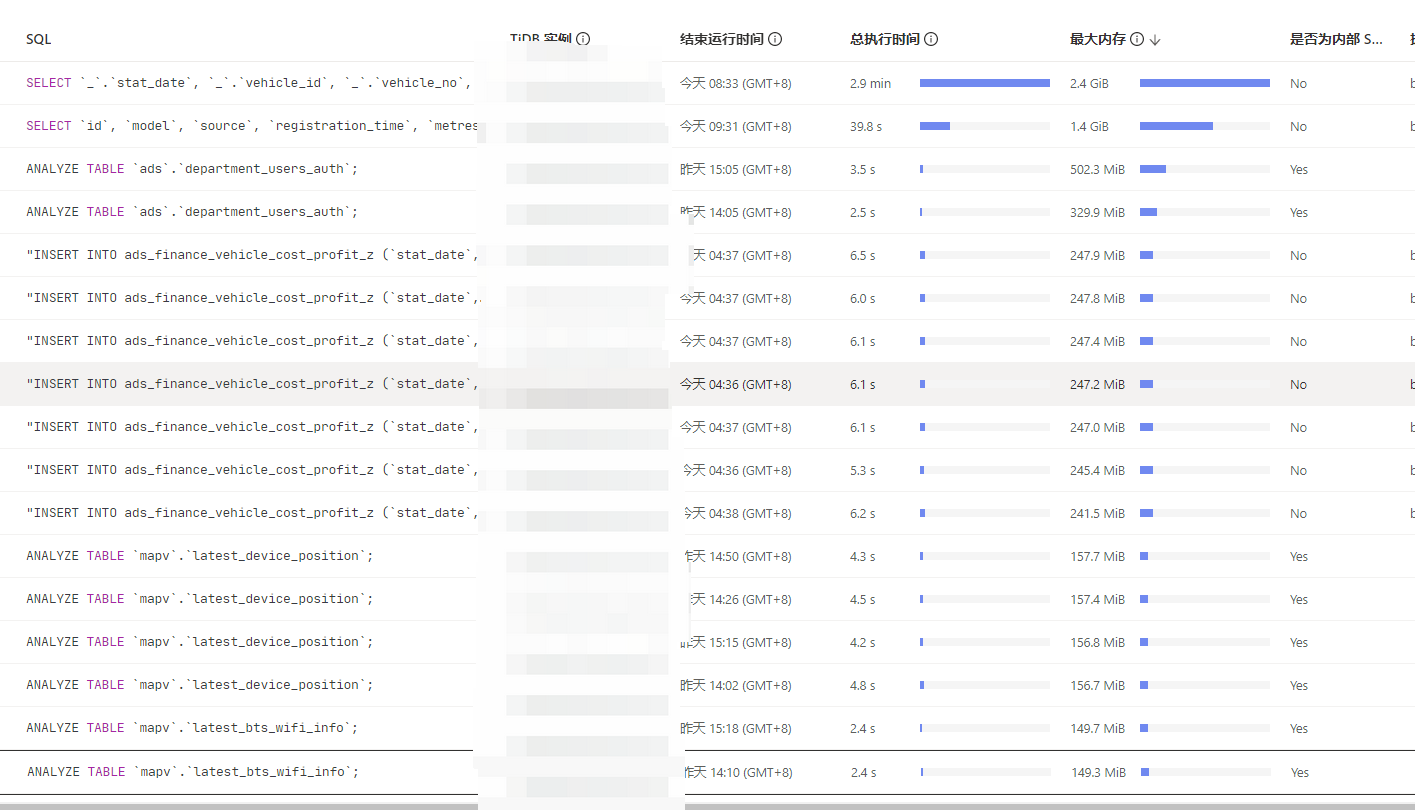
我觉得也是慢sql,可以把dashboard的内存排序sql,展示一下。
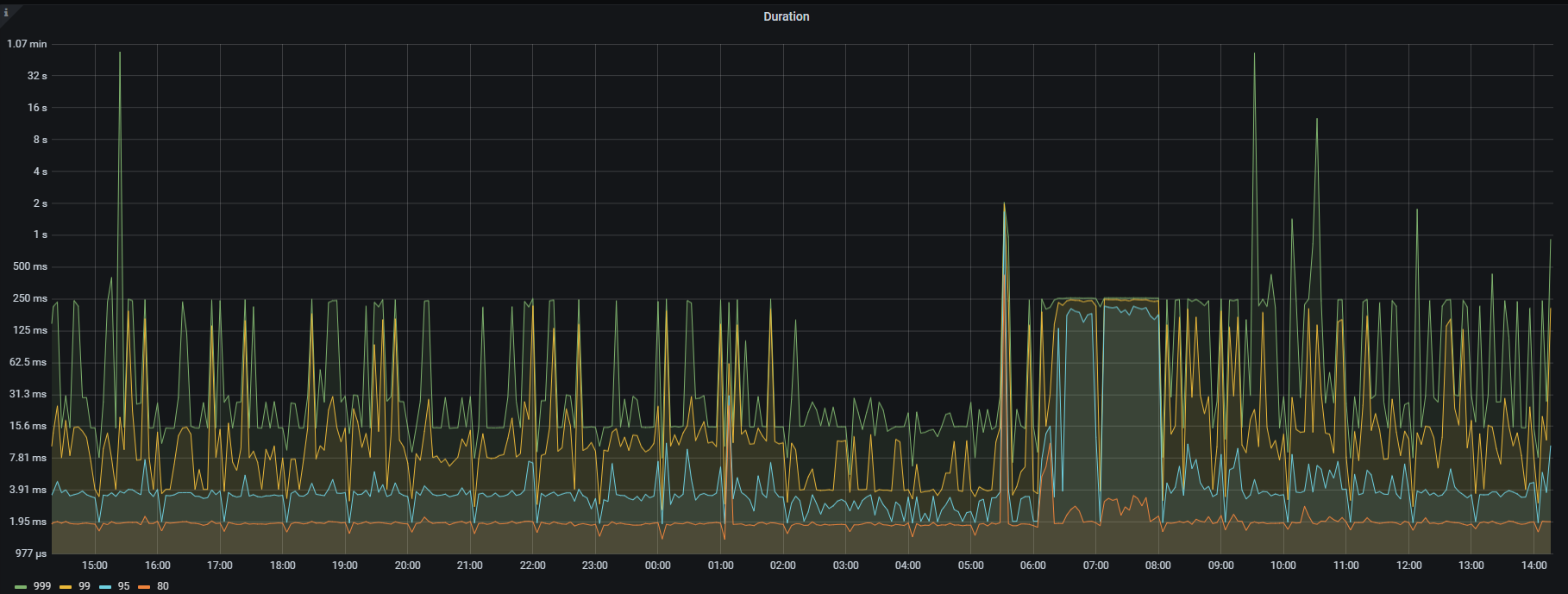
把 granfana tidb 的duration 截图发一下
单个sql最大内存设置了,最大执行时间没有限制,但是我查看tidb运行中的sql,每个节点大概20多个,运行时间没有发现超长的,大部分几百秒,个别有2000的
谢谢,我这里的这个参数是默认值开启状态,我关闭看看
近墨者zyl
15
看这张图,不是慢sql的问题,是集群整体异常的问题,可能是硬件、可能是参数,影响了整体,你根据一个链接,查查吧
读性能慢-总纲.
非常感谢各位提供的思路和建议,现在问题基本找到了,在这里反馈一下。
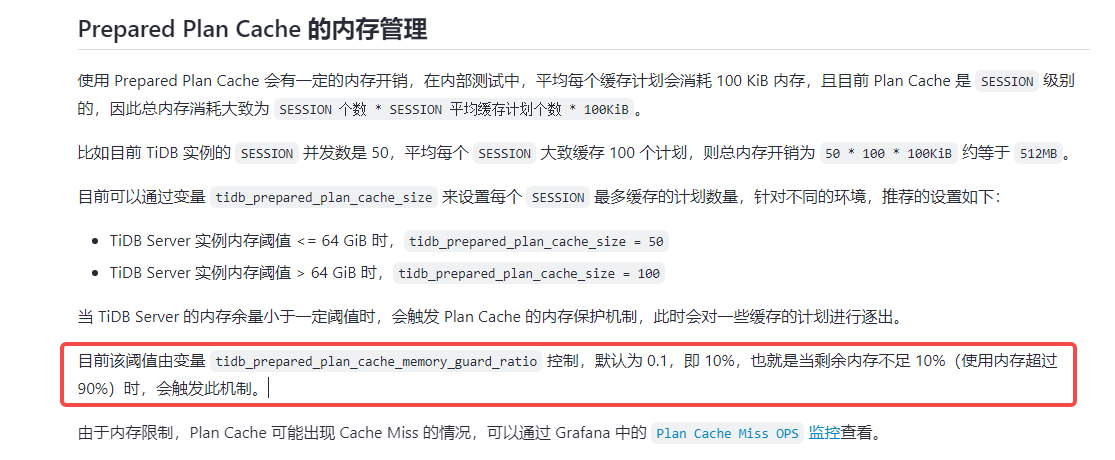
内存不断升高确实是因为v6.1.0默认开启了 tidb_enable_prepared_plan_cache,执行计划缓存导致内存慢慢升高。
预留内存参数 tidb_prepared_plan_cache_memory_guard_ratio 阈值太小了,默认0.1,计划缓存最大可以占用90%。
如果接近阈值时,有大sql或高并发,瞬时内存可能就达到tidb-server 最大内存限制,导致tidb-server节点重启。
目前通过手动释放节点计划缓存 ADMIN FLUSH INSTANCE PLAN_CACHE ,节点内存马上降到10g以下。
计划调大预留内存 tidb_prepared_plan_cache_memory_guard_ratio 参数。
我的问题找到了,特别感谢您提供的思路,确实是plan_cache的问题,我调小了阈值,后面观察看看。再次感谢
system
(system)
关闭
19
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。