【 TiDB 使用环境】生产环境
【 TiDB 版本】v6.1.1
【遇到的问题】将集群升级到6.1.1后,tidb pod的内存使用持续增加

tidb pod的日志:
tidb-cluster-tidb-0_tidb.log (415.1 KB)
curl -G tidb_ip:port/debug/pprof/heap > heap.profile 用这个抓取下内存,看看升级前后tidb监控中的goroutine数量变化
heap.profile (307.5 KB)
在tidb监控中的没有找到goroutine指标
tidb → server ->goroutine count
profile再重新弄下,我这打开报错

heap3.profile (247.1 KB)
导出这个文件的时候,pod已经重启了,这时候使用了700M左右的内存
先分析下看看慢SQL吧,看看有没有多个执行计划的SQL,tidb_enable_prepared_plan_cache 这个参数关闭试试
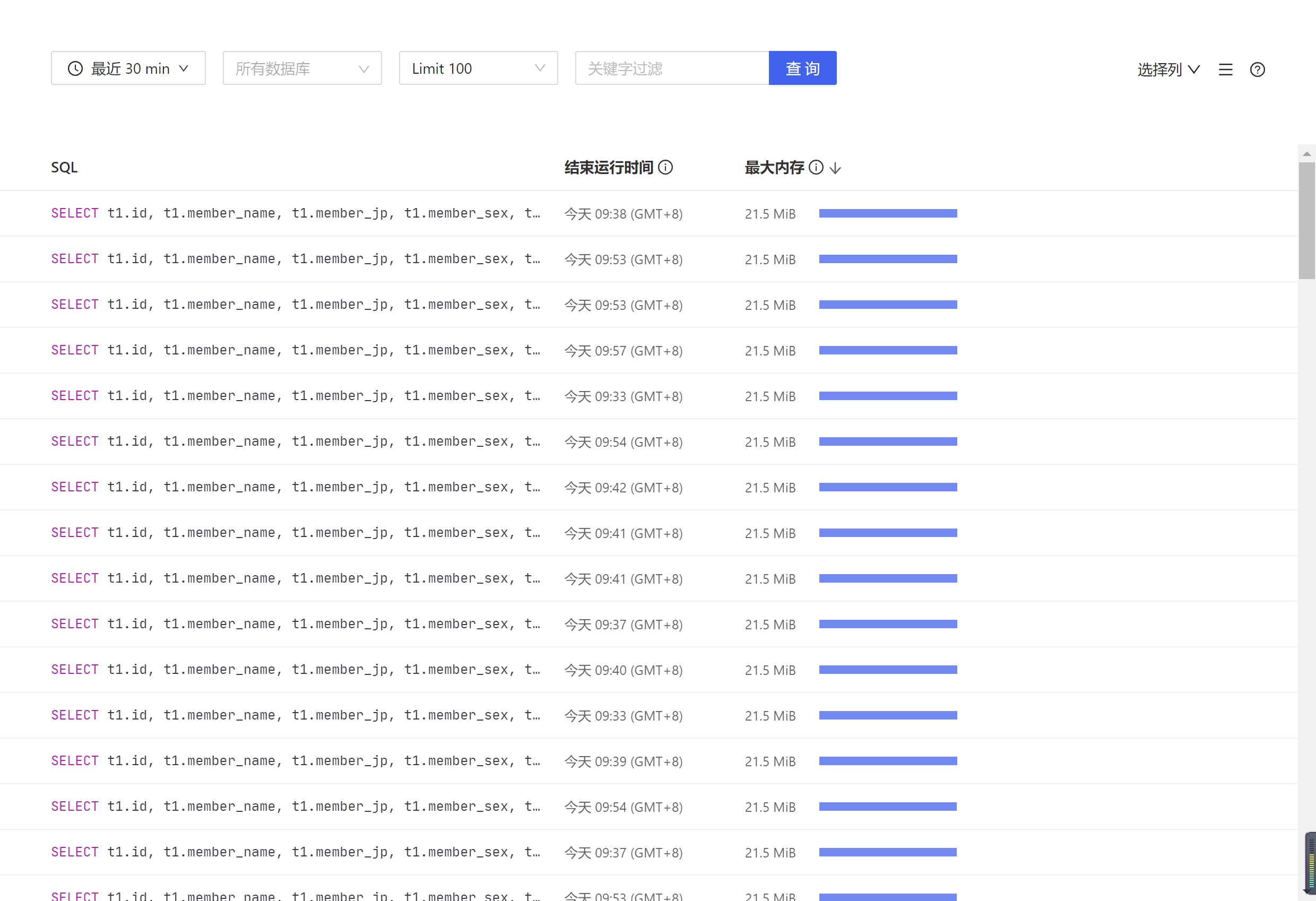
dashboard满SQL按内存排序
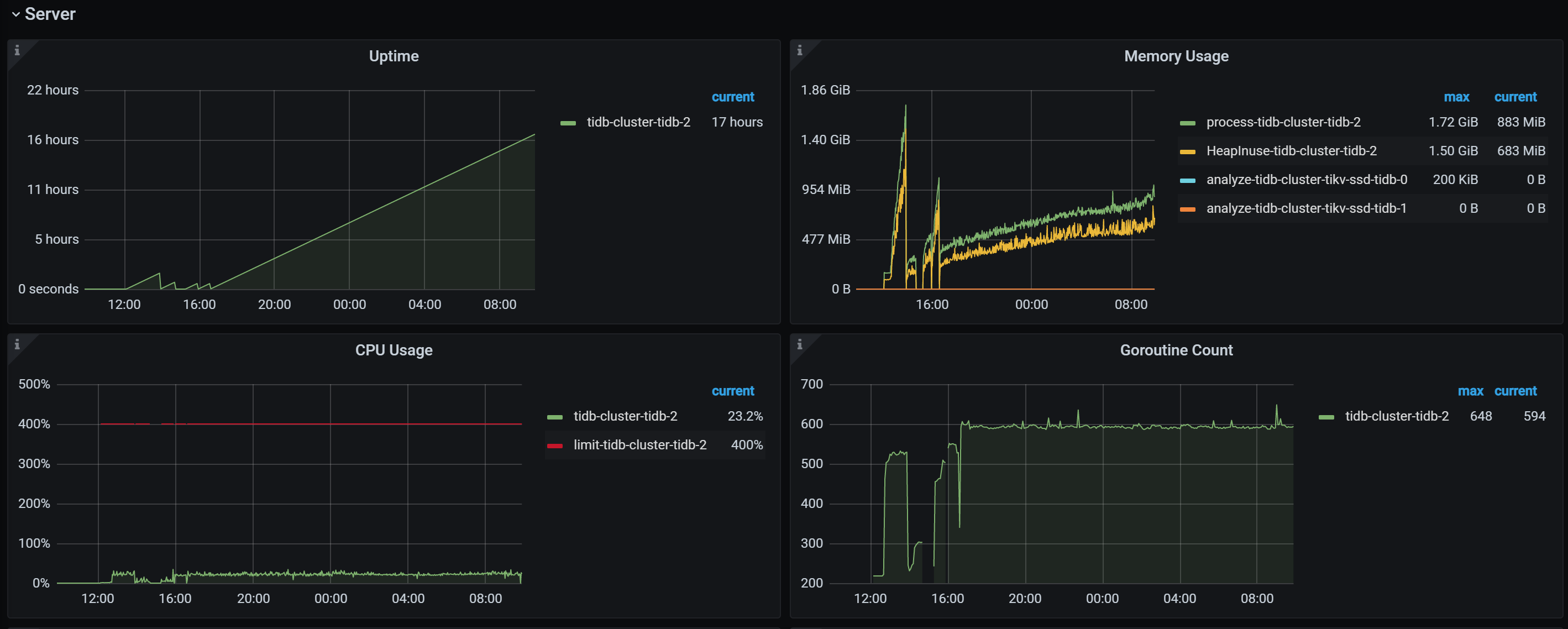
这个没法和升级前对比,另外你按前面说的 先优化下慢SQL。尝试下关闭Plan cache 看看是内存占用是否能降低,涨到某个大小后是否就不在增长了,有可能新版本的一些功能和特性需要的基础内存比以前版本多
Plan cache 已经关闭了,相比之前的增长的比较缓慢了,图中内存增加缓慢部分就是关闭后的效果
SQL 看看还能优化吗 我看这些SQL好像一样
sql的执行计划和详情,这个sql的并发数是多少
SELECT t1.id, t1.member_name, t1.member_jp, t1.member_sex, t1.member_image, t1.phone, t1.mailbox, t1.source, t1.create_id, t1.create_date, t1.edit_id, t1.edit_date, t1.version, t2.id AS cid, t2.version AS cversion, t2.nationality, t2.nationality_label, t2.province, t2.province_label, t2.city, t2.city_label, t2.county, t2.county_label, t2.native_place, t2.card_no, t2.card_type, t2.nation, t2.birthday, t2.address FROM member_info t1 LEFT JOIN member_certificates t2 ON t1.id = t2.member_id WHERE t2.card_no = ‘’;
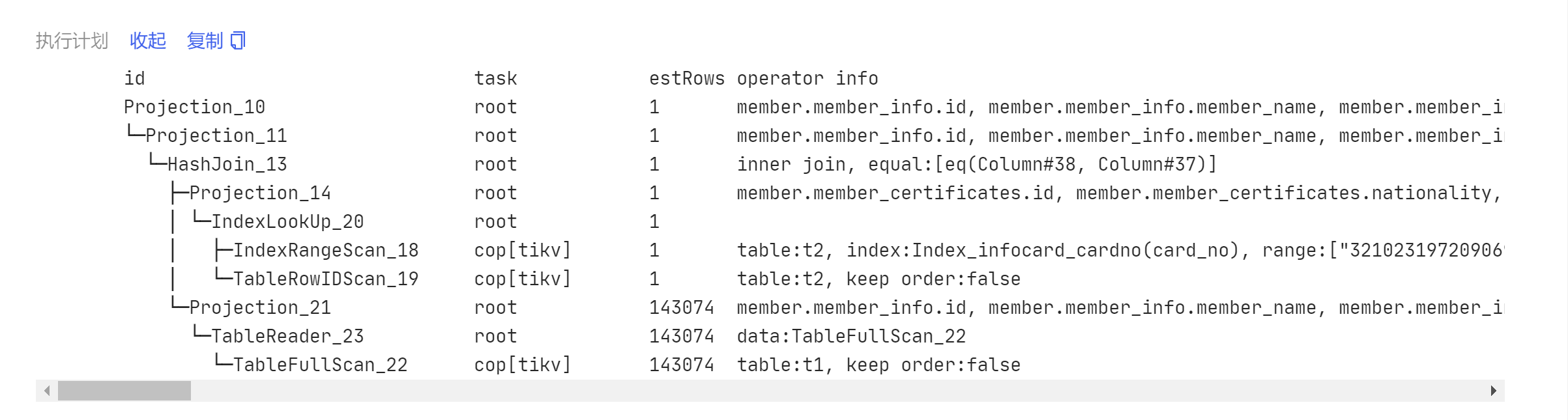
并发不高,有时候几分钟查询一次,有时候一个小时查询一次
业务方面讲,有必要left join吗?