普罗米修斯
1
【 TiDB 使用环境】生产
【遇到的问题】dumpling全量下载了2.7T的数据,lightning全量导入create库和表已完成,在执行insert语句时执行了5个多小时,到2022/10/24 20:05后面就不动了。
lightning脚本:
#!/bin/bash
nohup /home/tidb/tidb-toolkit-v5.0.1-linux-amd64/bin/tidb-lightning -config tidb-lightning.toml > /home/tidb/tidb-toolkit-v5.0.1-linux-amd64/bin/tidb-lightning.log 2>&1 &
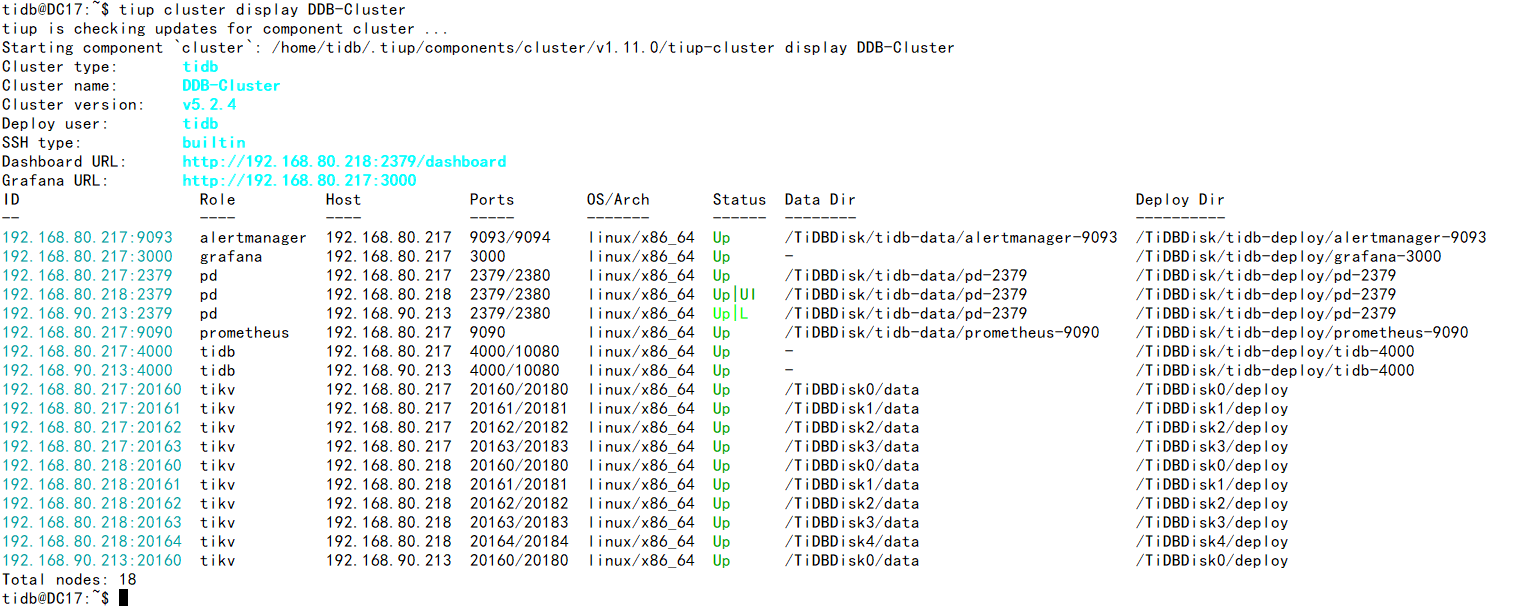
TiUP Cluster Display 信息:
普罗米修斯
2
从tidb v3.0.3 全量dumpling下载下来,向tidb v5.2.4中lightning全量导入
看上去 split 和 scatter 都已经完成了。下面应该是在 import kv 到 tikv。
可以看看 tikv 那边的日志,或者 dump 一下 lightning 的 routine 看看卡在哪里了。
FYI:https://docs.pingcap.com/zh/tidb/stable/tidb-lightning-faq#如何获取-tidb-lightning-运行时的-goroutine-信息
普罗米修斯
5
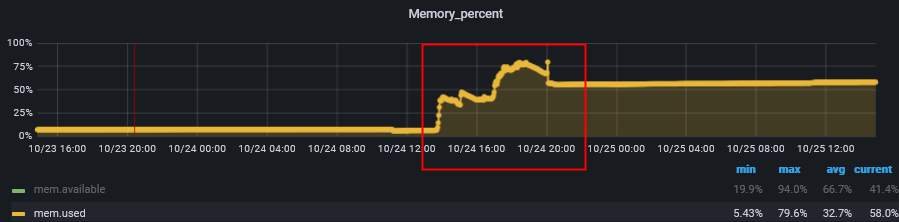
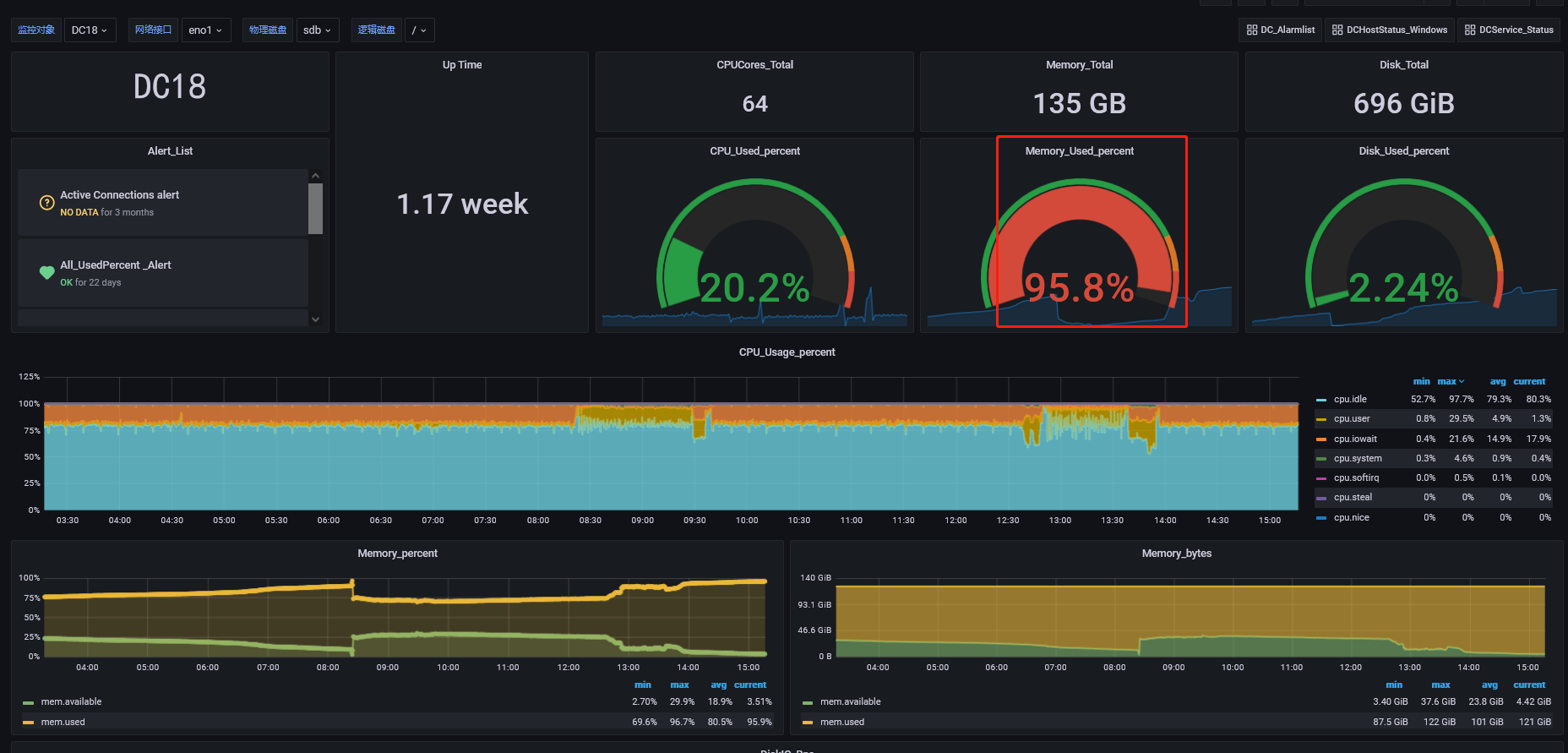
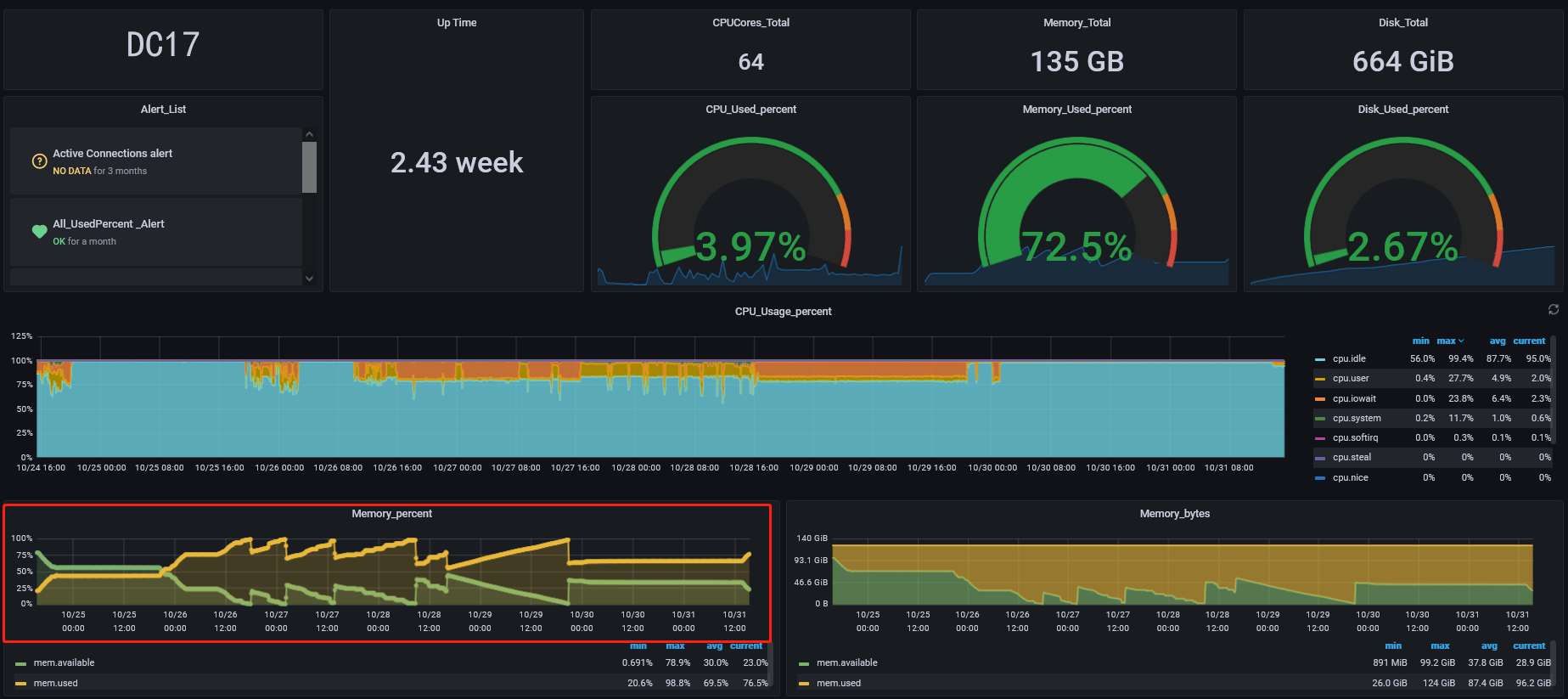
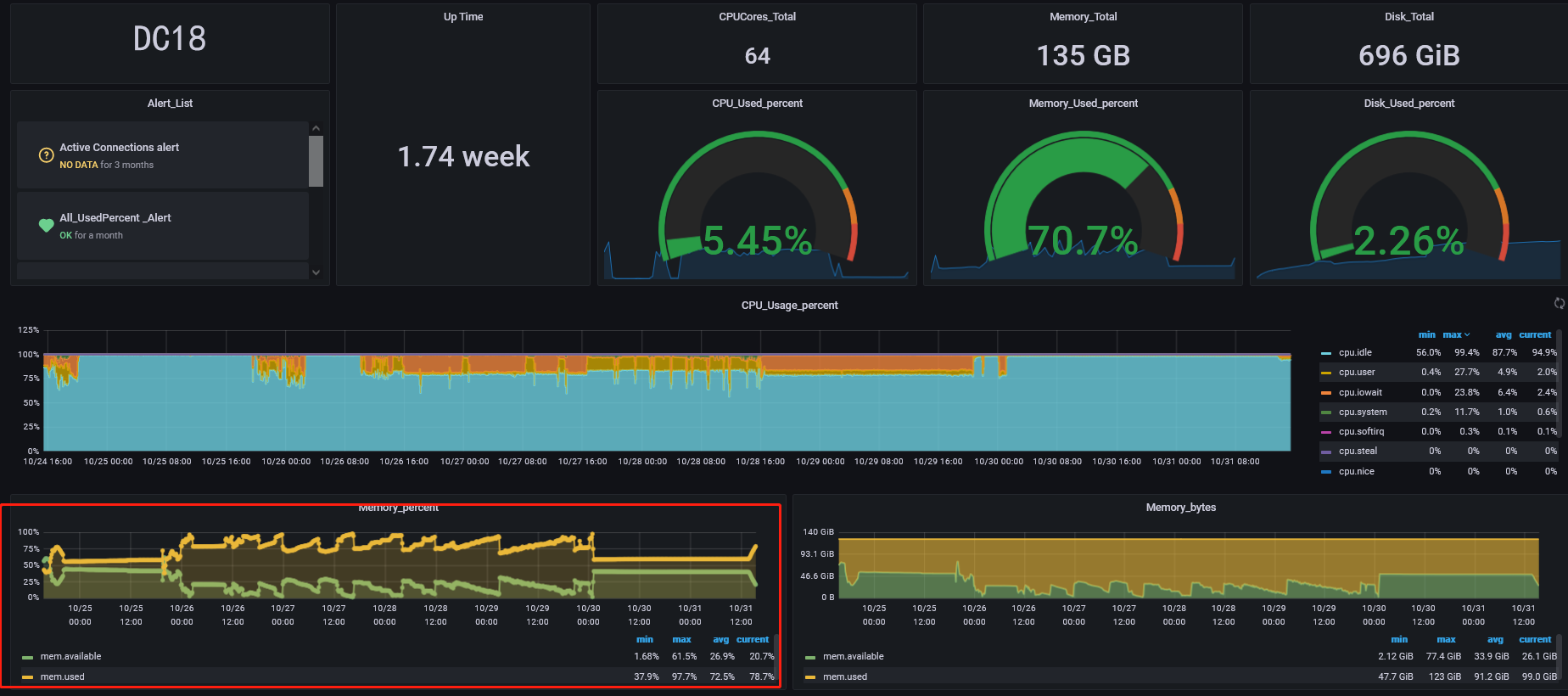
lightning执行脚本的服务器在全量导入时内存使用率最高为79.6%,
CPU使用率也不高;
普罗米修斯
6
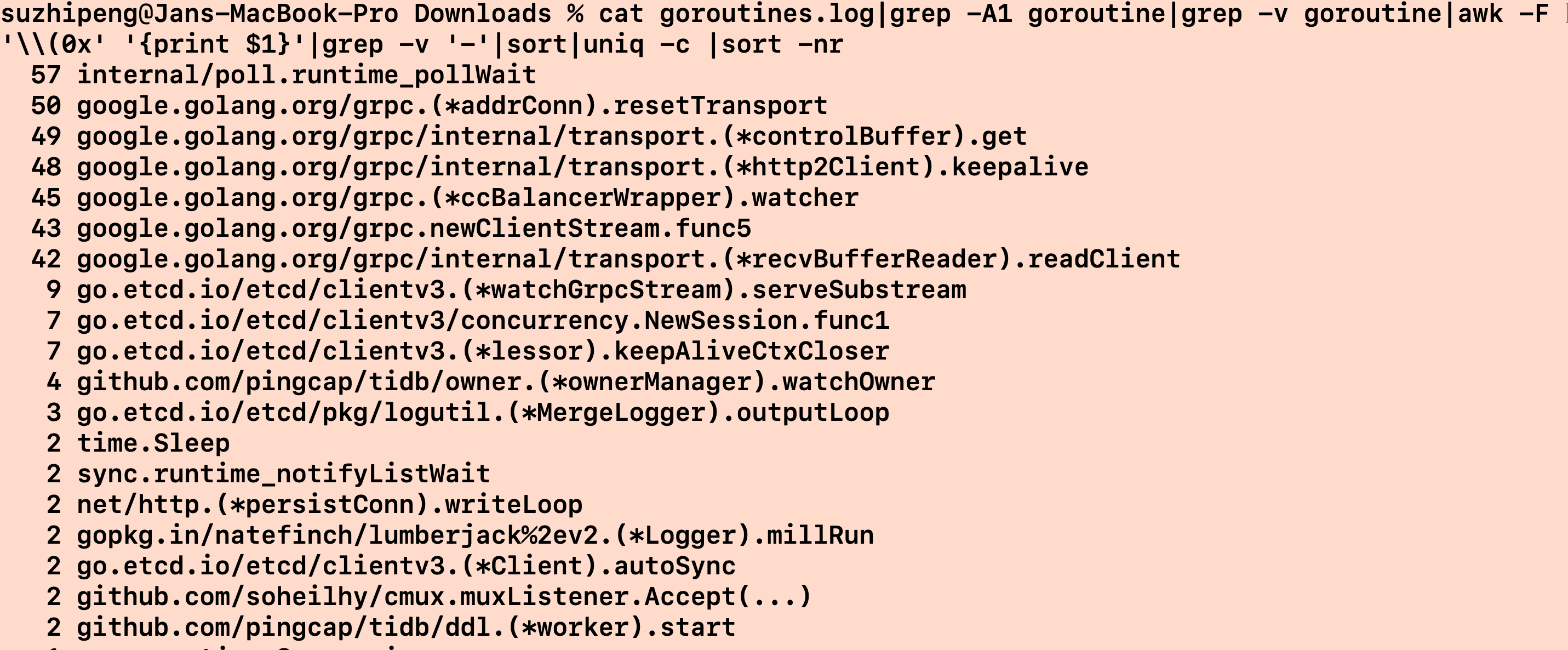
goroutines.log (393.7 KB)
gotoutines文件
普罗米修斯
7
tikv1.log (3.8 MB)
tikv日志,劳烦看下
普罗米修斯
9
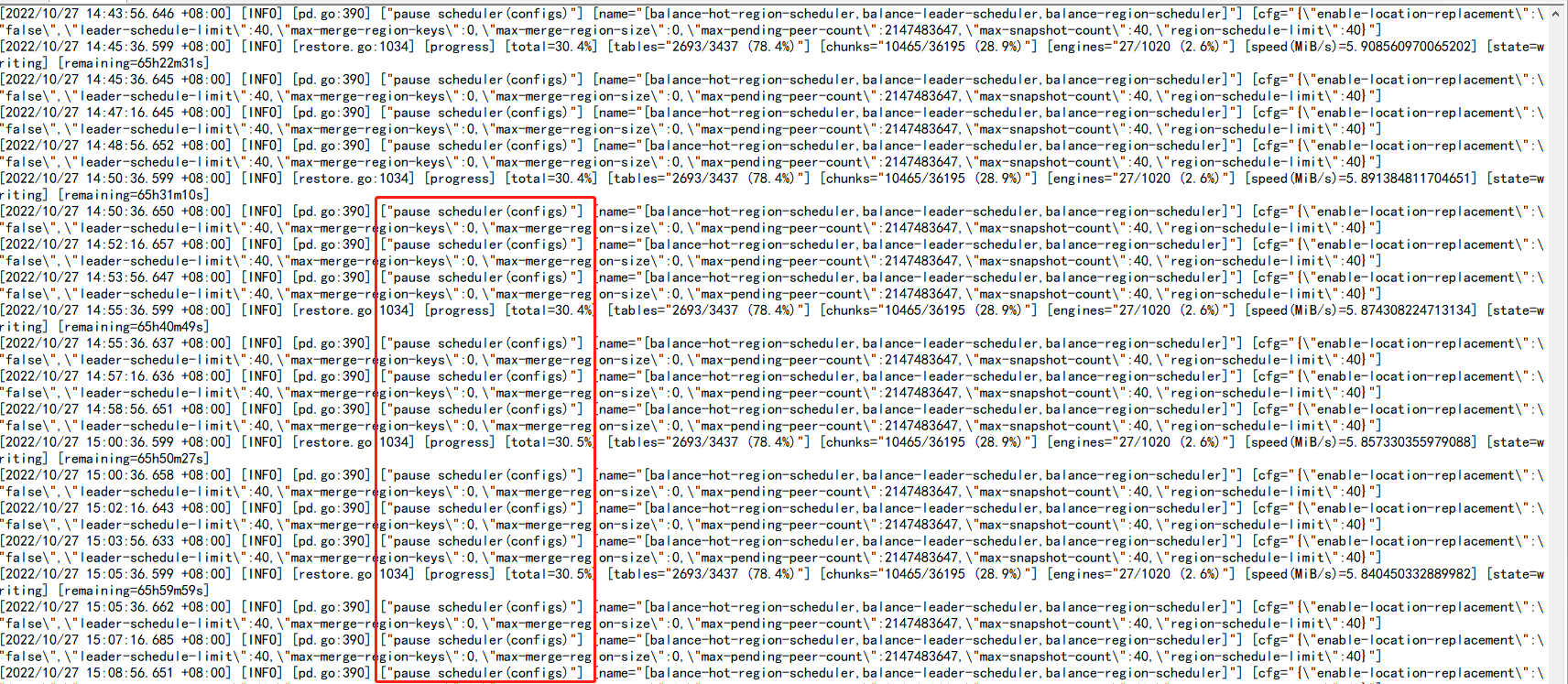
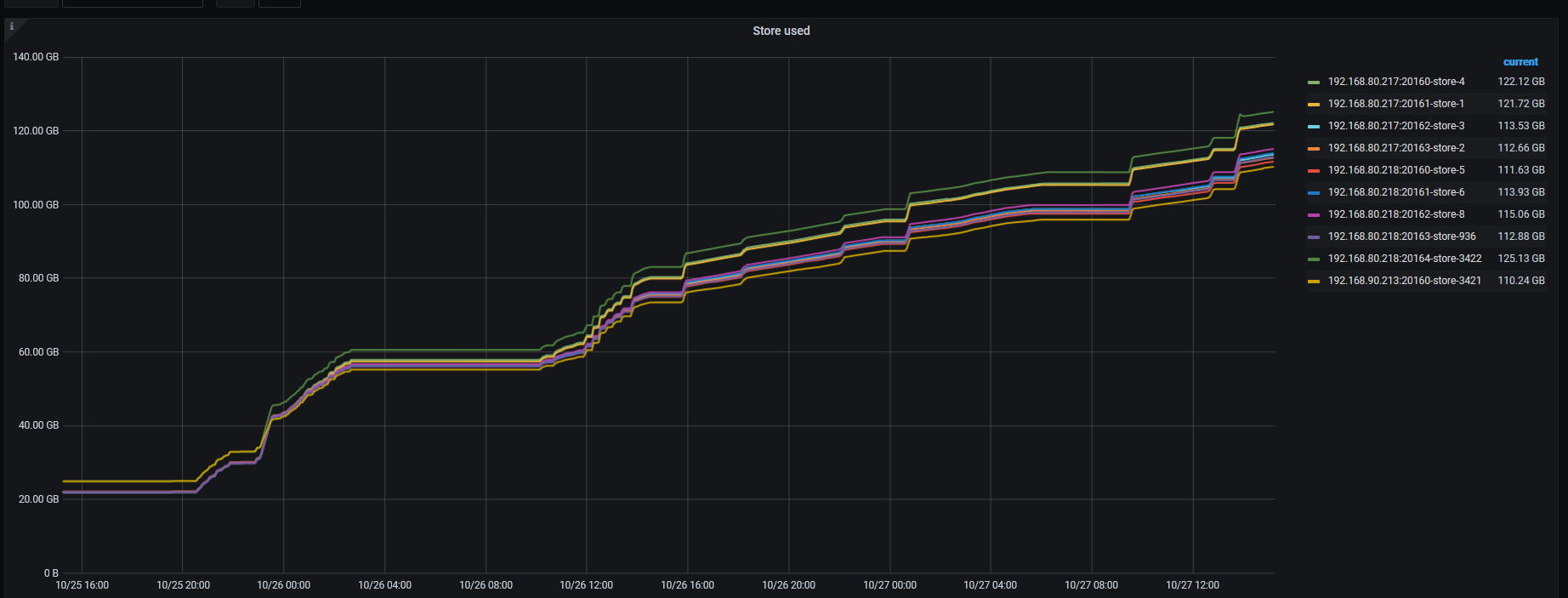
lightning导入时速率特别慢,一直在暂停调度操作;
两天一共上传的数据量如下
DC18服务器是tikv,也是lightning执行导入的服务器,内存一直很高,就把lightning的region 并发数那些都调低了,调高lightning进程隔段时间就会退出;
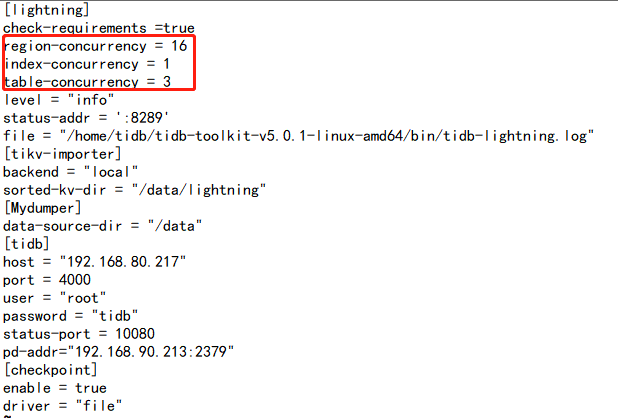
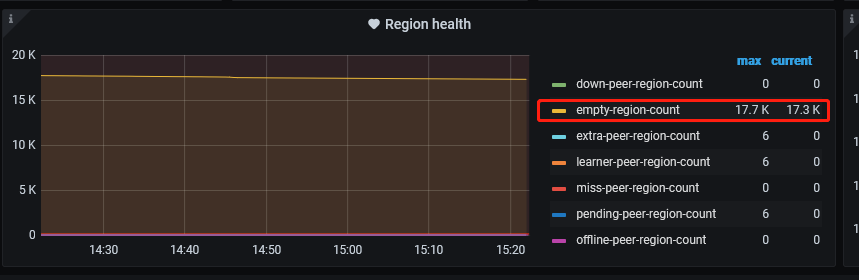
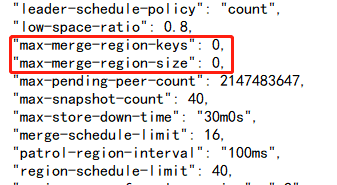
查看发现导入的集群空 region很多,将max-merge-region-keys max-merge-region-size调整后,lightning进程过一段时间就会触发pause 调度,空 region 数下降就会停止,再次查看该配置发现配置的参数就被清为0;
 有几个问题想咨询下:
有几个问题想咨询下:
1.lightning进程会增加empty region数吗?
2.empty region count加大会影响导入速率吗?
3.目前这种情况是什么原因造成导入速率过慢?怎么加快导入速率?
普罗米修斯
10
传输过程中有warn,写入kv时报错,能帮忙查看下吗,具体该怎么解决这个问题?
dumpling下了2.7T的数据,传了一个多礼拜了没传完,现在还写入报错了。能否看下导入速率非常慢的问题和写入报错的问题,感谢。可支付酬劳,在线业务比较紧急,求助。
tidb的默认配置 tikv的默认配置都是给独立机器用的 你要混合配置 得自己改参数 官方文档上有
Aric
(Jansu Dev)
14
-
查看发现导入的集群空 region很多,将max-merge-region-keys max-merge-region-size调整后,lightning进程过一段时间就会触发pause 调度,空 region 数下降就会停止,再次查看该配置发现配置的参数就被清为0;
→ lightning local 导入之前就是会暂定调度,暂停调度有利于快速导入,避免 merge or split 导致 region 、leader 变化。至于 XXX-keys 和 XXX-size 这 2 个参数归 0 之前处理过,正常情况下跟 lightning 异常退出有关,因为 lightning local 是先 pause schedule ,待导入完成后再 resume schedule。如果我没记错,应该是会在导入期间给 归 0。
-
dumpling全量下载了2.7T的数据,lightning全量导入create库和表已完成,在执行insert语句时执行了5个多小时,到2022/10/24 20:05后面就不动了。
→ 我看配置文件用的是 local 模式,应该没有 insert 语句的执行,是 csv–>sst–>tikv 文件直接导入
-
从 profile 我倒是没看出啥有用的信息,不过看截图里又出现过 tcp connection reset by peer 应该是 tcp 连接上有些问题。但至于他和导入性能有多大关系,不一定。 最好采一份可以看执行时间消耗的图,直接看卡在那个函数
curl http://{TiDBIP}:10080/debug/zip?seconds=60 --output debug.zip
说回来,查导入慢:
- lightning.log 没有任何异常点?
- 磁盘负载情况有没有看?
- 从 cpu idle 看本地翻译 csv → sst 的时候倒是没调起来多少性能,下游的 tikv 性能有看吗?
先扔上来一份 lightning 自身的 log 吧。 
btw:正常情况下,应该比这个速度低点 → https://docs.pingcap.com/zh/tidb/v4.0/tidb-lightning-backends#tidb-lightning-后端
普罗米修斯
15
1.lightning.log没看到啥异常点,全是INFO信息,现在有两个warn信息,写入kv时报错,您看下。
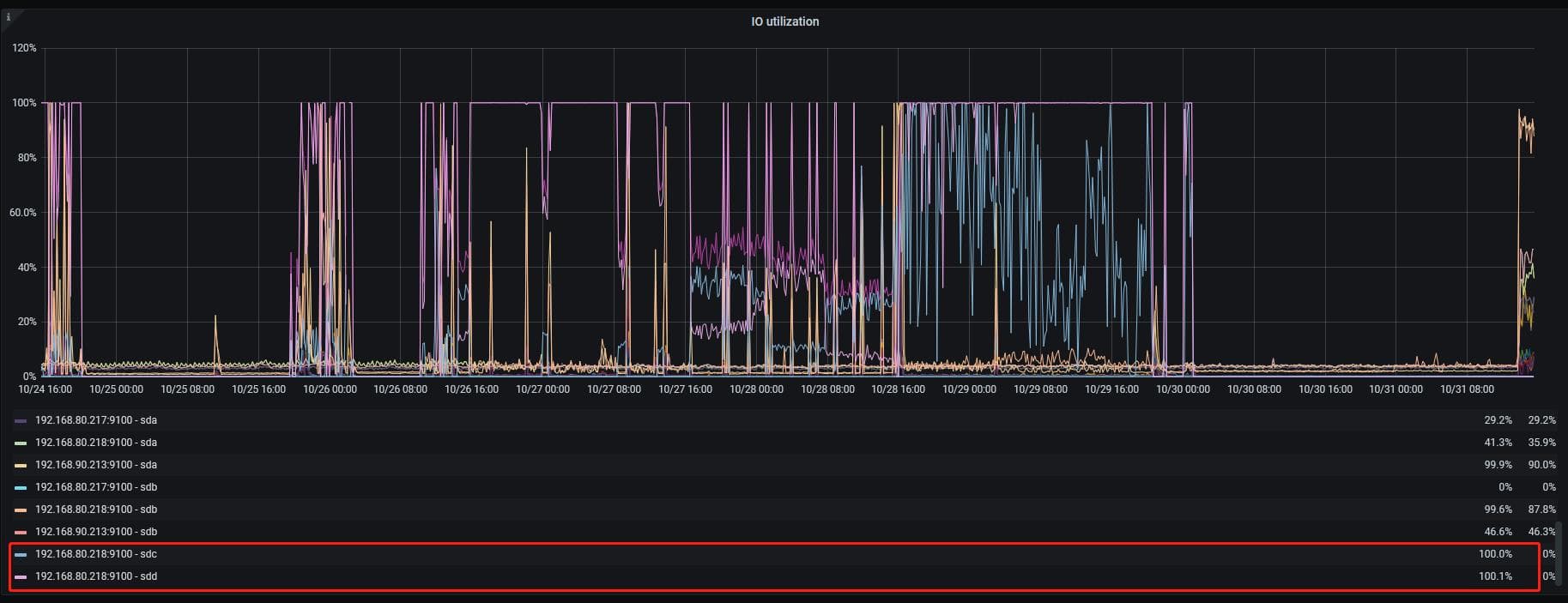
2.看了下磁盘负载确实很高
当时以为dumpling下载的数据很大,在192.168.80.218上,用lvm将sdd和sdc组成了一块盘符挂载到/data下,两块盘都是hdd,然后将lightningsorted-kv-dir也放在/data/lightning下,这两个盘IO跑到100%了,
192.168.90.213 的sda和192.168.80.218 的sdb是hdd机械盘,因为ssd盘符不够,将他两作为tikv节点使用了,也跑到99.9了,其他的盘符是ssd,跑的也比较高 都是90以上了,我是混合部署的,使用的默认配置,没有设置参数,是不和
readpool.unified.max-thread-count:
raftstore.capacity:
storage.block-cache.capacity:
参数还有关系。
192.168.80.217 192.168.80.218的内存跑的也比较高,
刚才群里说是tidb oom导致write ro tikv failed。
Aric
(Jansu Dev)
16
- 刚才群里说是tidb oom导致write ro tikv failed
tidb oom 不回导致 write ro tikv failed,不过 tikv oom 可能会导致该问题,至于是不是 oom,可以看下 /var/log/message 就能验证;
2.至于参数
a. raftstore.capacity → https://docs.pingcap.com/zh/tidb/v6.3/tikv-configuration-file#capacity-1
b. readpool.unified.max-thread-count → https://docs.pingcap.com/zh/tidb/v6.3/tikv-configuration-file#max-thread-count
c. storage.block-cache.capacity → https://docs.pingcap.com/zh/tidb/v6.3/tikv-configuration-file#capacity
d. readpool.unified.max-thread-count 相关性不大。如果说 tikv 真的 oom 那么降低 storage.block-cache.capacity 会一定程度降低 OOM 的概率。raftstore.capacity 主要看你的 store 存储是否快达到了上限,不过磁盘看用的存储还是比较小的。这是 k8 吗,怎么感觉面板不太熟悉😂
- 该报错,sst 写 tikv 出现问题,照着这个思路查吧🤔.
你去群里看看他的聊天记录 一台机器里面部署了4个tikv 1个tidb 配置也没改 几个tikv之间相互抢占内存。oom选一个内存最大的kill掉。systemctl 再把kill掉的tikv调起来 这就是他的问题。
所以你看到他的图是几小时内不停的重启oom 重启oom 重启oom 内存不够的原因。一个tikv的cache默认占用内存总量的40% 他启动2个就会oom了 别说他启动4个
普罗米修斯
19
1.这个是lightning的日志,您看下;
tidb-lightning.log (2.2 MB)
2.查看了下游服务器/var/log/message日志,确实是tikv OOM了,
,服务器负载太高,192.168.80.218服务器有5个tikv节点,现在将一台tikv下线减少负载,然后重新添加上面混合部署的参数试下。
3.之前以为dumpling下载的数据很大,在192.168.80.218上用lvm将sdd和sdc组成了一块盘符挂载到/data下,两块盘都是hdd,然后将lightning sorted-kv-dir也放在/data/lightning下,这两个盘IO跑到100%了,是不要将lightning和dumpling的不能放在同一个目录 ;
如果分开的话在tidb.lightning.toml配置文件中将sorted-kv-dir重新指定,将lightning目录剩余的数据拷贝过去,重启lightning.sh就行了是吧。

4.重启的lightning服务的话是直接sh lightning脚本吗,还是需要清除断点信息了什么其他的操作;