danteair
(Ti D Ber Uzzqmfdt)
1
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.3.2
【遇到的问题】kv节点leader数量不均衡,查询某些特定表会出现region unavailable的报错。
【复现路径】无法确定
【问题现象及影响】
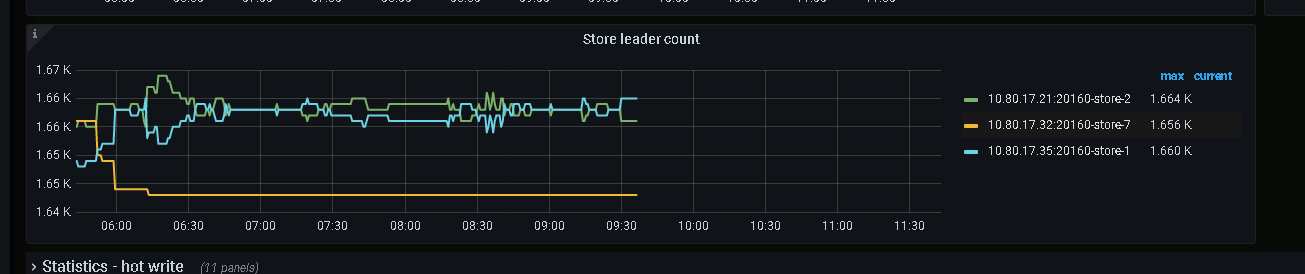
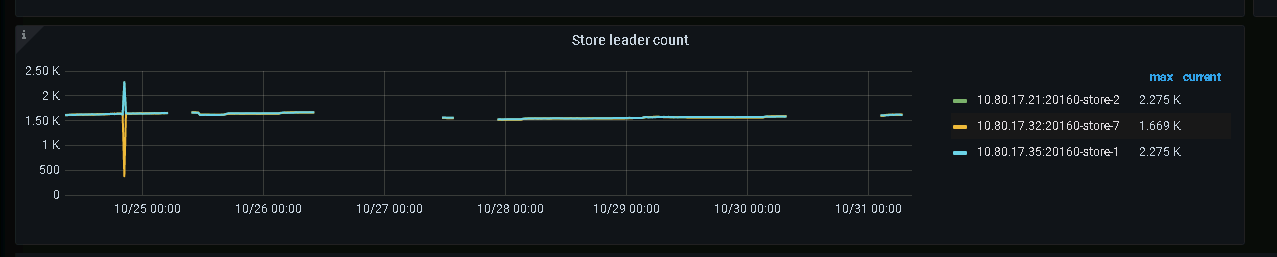
kv监控看到leader数量出现问题,节点之间无法回到平衡状态,且32节点几乎接收到了所有的leader。
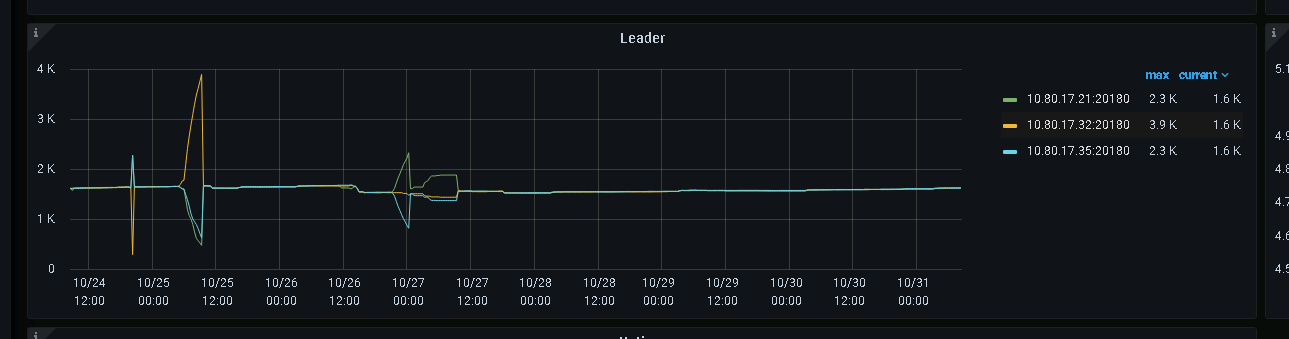
从pd的监控页面,看到pd在这个期间发生了leader迁移,从pd leader节点监控面板看到的kv leader数量分布与kv监控中的leader数量分布不一致,似乎是这个不一致导致了32节点持续接收到其他两个节点transfer过来的leader。
为什么会发生这样的情况?之前就已经出现过几次这样的问题了,通过重启pd节点所在服务器可以临时解决该问题,但是没有找到导致kv leader还是会变的分布不均衡的原因(或者说是pd节点读取到的kv leader分布不正确的原因)
目前的推测是和磁盘读取有关(读取不到或者读取太慢),节点之间网络延迟未见明显异常或中断。
【附件】
kv监控面板的leader分布:
pd监控面板的leader分布:
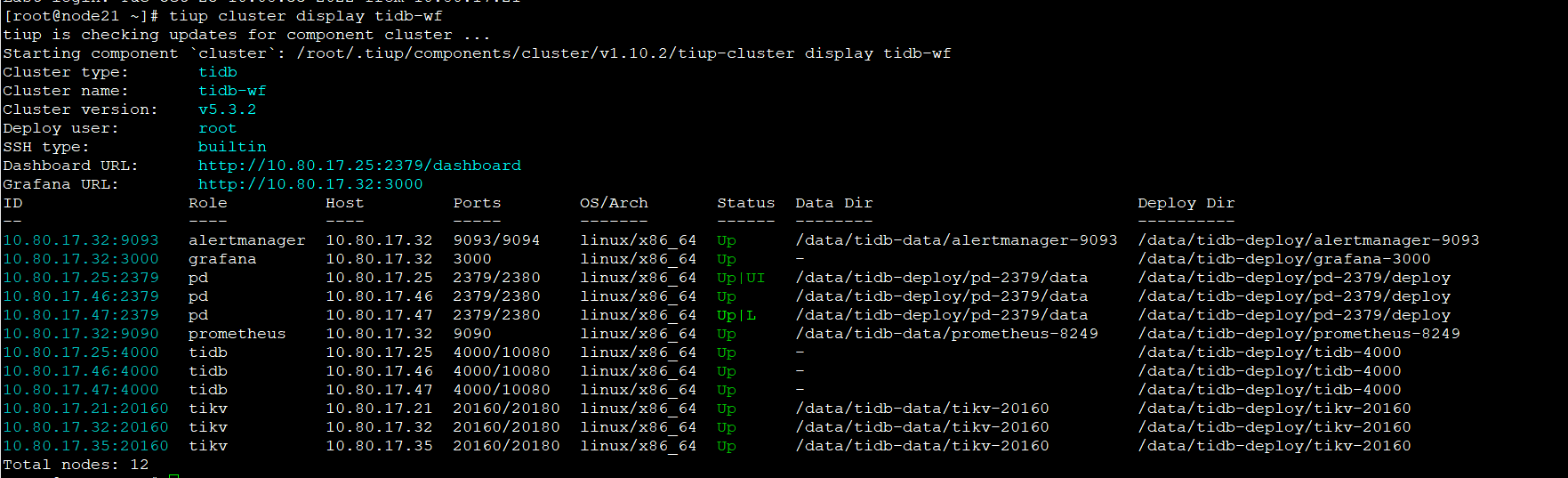
TiUP Cluster Display 信息
danteair
(Ti D Ber Uzzqmfdt)
2
pd-47-cut.txt (4.1 MB)
pd-25-cut.txt (9.4 MB)
两台pd5点左右的日志
h5n1
(H5n1)
3
https://metricstool.pingcap.com/#backup-with-dev-tools
按这个操作,把pd 、 tikv、overview、node exporter的监控导出下,要expand所有面板并等数据加载完。
6点钟的时候有什么定时任务吗
danteair
(Ti D Ber Uzzqmfdt)
5
其实从凌晨三点开始一直有一些统计sql在执行,包括一些比较复杂的group by查询逻辑以及百万级别的insert逻辑,稍后导出一下日志
danteair
(Ti D Ber Uzzqmfdt)
6
h5n1
(H5n1)
7
pd 、node exporter的没数据 要等数据加载完再导出文件 可以拉到底等会 。 tikv导出tikv detail. 另外那个32节点6点前后tikv.log也上传下
danteair
(Ti D Ber Uzzqmfdt)
8
node exporter有好几个节点似乎一直导不出来数据
tidb导出json新.rar (4.0 MB)
tikv-32-cut.txt (6.1 MB)
h5n1
(H5n1)
9
目前看到的几个问题:
1、 5.01分发生过pd leader切换,25节点成为leader,应该是磁盘慢的问题。
[2022/10/25 05:00:30.858 +08:00] [WARN] [wal.go:712] [“slow fdatasync”] [took=2.426173237s] [expected-duration=1s]
[2022/10/25 05:00:30.858 +08:00] [WARN] [raft.go:363] [“leader failed to send out heartbeat on time; took too long, leader is overloaded likely from slow disk”] [to=a8a1d6bded45bf4b] [heartbeat-interval=500ms] [expected-duration=1s] [exceeded-duration=1.471525001s]
在成为Leader的这段时间PD上很多监控项没有数据。应该和tikv通信有问题
[2022/10/25 05:01:30.546 +08:00] [ERROR] [client.go:171] [“region sync with leader meet error”] [error=“[PD:grpc:ErrGRPCRecv]rpc error: code = Canceled desc = context canceled”]
2、25节点成为leader期间store2(17.21)、store 1(17.35)往store7(17.32)上的transfer leader调度都不能正常完成,都超时了,猜测和tikv繁忙有关。 但是后续从store7 往1、2上的调度都能成功
具体原因等官方大佬来分析 @neilshen
1 个赞
danteair
(Ti D Ber Uzzqmfdt)
10
感谢大佬的分析
关于第一点,看磁盘的监控的话,磁盘的延迟是比较高的,三个store节点都有比较高的延迟,这也是和定时任务执行的逻辑有关,磁盘有比较大的压力。很有可能就是因为这个导致了pd leader的切换吧。
关于第二点,如果说store2、store1往store7上的调度不能正常完成的话,store7的leader数量又为什么会增加呢?(kv监控面板上看到的是store2、store1上的leader在减少,store 7的leader数量在增加)pd日志里面,在pd leader切到25节点以后,25节点发出了很多transfer leader的调度,这些调度发起的原因又是什么呢?
danteair
(Ti D Ber Uzzqmfdt)
11
或者说是pd上收到的是transfer leader调度失败,所以25这个pd节点认为的store 7节点kv leader数量一直都是少的,从而持续不断的发起了新的调度,最终让store 7节点持续的收到了其他两台store节点transfer过来的leader?
h5n1
(H5n1)
12
transfer leader 主要还是因为均衡调度。为什么会timeoout可以把那2个节点的tikv.log传上来看看。
danteair
(Ti D Ber Uzzqmfdt)
13
tikv-21-cut.txt (8.0 MB)
tikv-35-cut.txt (8.8 MB)
其他两个store节点的log
neilshen
(Neil Shen)
15
2 个赞
danteair
(Ti D Ber Uzzqmfdt)
16
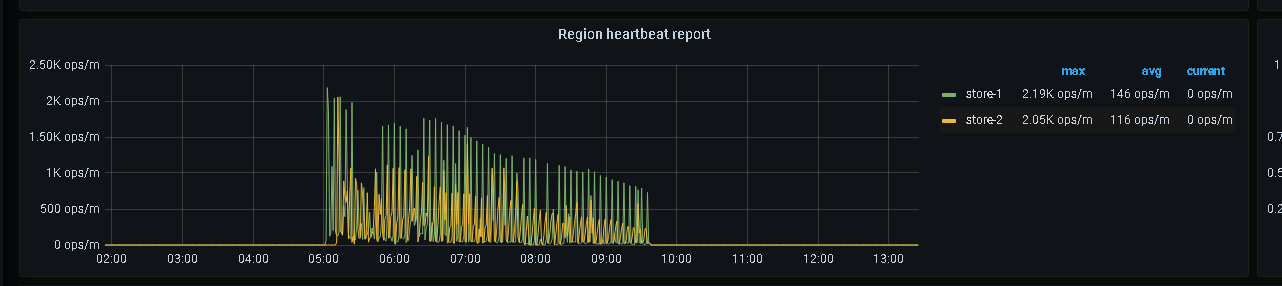
感谢大佬的指导,从release note来看,比较符合我们遇到的情况,看region heartbeat report面板的话,确实pd leader切换到25节点以后,store 7的region heartbeat就一直没有接收到,而在pd leader切换到25前后,三个store节点的heartbeat都是正常的
后续我们升级一下tidb版本再跟进看一看还会不会复现该问题
danteair
(Ti D Ber Uzzqmfdt)
18
更新,10月27号升级了tidb以后目前没有再出现问题
期间pd leader经历过至少四次leader切换吧
已解决的问题尽量不要去回复灌水内容,这样子会把原来已解决的问题又暴露出来,会给帮助解决问题的小伙伴制造混乱,扰乱其他小伙伴注意力哟~