HTAP萌新
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】学术研究
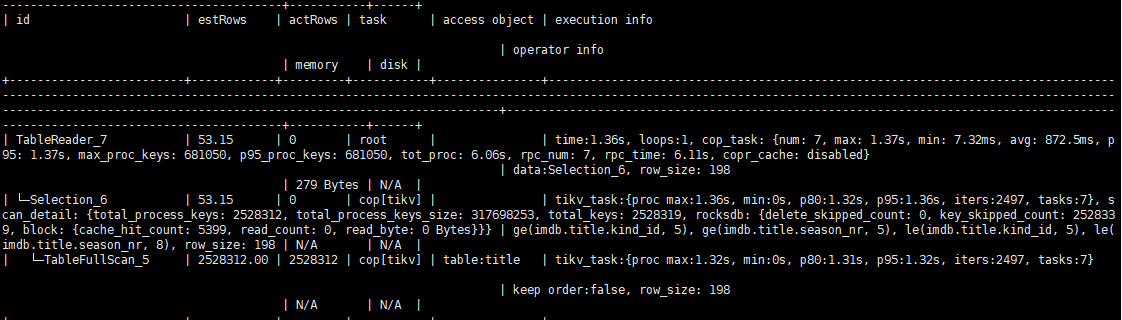
【概述】 使用EXPLAIN ANALYZE观察Tidb的执行计划,发现cop_task的tot_proc时间比该算子(甚至该算子的父算子)执行时间还短,有点不符合直觉。如下图中Table_Reader算子的执行时间是1.56秒,而cop_task的tot_proc高达6.06s。是否因为有多个TiKV实例同时处理?
下图的Index_Reader_11和HashAgg_10算子同样存在cop_task执行时间(452ms)比该节点以及父节点执行时间(275ms)还长的现象
【背景】 explain analyze
【TiDB 版本】 5.3
【应用软件及版本】
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息 3个TiKV实例
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
h5n1
(H5n1)
2
cop task的统计里有累计的值,tidb一次发送dist-scan-concurrency个cop task在tikv并行执行,按第2个看,tidb下发2个 cop task ,tikv执行是2个tikv_task: 272ms+180ms正好是index_reader的tot_proc时间。因为2个tikv_task所以index_reader算子的时间就是最大tikv_task返回时间+其他的一些处理时间(应该就是tot_wait)
HTAP萌新
3
明白了,那再请问一下这两个cop_task是在两个TiKV节点上执行吗?还是在同一节点上并行?
h5n1
(H5n1)
4
看region分布,一个region一个cop task
HTAP萌新
5
那可不可以指定让cop_task串行呢?或者有序执行
h5n1
(H5n1)
6
可以设置tidb_distsql_scan_concurrency tidb_index_lookup_concurrency tidb_index_lookup_join_concurrency tidb_executor_concurrency 这些参数都是1,
1 个赞
在我设置这些参数均为1后,是否还能获取单个算子的执行时间呢?因为串行,所以index_reader算子的时间不再是最大tikv_task返回时间+其他的一些处理时间,而是各个task的和,而目前只有max min p95和p80统计值
HTAP萌新
11
好的~所以从explain analyze的执行信息里是看不到的对吧
system
(system)
关闭
12
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。