为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 相关信息】
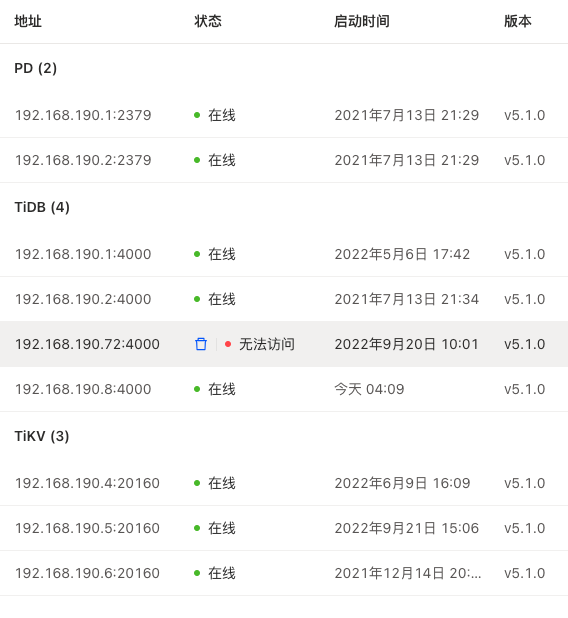
TiDB V5.1.0 两个PD,两个tidb,三个tikv
【现象问题】
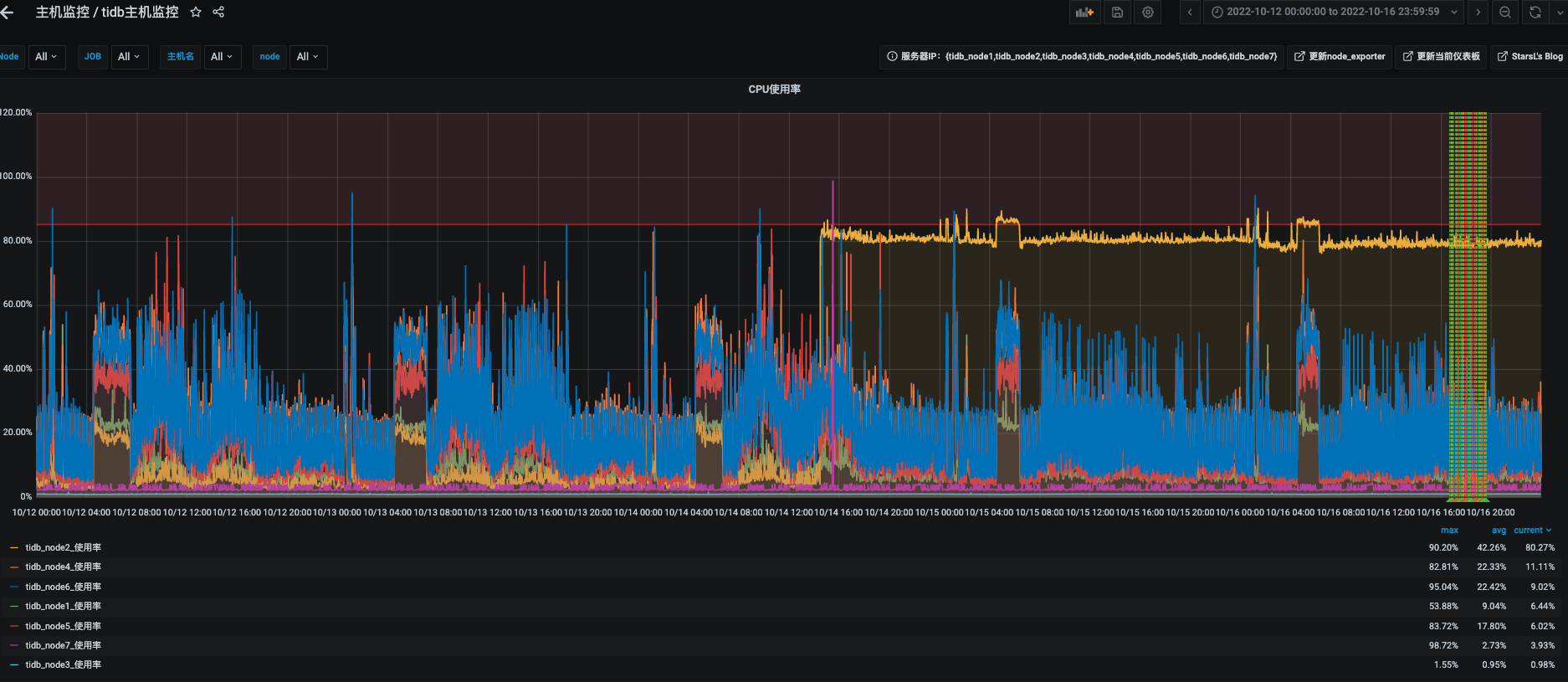
10.14号下午2点,TiDB tidb的其中一个节点报cpu超过阈值,之后一直居高不下。
【问题告警截图】
节点CPU监控图
节点top实时图

Grafana TiDB监控信息图
【问题求助】
CPU暴增如何排查?如何找到造成CPU暴增的根本原因?
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 相关信息】
TiDB V5.1.0 两个PD,两个tidb,三个tikv
【现象问题】
10.14号下午2点,TiDB tidb的其中一个节点报cpu超过阈值,之后一直居高不下。
【问题告警截图】
节点CPU监控图
【问题求助】
CPU暴增如何排查?如何找到造成CPU暴增的根本原因?
tidb的cpu暴增一般都是慢查询引起的,可以看看当前节点有没有慢查询或锁产生
另外需要看下自动analyze有没有失败的场景,是怎么配置的
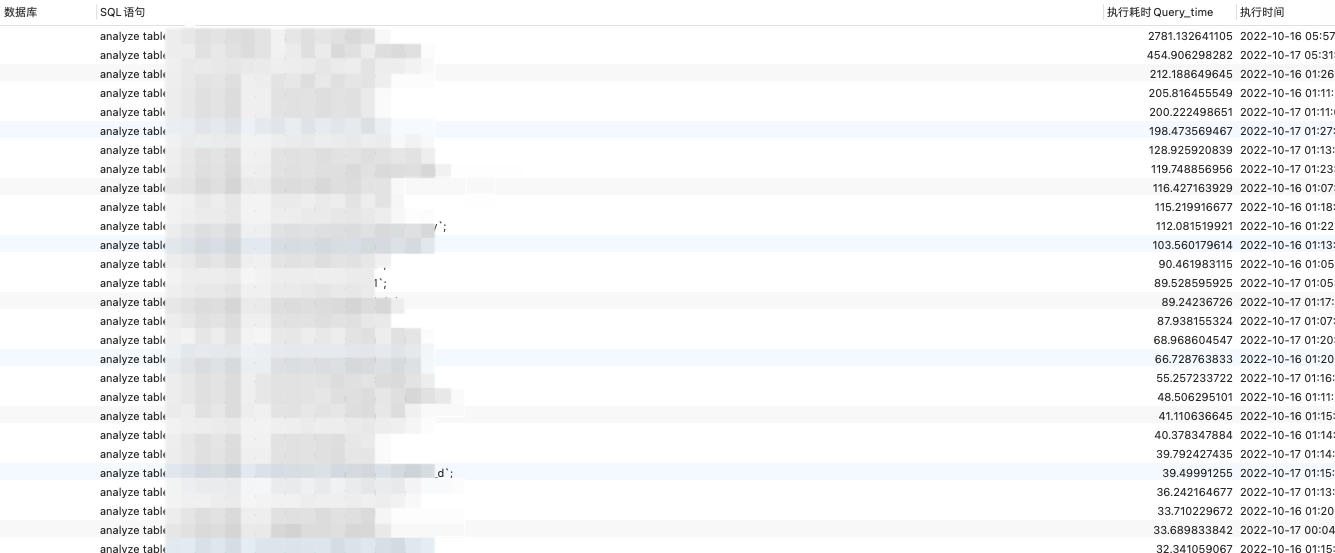
这是查询出来的慢SQL。
SELECT
DB AS '数据库',
`Query` AS 'SQL语句',
Query_time AS '执行耗时Query_time',
Time AS '执行时间',
`User` AS '执行用户',
`Host` AS '主机',
Total_keys AS '扫描总Key个数Total_keys',
Index_names AS '涉及索引名'
FROM
INFORMATION_SCHEMA.SLOW_QUERY
ORDER BY
Query_time DESC
LIMIT 100;
1.show variables analyze看下结果,如果是analyze引起的可以调整下analyze的启动和终止时间范围
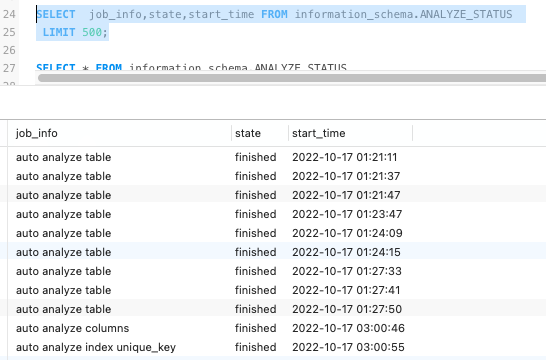
2.另外用show analyze status;或者SELECT * FROM information_schema.ANALYZE_STATUS;查看下是否有失败的自动analyze导致
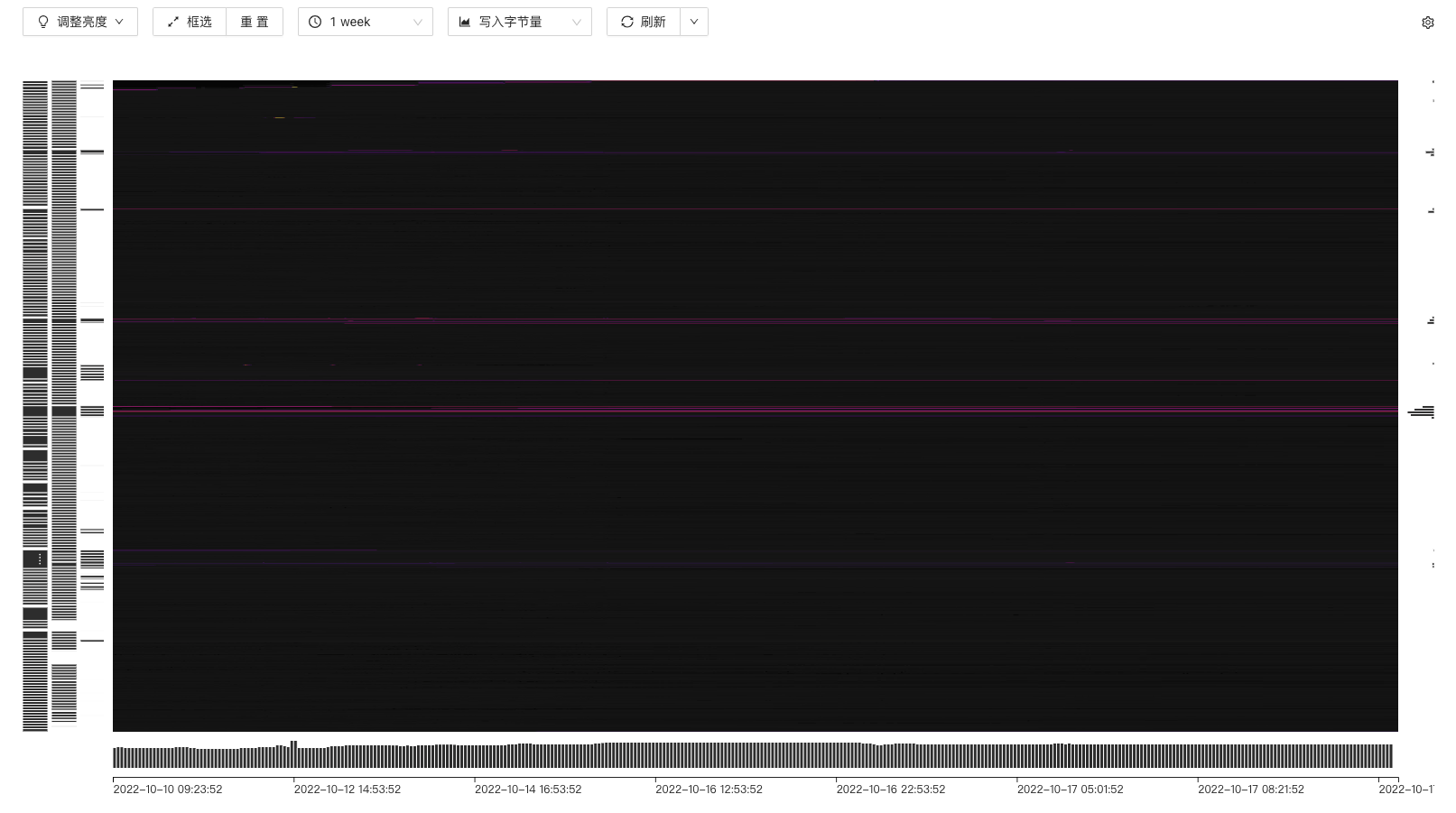
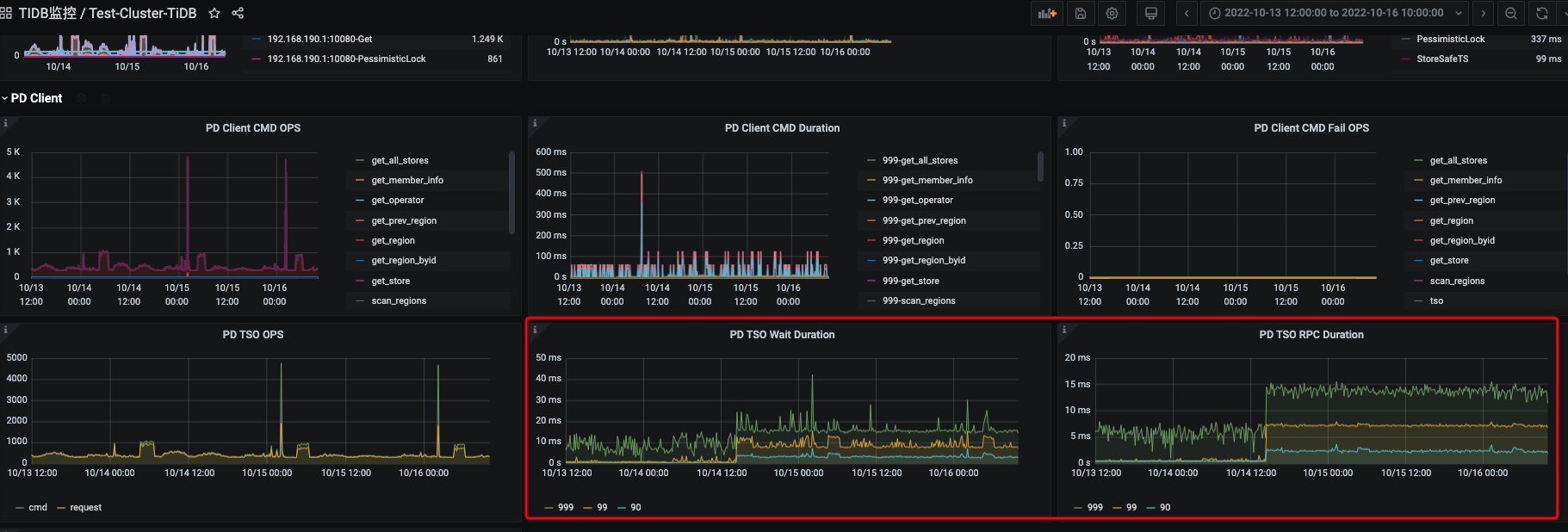
3.通过dashboard的热力图查看下是否有读热点问题
1:
show variables like '%ANALYZE%' 显示无相关变量及配置。

2:
SELECT job_info,state,start_time FROM information_schema.ANALYZE_STATUS LIMIT 500;查询结果,都是finished的job
3:热力图
1.analyze是小写不是大写
2.目前看起来不是失败的analyze导致的
3.写入字节量那里改成所有或者读取相关的两个
有两个建议你可以试着调整下:
1.把tidb_analyze_version改成1,这是因为在5.1版本2是实验特性,有些问题,记得当时有几个issue应该和这个有关
2.把end_time和start_time缩短一些,可以设置为业务低峰期的一到两个小时,改完后看下结果
好的,多谢
客气了,弄完可以观测下有没有效果
本质是tidboom 原因是数据有问题。sql是慢sql
查询到了有大量的慢SQL。想手动杀掉这些进程看CPU是否能下降,但又遇到了另外一个问题。kill tidb + 进程号,杀不掉。 ![]() 相关问题链接:show processlist的进程号杀不掉,且sleep时间超过time_out的限制时间,为什么不断开 - #3,来自 Harbin70KG
相关问题链接:show processlist的进程号杀不掉,且sleep时间超过time_out的限制时间,为什么不断开 - #3,来自 Harbin70KG
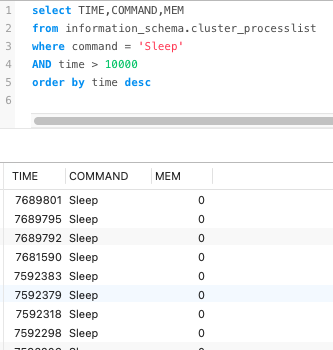
如果是在对应的instance(在sql对应的tidb上做kill tidb上杀不掉的话)那就是遇到了一个bug,我是用重启tidb节点来解决的
慢sql要从优化得方向去处理,加索引,或者改sql得逻辑和写法,总之从tikv返回tidb server得数据量尽量少,或者前端做流控
OK,今晚试试重启那个节点试试
但凡计算复杂度高点的数据操作,开发能用SQL解决的,坚决不想写代码解决。他们只会说,为什么数据库性能这么差 ![]()
找领导多跟开发沟通,运维与开发断层,各自忙各自的,会让应用系统和数据库都出现问题。制定开发规范,开发测试、压力测试,DBA都要介入
哈哈,都想省事
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。