【 TiDB 使用环境】生产环境
【 TiDB 版本】 tidb v6.1.0
【遇到的问题】 监控磁盘使用空间比较大,不释放
prometheus-8249/data目录下,docdb占用空间356G,如何清理
du -sh *
5.4G 01GF3S30F4GWWBT1R4P4ZESEZ3
1.9G 01GF4DMK79JTYFTDMG33F42FS6
682M 01GF7G5KMM3GDXB1B7WG9V4464
1.9G 01GF7G81CTWDG0JETNWX9KYM03
2.8M chunks_head
356G docdb
0 lock
20K queries.active
164K tsdb
1.2G wal
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
buddyyuan
(Buddyyuan)
4
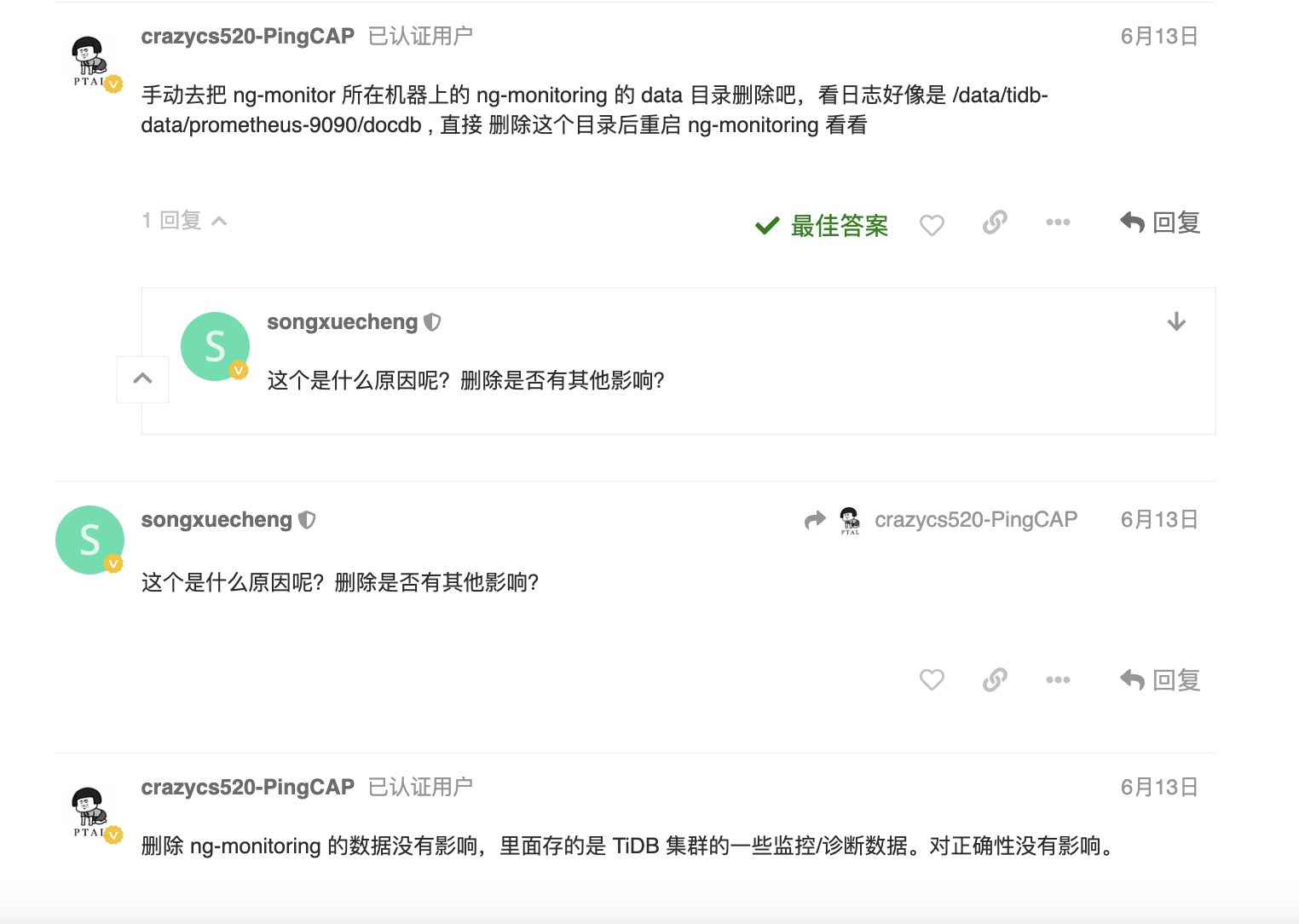
这个目录好像是 NgMonitoring, NgMonitoring 是 TiDB v5.4.0 及以上集群中内置的高级监控组件,用于支撑 TiDB Dashboard 的 持续性能分析 和 Top SQL 等功能。使用较新版本 TiUP 部署或升级集群时,NgMonitoring 会自动部署;
1 个赞
习惯上,先缩容监控节点,再扩容监控节点。
1. 优缺点
2. 步骤
以缩、扩容集群 kruidb 的监控节点 alertmanager、grafana、prometheus 为例:
2.1 缩容
- 语法格式:
tiup cluster scale-in kruidb-cluster -N <监控节点IP:端口>
- 缩容命令:
~]$ tiup cluster scale-in kruidb -N 192.168.3.220:9093 -N 192.168.3.220:3000 -N 192.168.3.220:9090
2.2 扩容
- 编写扩容配置文件 monitor.yaml
monitored:
node_exporter_port: 9100
blackbox_exporter_port: 9115
monitoring_servers:
- host: 192.168.3.220
grafana_servers:
- host: 192.168.3.220
alertmanager_servers:
- host: 192.168.3.220
- 执行扩容
## 1. 检查
tiup cluster check kruidb monitor.yaml --cluster
## 2. 修复
tiup cluster check kruidb monitor.yaml --cluster --apply --user root -p
## 3. 执行扩容
tiup cluster scale-out kruidb monitor.yaml
3. 注意事项
以上操作,已在 TiDB v6.1.0 中验证。希望对您遇到的问题能提供帮助。
tiup 1.10.2 增加了 timezone 的检查,在执行 check 时可能会报 timezone Fail no pd found, auto fixing not supported ,是个已知的问题,不影响扩容。tiup 1.9 中无此问题。
1、docdb这个目录我删除了,然后重启服务prometheus,
3、2天前把prometheus服务删除,重建,才两天时间docdb占用空间 450G,把磁盘空间打满,总是删除目录应该没有从根本解决问题
buddyyuan
(Buddyyuan)
8
NgMonitoring 是 TiDB v5.4.0 及以上集群中内置的高级监控组件,用于支撑 TiDB Dashboard 的 持续性能分析 和 Top SQL 等功能 。
你把这些功能关闭掉就行了。
1 个赞
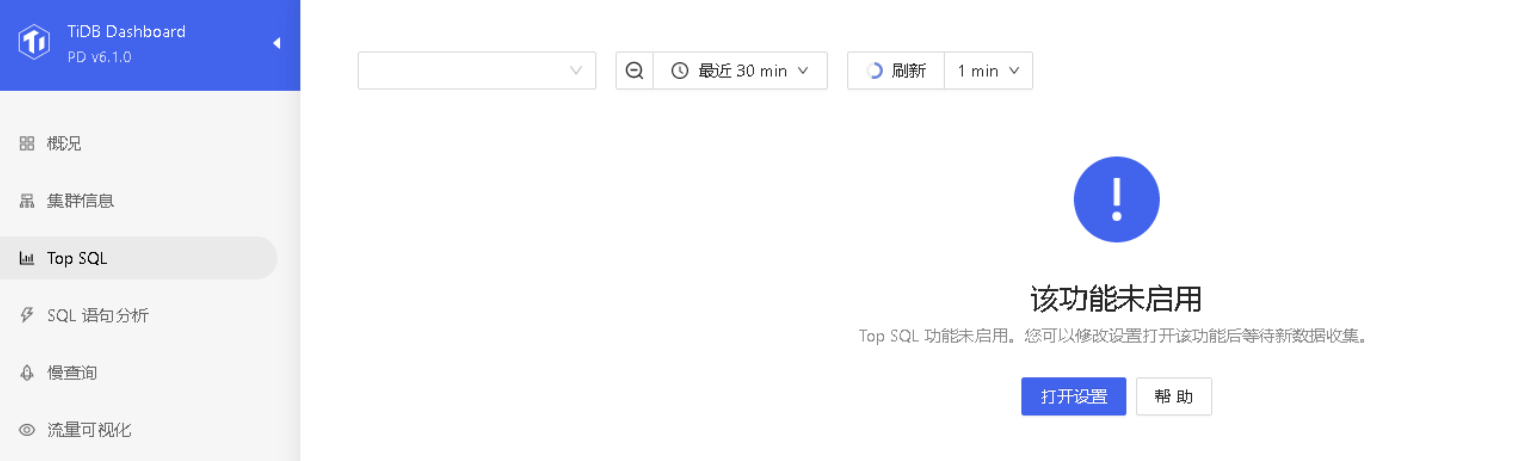
2天前删除docdb,然后重启prometheus服务,今天查看docdb 284G ,关键是top sql功能未启用状态
buddyyuan
(Buddyyuan)
10
你找下dashboard界面上的持续性能分析,也要关掉。
1 个赞