【 TiDB 使用环境`】生产
【复现路径】做过哪些操作出现的问题
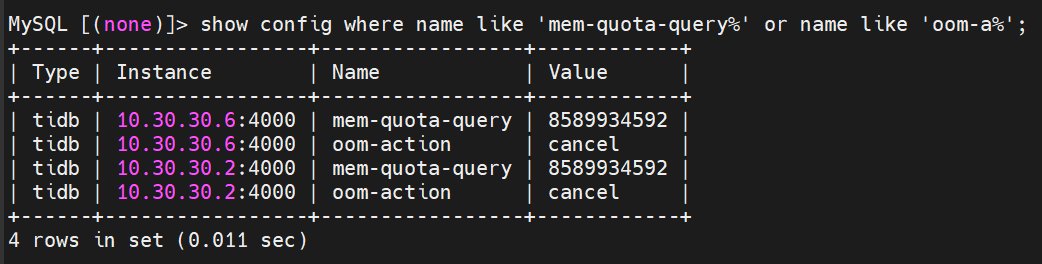
tidb 集群的tidb节点内存一直增大 直到被oom kill,就是不回收内存,之前都是正常的 ,开发确认没上线新功能,tidb 日志里面expensivequery 最大也就是700M左右的 sql 不是单独一个sql导致的 几个小时以后就oom了
gc相关的参数调整,最好再发点tidb的内存监控图看看
1.查一下大SQL是否较多?echo "GODEBUG=madvdontneed=1">>/etc/profile,以调整GO 语言内存释放策略。
gc 相关参数 我看了下 基本都是对tikv 节点设置的 都是默认设置没有修改过
WalterWj
2022 年10 月 10 日 04:46
7
tidb 官网看下内存控制,可以尝试配置 oom action
cat run_tidb.sh
#!/bin/bash
set -e
# WARNING: This file was auto-generated. Do not edit!
# All your edit might be overwritten!
DEPLOY_DIR=xxx
cd "${DEPLOY_DIR}" || exit 1
exec env GODEBUG=madvdontneed=1 bin/tidb-server \
buddyyuan
2022 年10 月 10 日 06:12
8
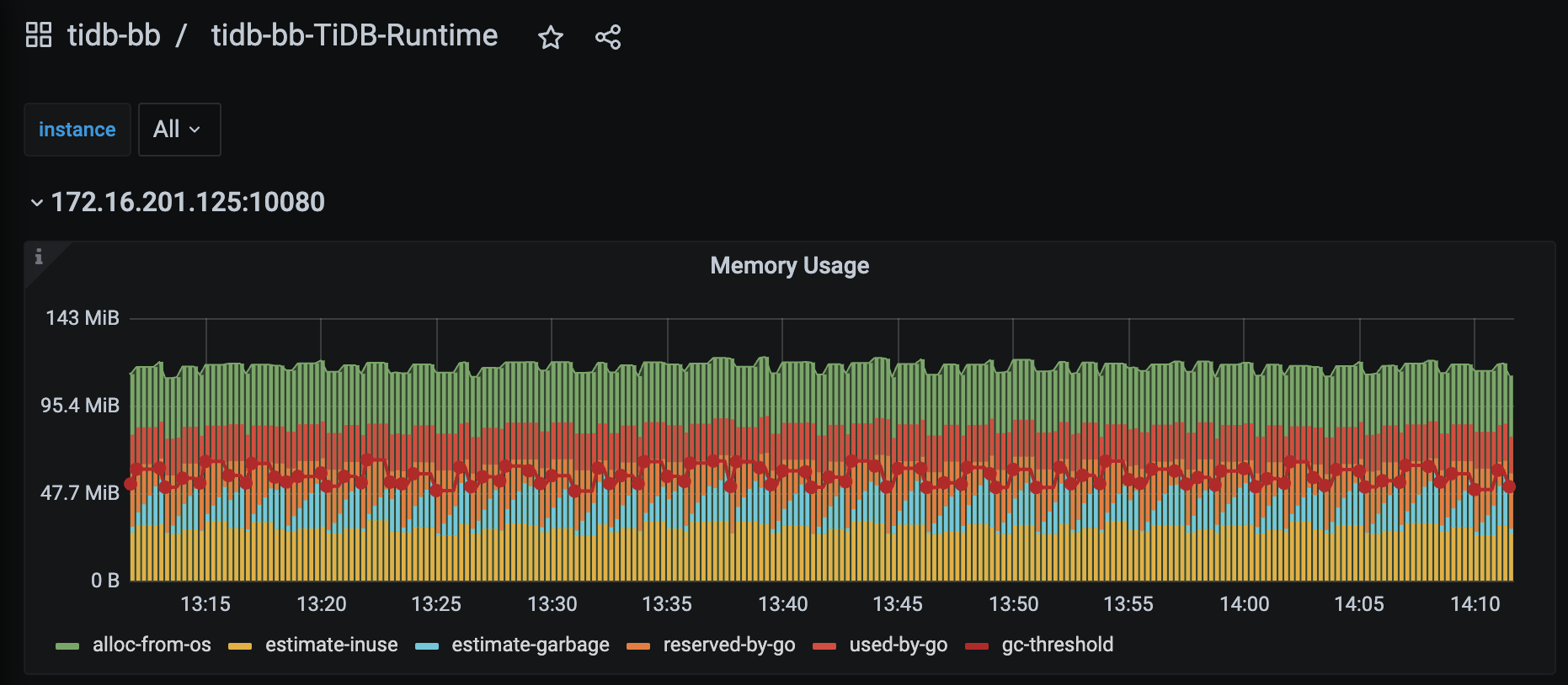
麻烦上传一下 runtime 中的 memory usage的图。
buddyyuan
2022 年10 月 10 日 06:20
10
Go 的内存管理可以算是两层的,执行垃圾回收以后,没有用到的内存会归还给 Go 的 runtime,这是一层。然后 Go 的 runtime 什么时候把没有使用到的内存,再归还给操作系统,这是第二层。 你得看看内存不释放问题,发生在第一层还是第二层,即 Go 的 runtime 没有及时地把内存归还给操作系统。
oom_action 默认就是cancel 默认大小是1G 1G太小就修改到8G了 但是是很久以前修改的了,目前没有看到 有单条sql 超过2G 的 8G的也没有了,内存是一点一点涨上去的
WalterWj
2022 年10 月 10 日 06:33
13
找下对应 SQL 在慢日志中记录,最终是否执行成功,慢日志中有个字段可以代表。
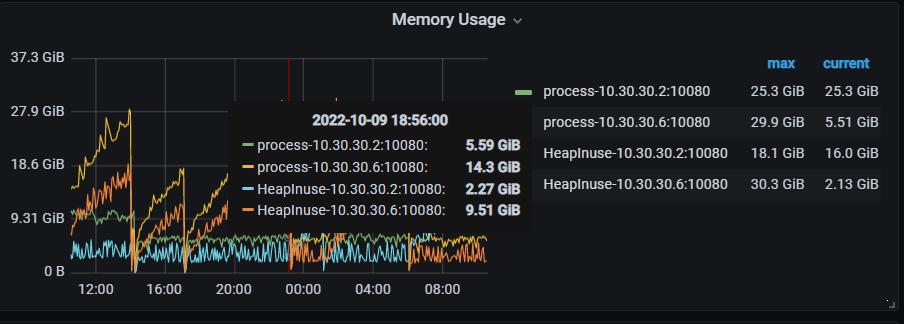
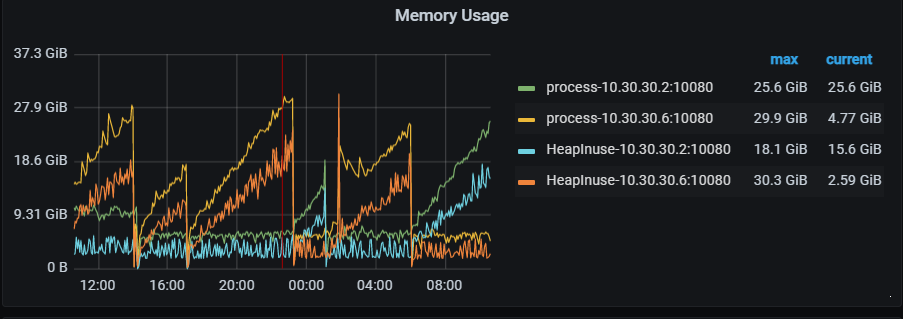
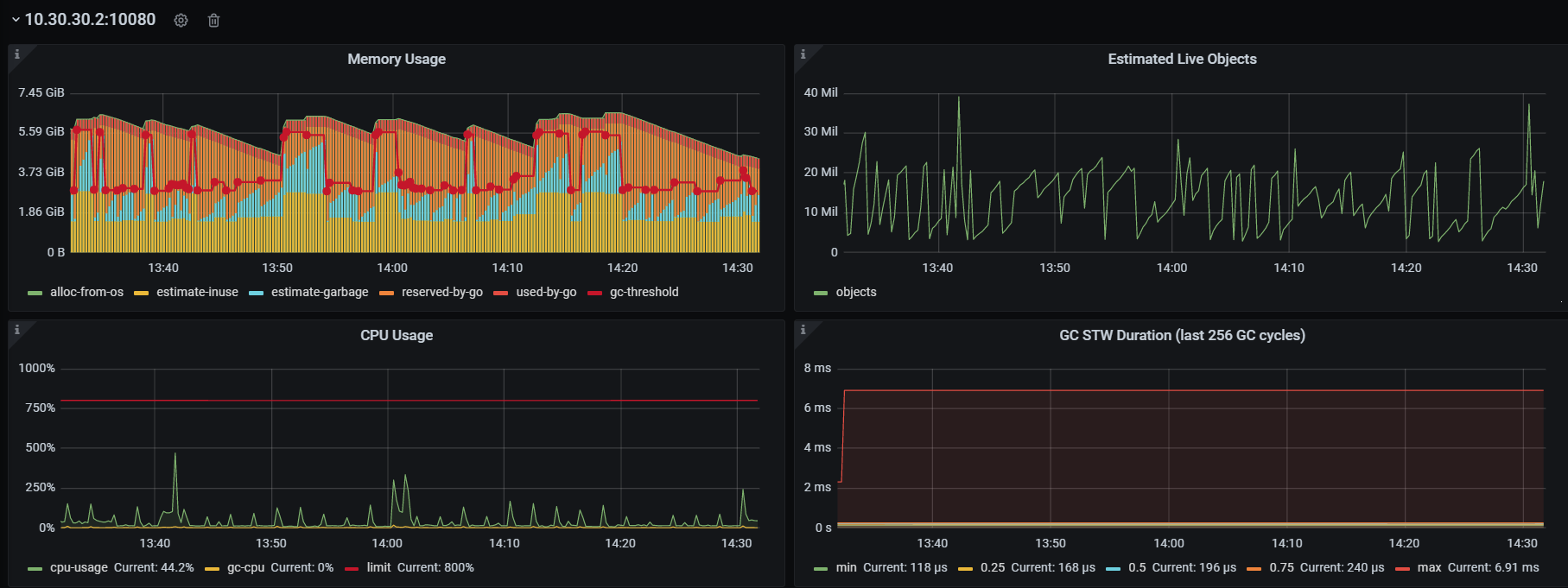
第一个节点的:
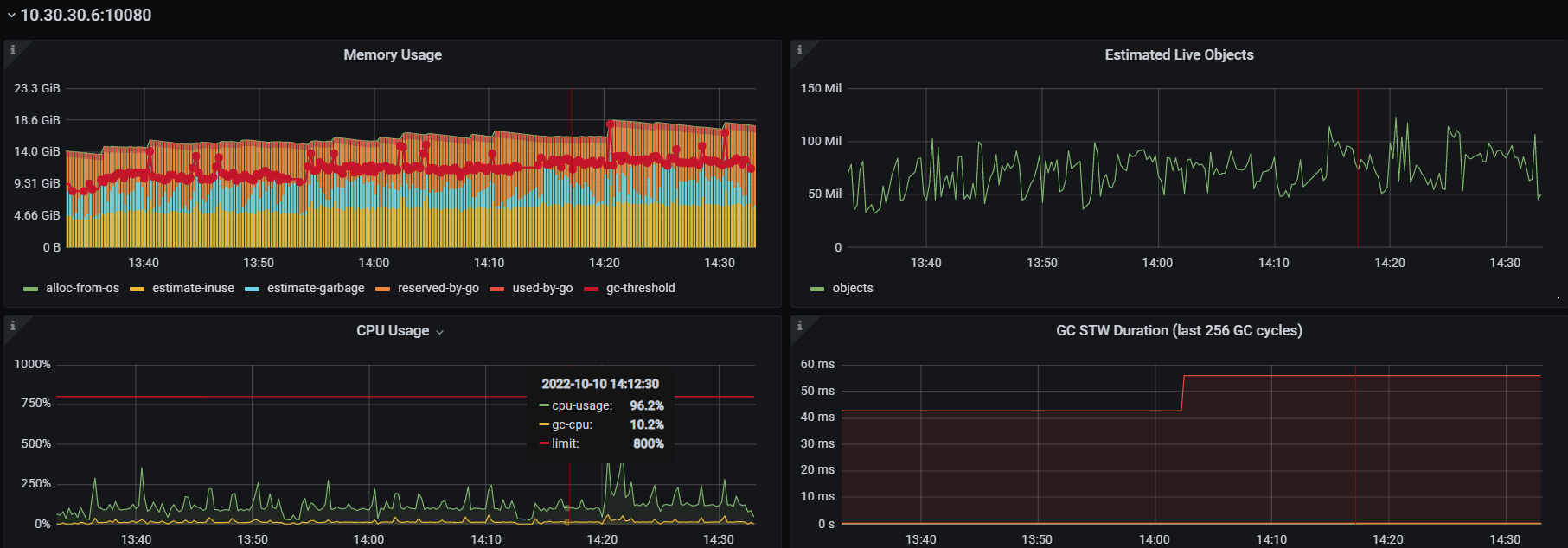
第二个节点:
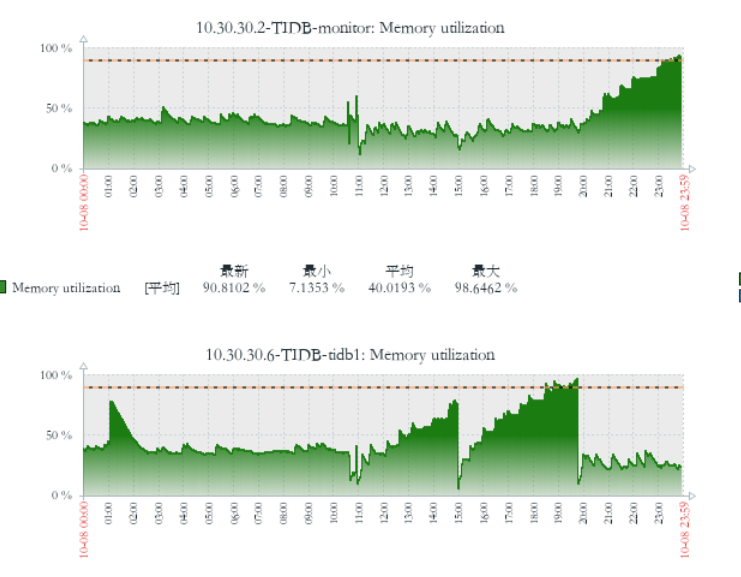
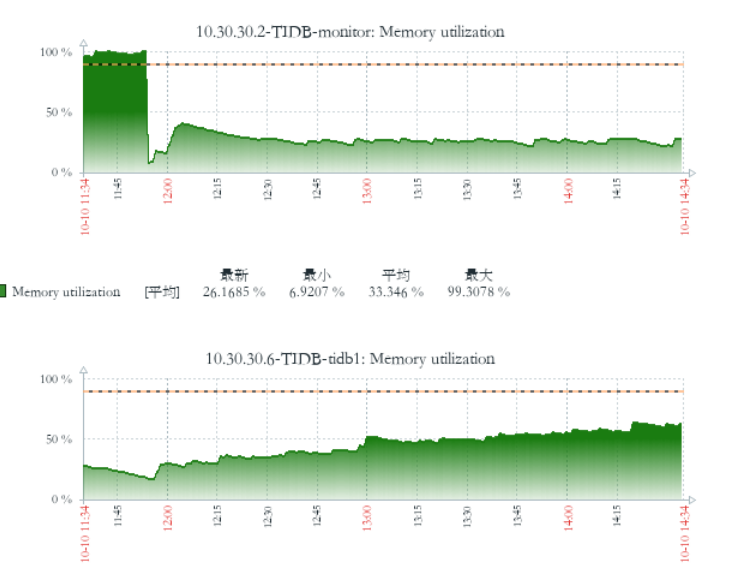
目前是第一个节点是正常的 不会一直增加 不释放,第二个节点 在一直增加不释放
zabbix 监控
buddyyuan
2022 年10 月 10 日 06:47
15
你可以对比一下图1,和图2,图2的uesd-by-go一直都在缓慢的增长。所以导致runtime部分,reserved-by-go部分也在持续增长。
到第二个节点上看下tidb日志,查下有没有expensive query。https://docs.pingcap.com/zh/tidb/v5.4/identify-expensive-queries
buddyyuan
2022 年10 月 10 日 06:53
16
如果没有到话,你可能需要做 Heap Profile 来定位一下,内存主要耗费在哪里了。
排查一下oom前有没有analyze table,如果有,就把tidb_analyze_version 改成1试试。我不太确定tidb_analyze_version=2的问题在5.4还存不存在
现在是找不到原因 也就没法复现了 就是这个节点涨到oom 挂了 另一个节点涨 到oom
好像是整点就oom了,6点,14点,17点,22点
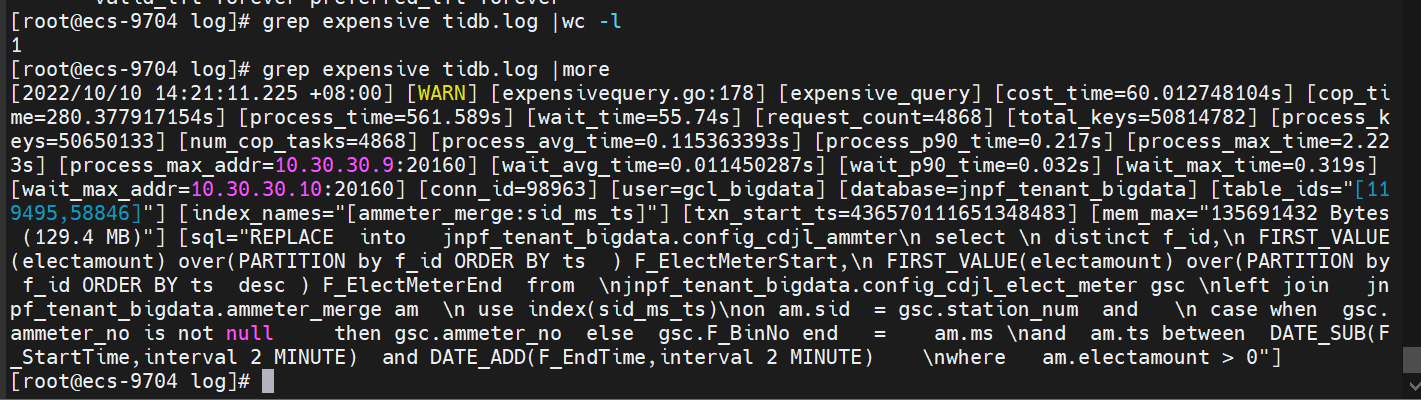
刚才查错日志了 只有一共expensivequery 占用129M