heloong
(Hacker F6cj Zcrd)
1
【 TiDB 使用环境】生产环境 /测试/ Poc
生产环境
【 TiDB 版本】
v5.0.6
【遇到的问题】
2022/10/08 15:56:00 ~ 16:28:00,线上应用大量报错timeout错误
【复现路径】做过哪些操作出现的问题
没有复现,自行恢复
【问题现象及影响】
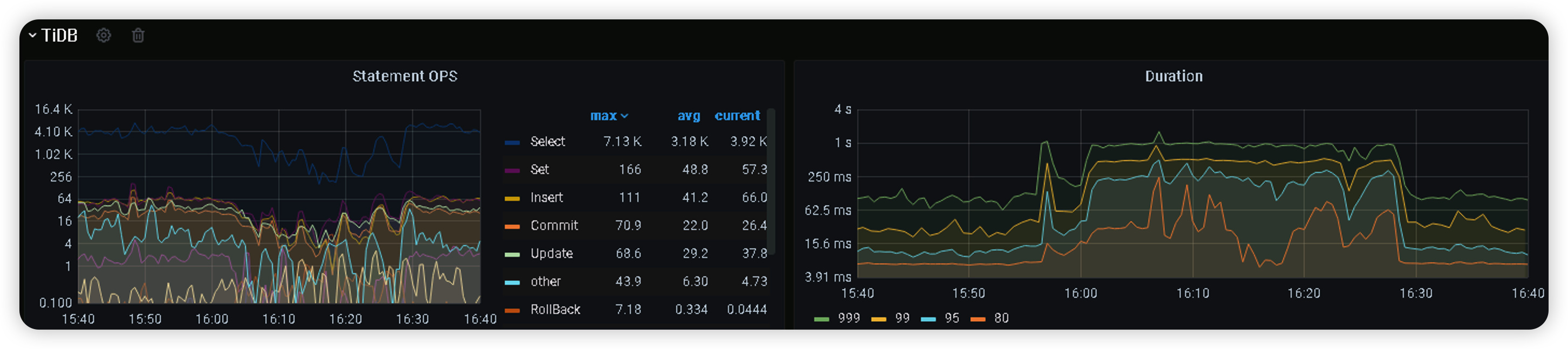
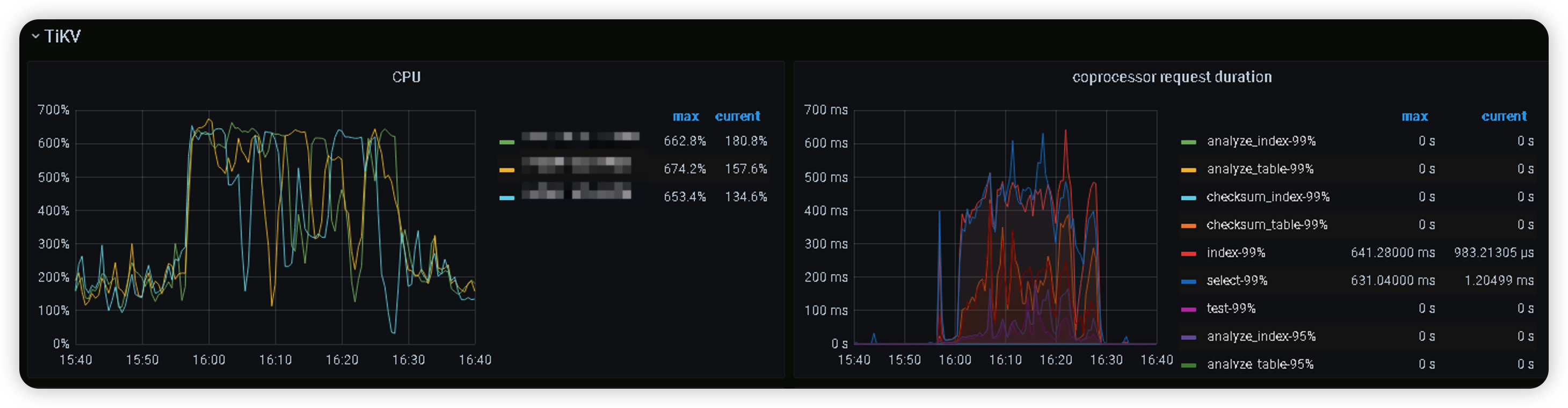
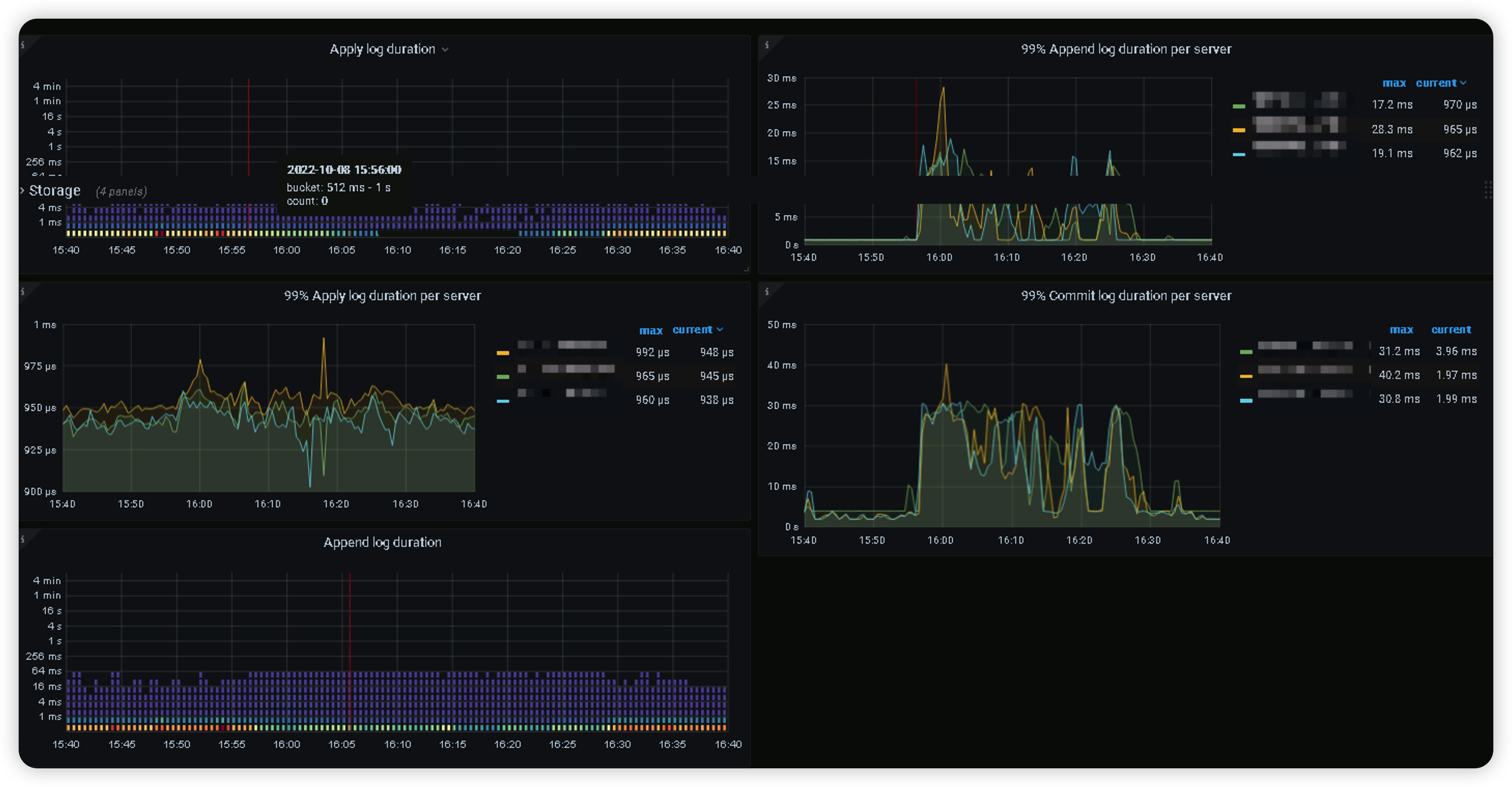
在这个时间段,查看tidb dashboard,所有sql耗时比平时慢数倍,不是个别sql,同时qps大幅下降,继续查看grafana所有tikv节点cpu使用率接近80%,个别出现超80%告警。
【附件】
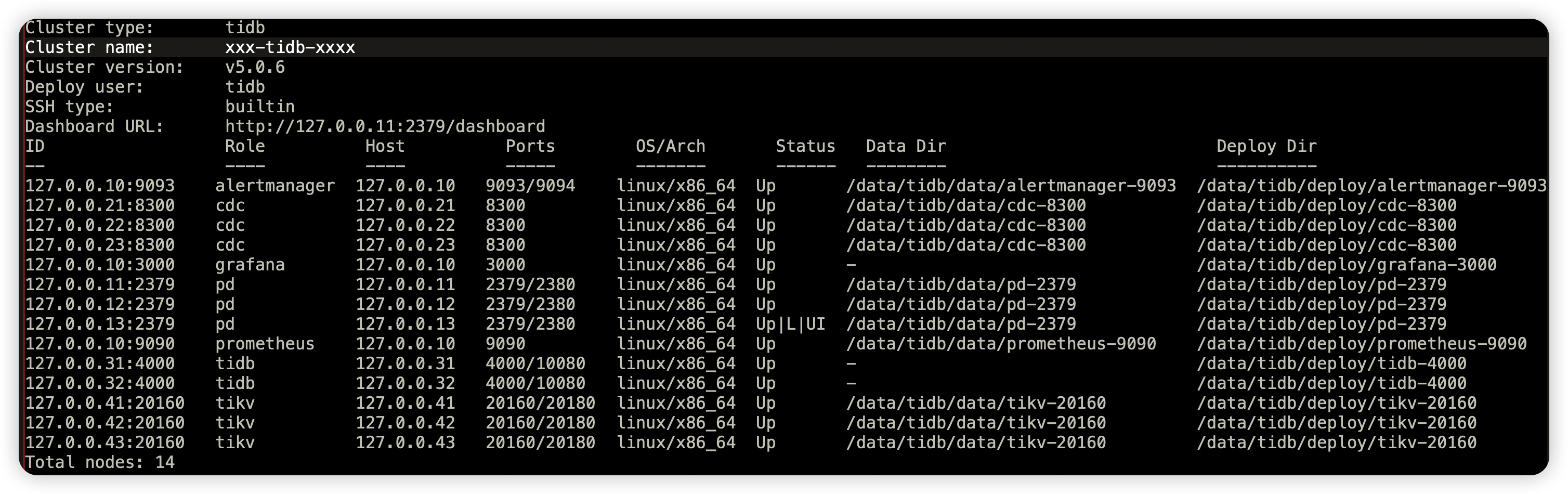
在阿里云上面,tikv节点是8c64g的本地磁盘,部署信息如下:
所有参数配置使用默认值没有调整过。
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
heloong
(Hacker F6cj Zcrd)
3
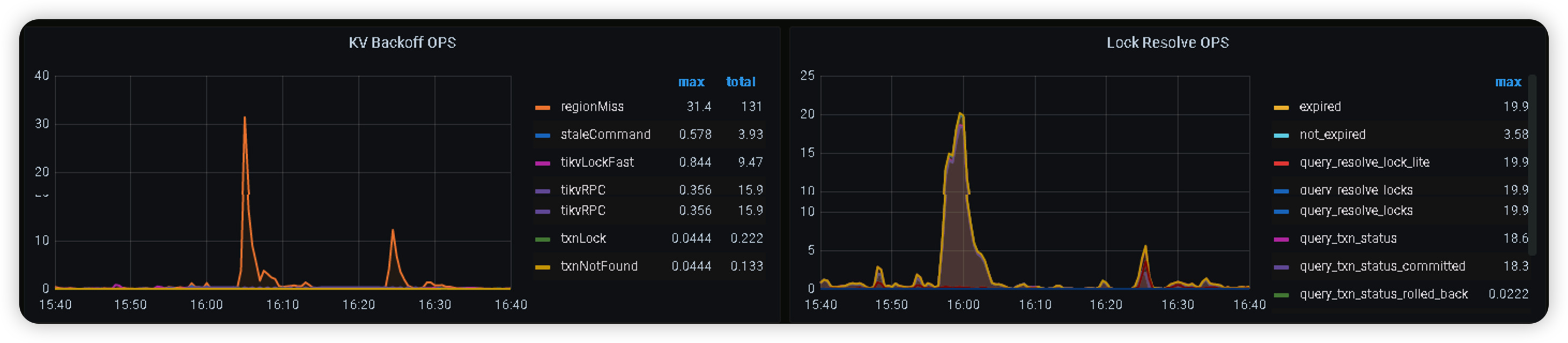
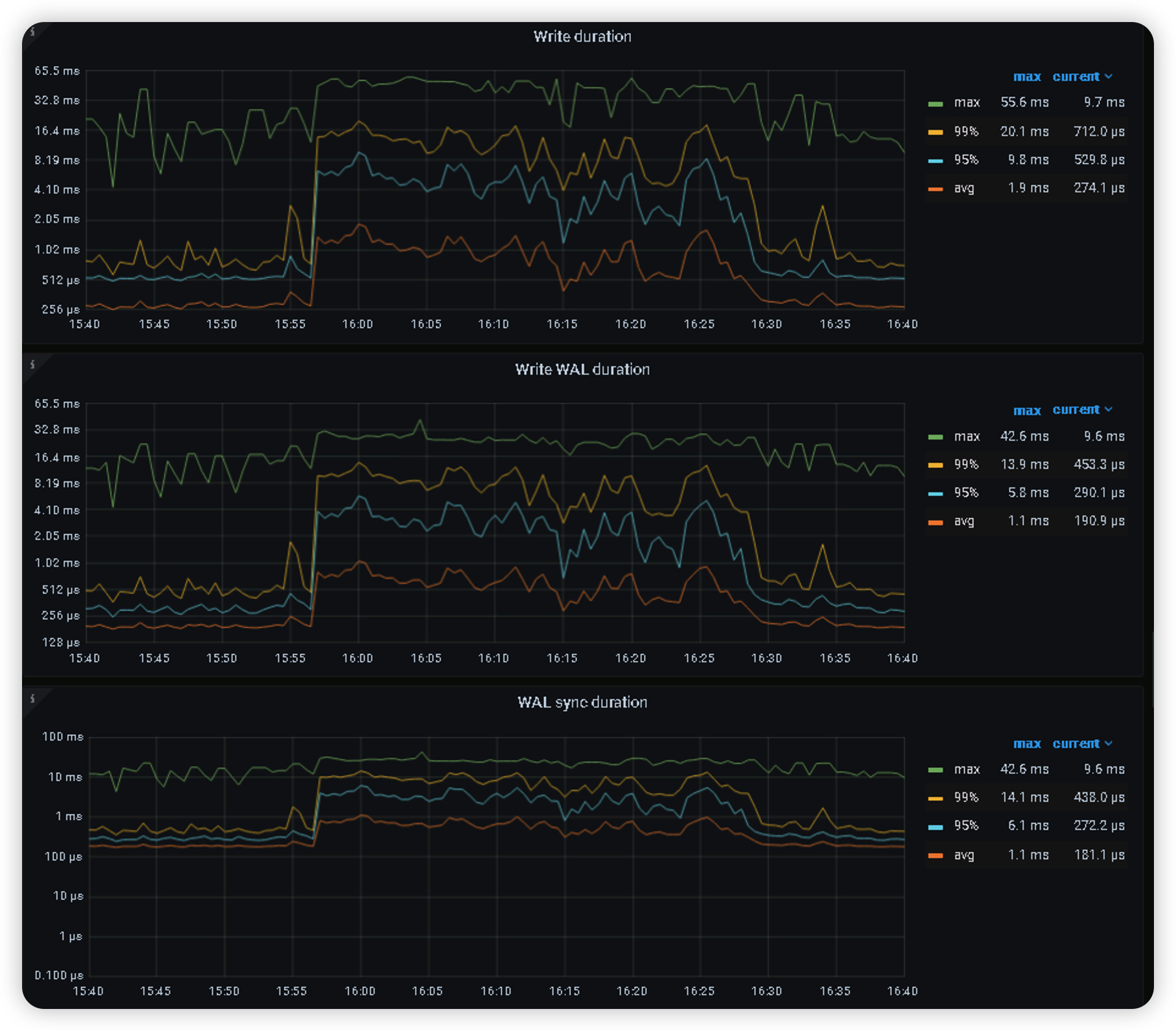
通过分析,tikv节点磁盘延迟,网络延迟都正常的,其他一些监控信息如下
heloong
(Hacker F6cj Zcrd)
4
首先看了这个,是所有sql慢了,是系统整体出问题了
大鱼海棠
5
看监控的话应该是慢查询的问题,unified read pool cpu明显增高了这么多
另外也要看下整机的负载
heloong
(Hacker F6cj Zcrd)
7
没有write stall,当时日志中也搜索不到,监控中也没有
在写延迟确实也明显增加,前面也有截图读延迟明显增加
1,系统层面是否有什么蛛丝马迹?
2,表的健康度如何?
3,是否有什么定时任务在跑,影响了tidb?