Johnpan
2022 年10 月 9 日 02:52
1
【 TiDB 使用环境】
【概述】 场景 + 问题概述
【背景】 做过哪些操作
【现象】 业务和数据库现象
【问题】 当前遇到的问题
【业务影响】
【TiDB 版本】
【应用软件及版本】
【附件】 相关日志及配置信息
TiUP Cluster Display 信息
TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/ )
TiDB-Overview Grafana监控
TiDB Grafana 监控
TiKV Grafana 监控
PD Grafana 监控
对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查 类问题,请下载脚本 运行。终端输出的打印结果,请务必全选 并复制粘贴上传。
db_user
2022 年10 月 9 日 03:01
3
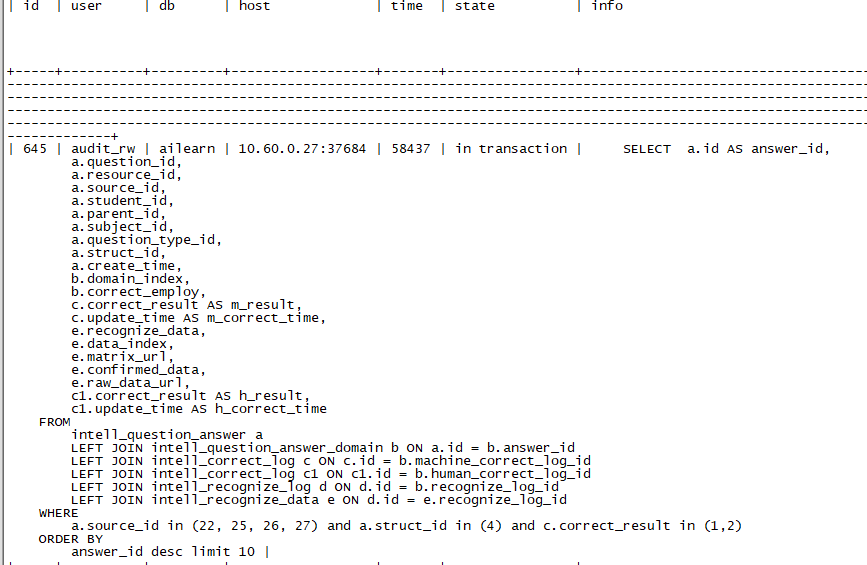
请问是在对应的host来kill的么,就是查询在哪个tidb,就需要在哪个tidb执行kill tidb
这个问题我最近做过测试,在tidb5.3.2中,这种sql(大概率多表联合,且是limit m, n这种,m很大),每次查询后,在后台挂一个时间不断递增的僵尸session,且不能被kill ;在tidb5.4.2中,僵尸session还是会有,但是可以被kill;在tidb6.1.1中,实测僵尸session不会出现。
CAICAI
2022 年10 月 9 日 03:11
6
我5.4的版本也遇到这种情况,kill tidb id(事务ID) ,kill tidb session_id,并且在对应tidb的host去操作也是kill不掉,难道要升级到6.1 ?
我们生产版本是5.3.2,目前再考虑这个事情怎么做,是否要升级。临时解决方案是将相关sql中的index hash join强制hint为index join可以绕过这个bug,实测有效。
buddyyuan
2022 年10 月 9 日 03:18
10
buddyyuan
2022 年10 月 9 日 03:20
12
实际上已经kill了,只是还显示在这里,要想清掉就重启tidb-server,不是很影响。具体的判断是否kill了,就观察tidb日志,只要tidb日志中有kill的字样,就说明已经发起了kill。
Johnpan
2022 年10 月 9 日 03:25
14
是的,我刚才重新执行kill tidb 645;就好了
张雨齐0720
2022 年10 月 9 日 07:48
17
他们能接受这个bug,那就这样了。
system
2022 年12 月 8 日 07:49
18
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。