版本:5.7.25-TiDB-v5.4.0
部署方式:k8s
节点情况:
问题:
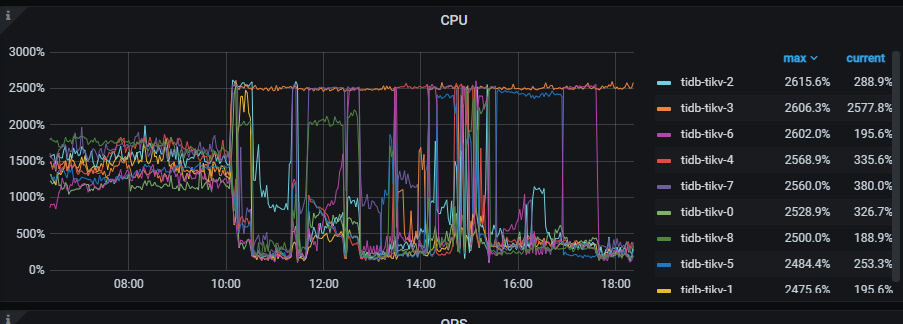
1、tikv节点会经常出现部分节点CPU高,各个TIKV节点CPU使用不均匀,感觉有热点问题,下图显示的KV节点在不同时段总有那么一两个POD节点CPU高,导致物理机CPU不同时段不同物理机CPU告警,请问如何定位问题去解决优化它。
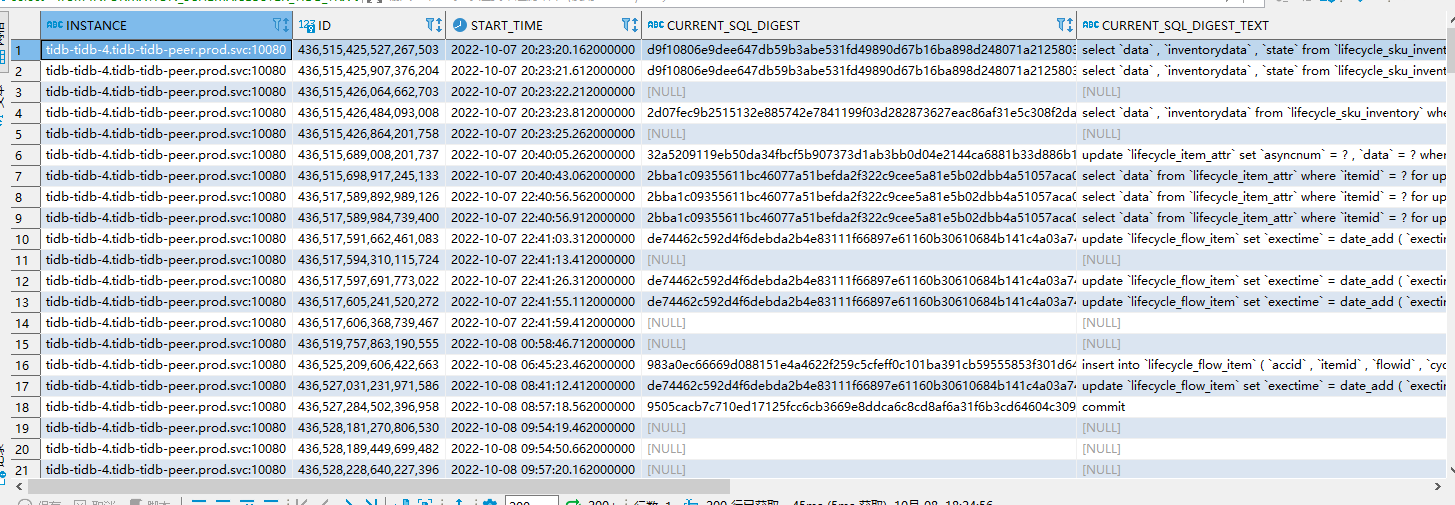
2、使用select * from INFORMATION_SCHEMA.CLUSTER_TIDB_TRX tt order by start_time 查询集群事务,发现事务这么久还在跑(时间显示相差8小时),使用MySQL的方式去kill这个事务(kill session_id, 到具体tidb实例里面kill也不行),如何KILL掉事务呢?
3、执行一段SELECT,超时报错: Coprocessor task terminated due to exceeding the deadline
这是什么错误呢
4、数据库报错:[type] => default:8027
[info] => Information schema is out of date: schema failed to update in 1 lease, please make sure TiDB can connect to TiK ,这是什么原因呢
5、执行表的查询, 报错: inconsistent index idx_cosume handle count 349 isn’t equal to value count 348,
执行:admin CHECK INDEX ims._of_com_mq idx_consumer,发现表记录数和索引记录数不一致,为什么会出现这个情况呢,该怎么解决呢,我尝试删除索引,重新创建一个索引,但是后面执行admin checK,,发现报错: Coprocessor task terminated due to exceeding the deadline
6、在第五步执行admin check的时候,发现卡死了,等待了很久没反应,查看admin show ddl jobs,发现如下问题:

为什么会出现queueing的状态,到底是在排队等谁呢,执行cancel的时候,发现也还是一样,该怎么处理呢 ?
7、查看tidb 的 dashboard中的慢SQL,发现好慢,为啥这个监控的地方会这么慢,是查询etcd里面的数据太慢了吗,还是说数据量太大了?
