【 TiDB 使用环境】生产环境
【 TiDB 版本】v5.2.2
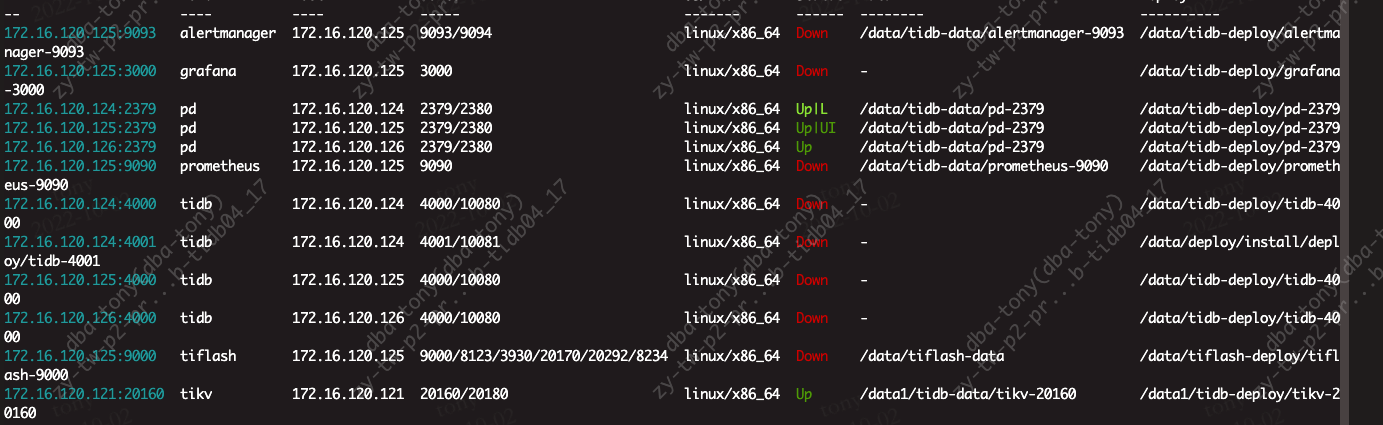
【遇到的问题】tidb缩容之后无法启动集群
【复现路径】无
【问题现象及影响】
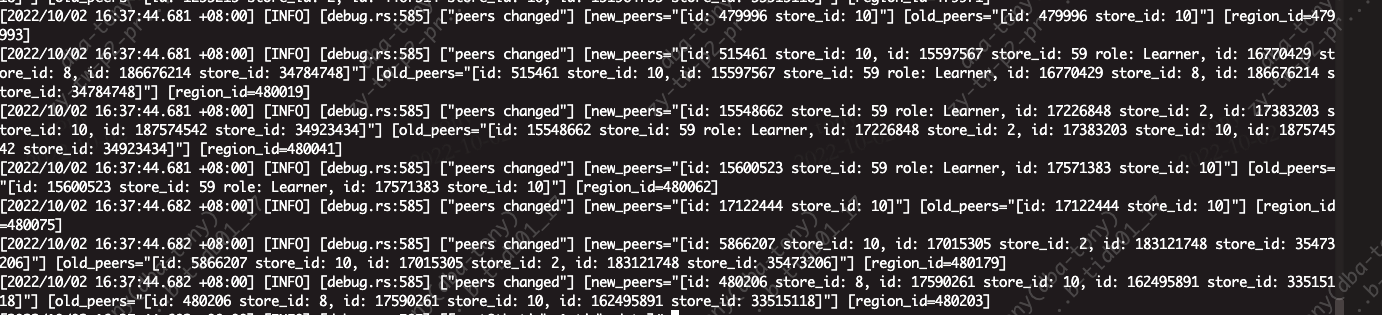
tidb缩容之后,报查询无法找到region,很多进程卡死,然后重启集群,无法启动成功。发现日志如下,一直在找已经下线的tikv。
2022/10/02 01:05:42.761 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.9:20160] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:05:42.762 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.9:20160] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.9:20160: connect: connection refused"”]
[2022/10/02 01:05:42.762 +08:00] [INFO] [region_request.go:344] [“mark store’s regions need be refill”] [id=15698413] [addr=172.16.120.9:20160] [error=“context deadline exceeded”]
[2022/10/02 01:05:43.470 +08:00] [INFO] [coprocessor.go:812] [“[TIME_COP_PROCESS] resp_time:10.925106589s txnStartTS:436376416354041867 region_id:15666413 store_addr:172.16.120.9:20160 backoff_ms:1165 backoff_types:[regionScheduling,tikvRPC,tikvRPC,regionMiss,regionScheduling,tikvRPC,tikvRPC]”]
[2022/10/02 01:05:48.485 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.10:20161] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:05:48.486 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.10:20161] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.10:20161: connect: connection refused"”]
[2022/10/02 01:05:48.486 +08:00] [INFO] [region_request.go:344] [“mark store’s regions need be refill”] [id=15698410] [addr=172.16.120.10:20161] [error=“context deadline exceeded”]
[2022/10/02 01:05:54.494 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.9:20160] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:05:54.495 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.9:20160] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.9:20160: connect: connection refused"”]
[2022/10/02 01:05:54.495 +08:00] [INFO] [region_request.go:344] [“mark store’s regions need be refill”] [id=15698413] [addr=172.16.120.9:20160] [error=“context deadline exceeded”]
[2022/10/02 01:05:56.012 +08:00] [INFO] [coprocessor.go:812] [“[TIME_COP_PROCESS] resp_time:12.53678461s txnStartTS:436376416354041867 region_id:15666413 store_addr:172.16.120.9:20160 backoff_ms:3700 backoff_types:[regionScheduling,tikvRPC,tikvRPC,regionMiss,regionScheduling,tikvRPC,tikvRPC,regionMiss,regionScheduling,tikvRPC,tikvRPC]”]
[2022/10/02 01:06:01.038 +08:00] [WARN] [client_batch.go:503] [“init create streaming fail”] [target=172.16.120.10:20161] [forwardedHost=] [error=“context deadline exceeded”]
[2022/10/02 01:06:01.039 +08:00] [INFO] [region_cache.go:2251] [“[health check] check health error”] [store=172.16.120.10:20161] [error=“rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 172.16.120.10:20161: connect: connection refused"”]
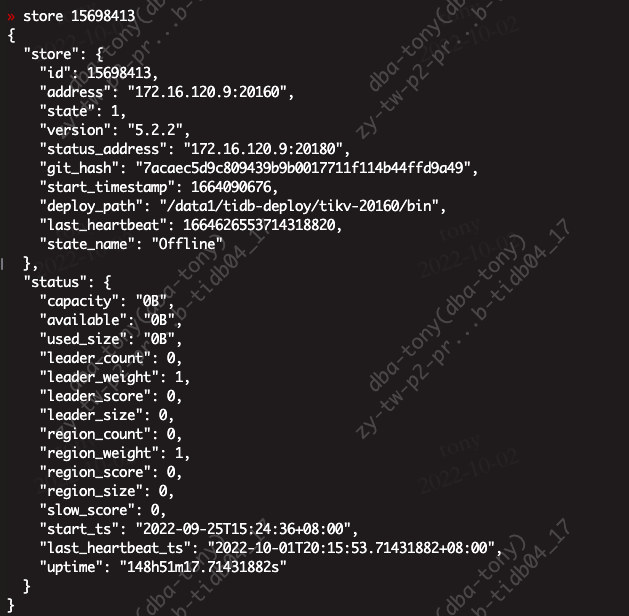
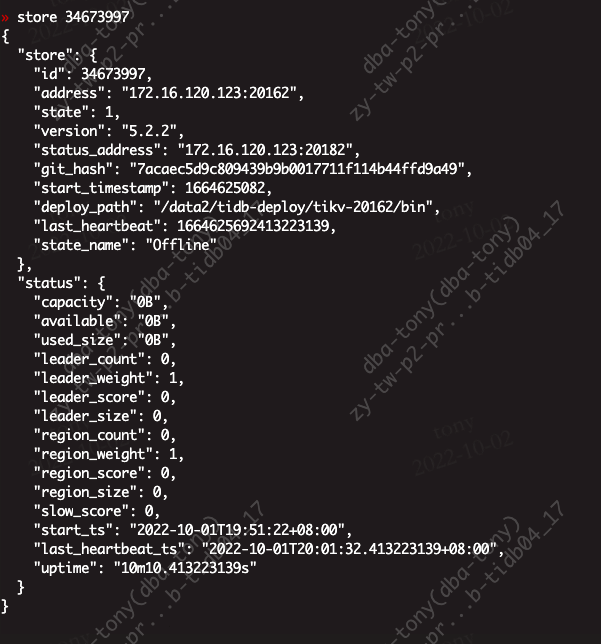
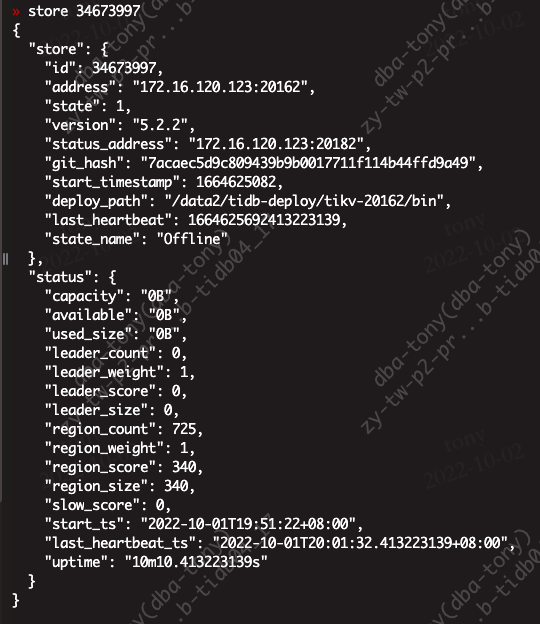
在store 里面发现信息
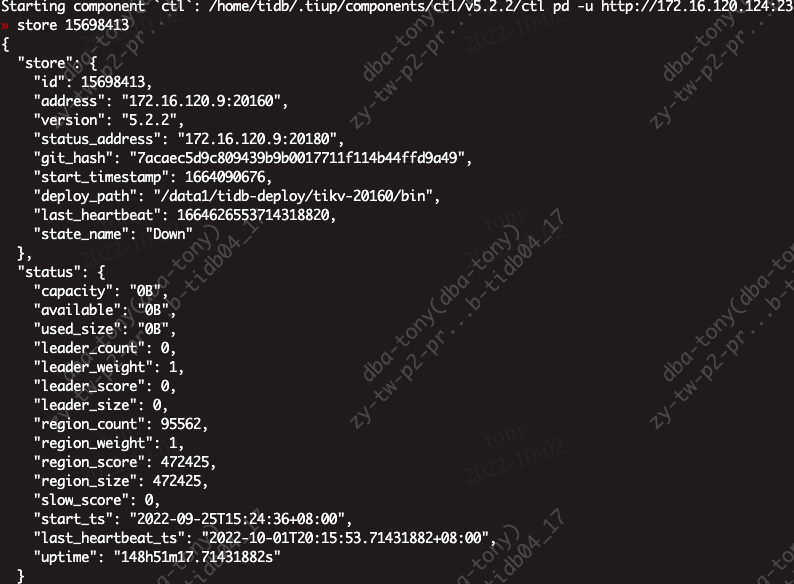
如何删除这些信息,让集群启动不会找已经下线的ip。我进入pd-ctl交互里面,手动store delete id ,显示成功,但是发现store里面还是有。没有删除掉