【 TiDB 使用环境】生产环境 /测试/ Poc
【 TiDB 版本】V5.4.0
【遇到的问题】
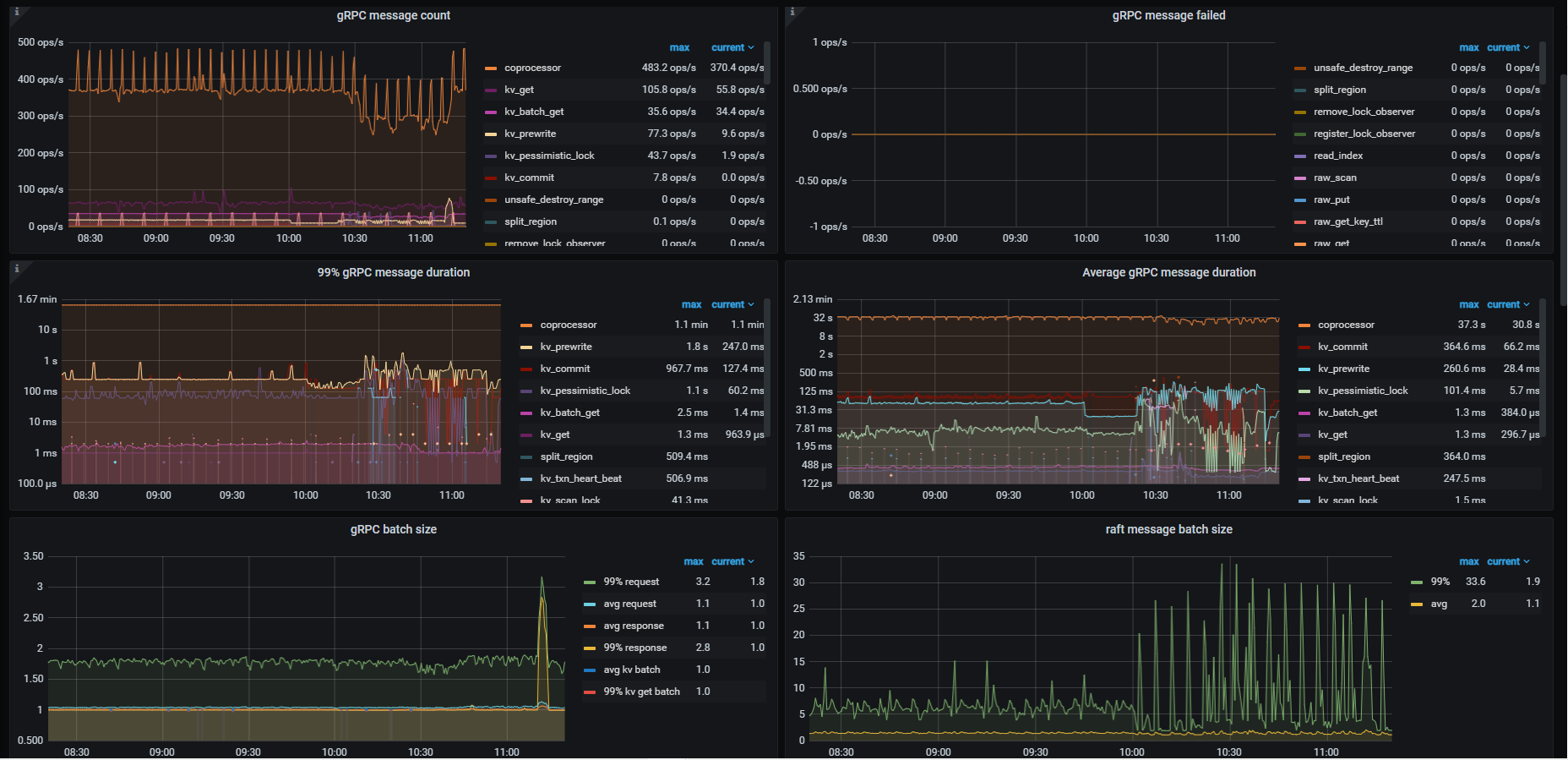
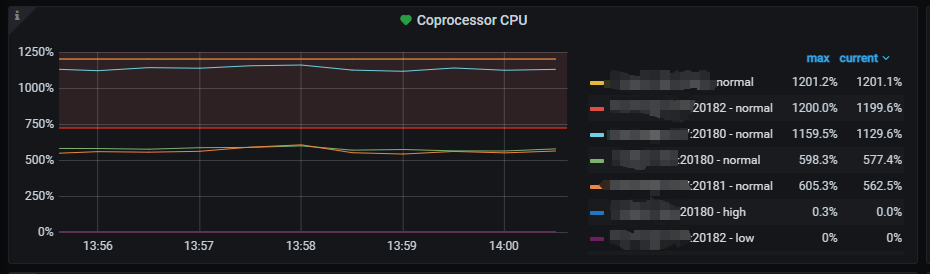
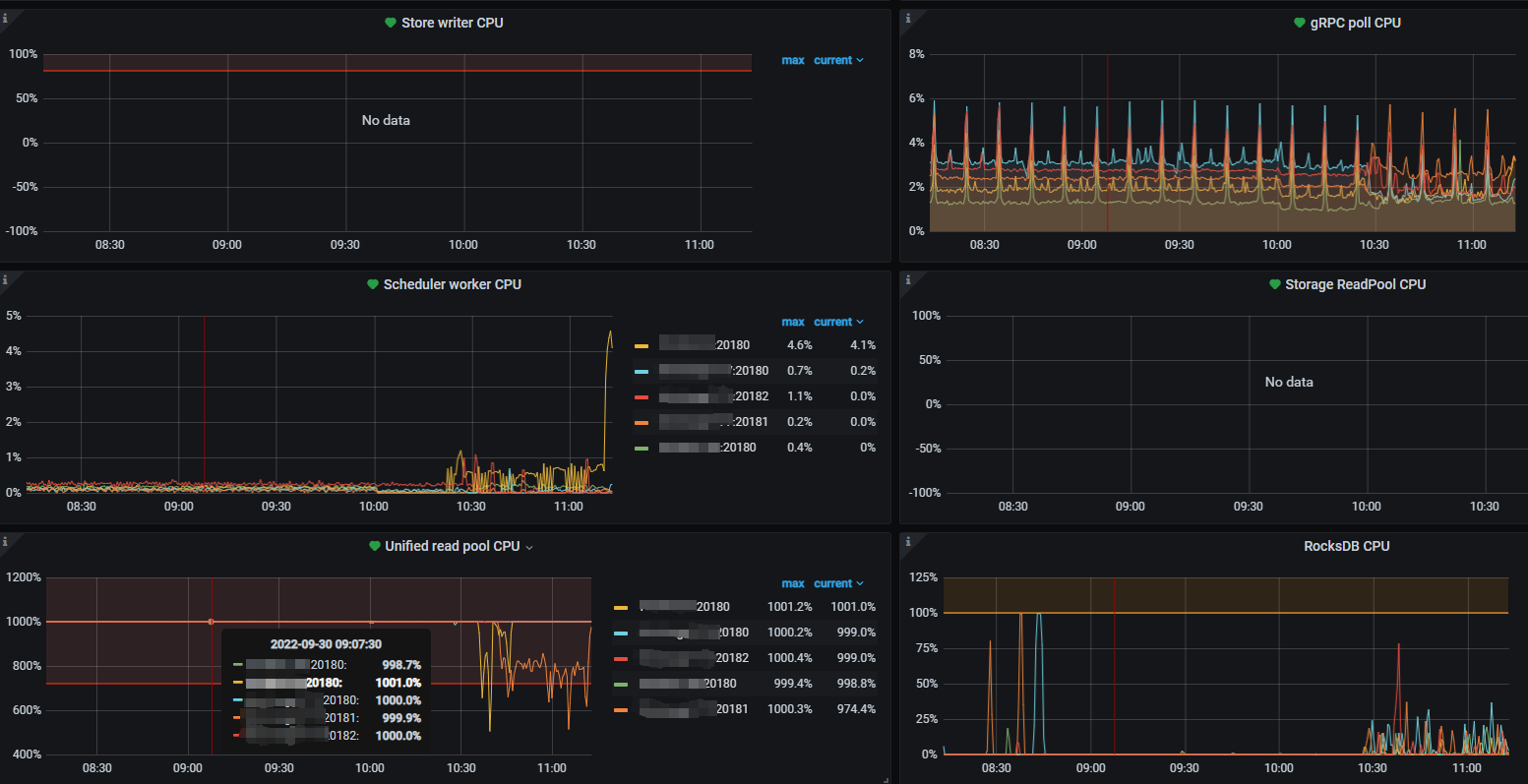
1、Unified Read Pool CPU 设置为10,5个tikv节点基本都一直打满1000%
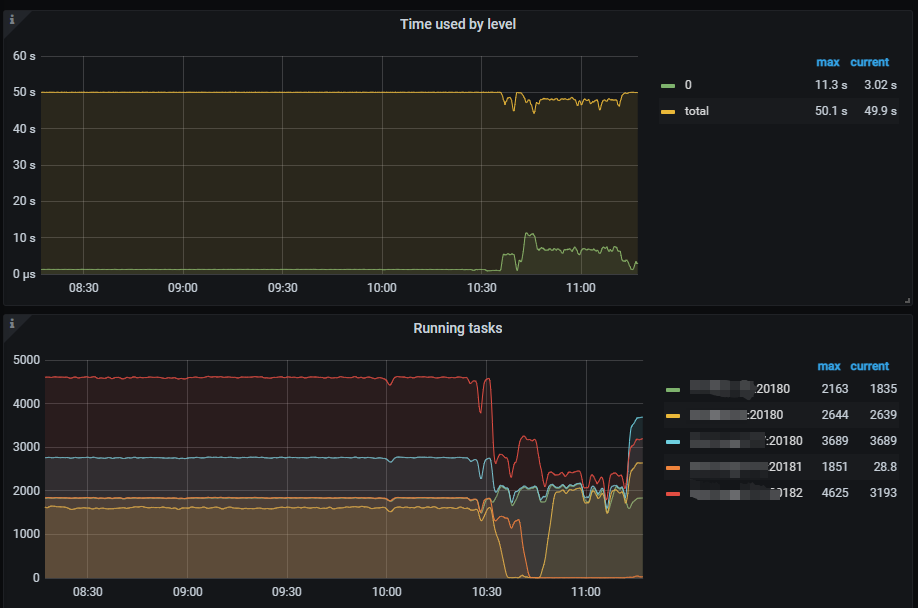
2、Running tasks每个节点最多的时候2000+,本来想试试 设置 tidb_enable_paging参数ON试试。结果参数show variables like ‘%tidb_enable_paging%’;没有找到
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
1、整个库查询都变慢了,大部分查询都Coprocessor 累计执行耗时长
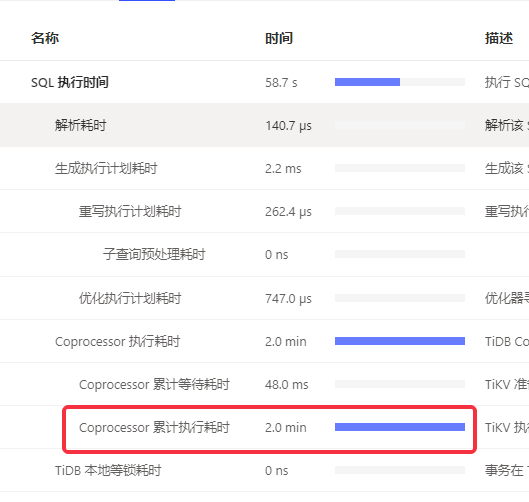
2、tidb_enable_paging设置不了
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。