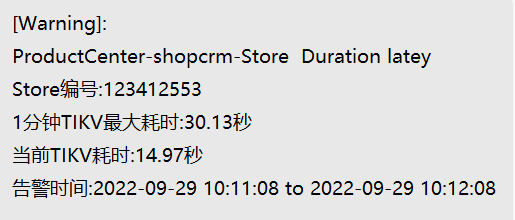
集群流量异常,通过TIDB_HOT_REGIONS 查看,
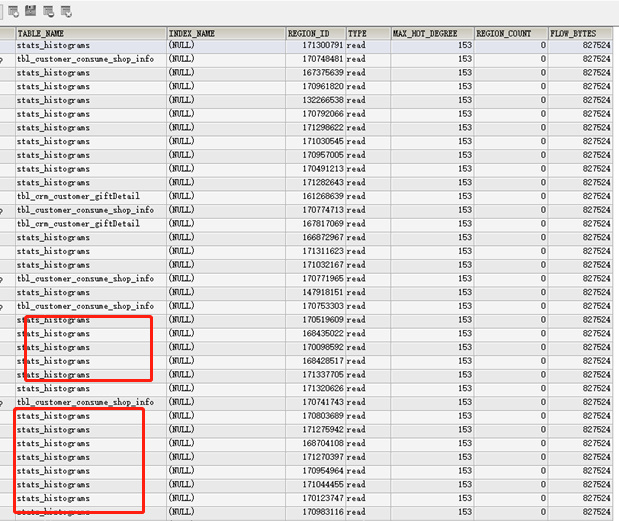
基本都是这个表stats_histograms,analyze参数设置如下图:
这种流量比较大怎么控制好?
tidb什么版本?
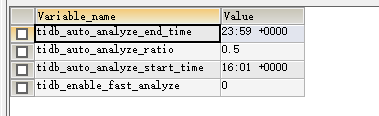
analyze这个没考虑时区么?要改成 +0800 才是我们这边的时间
V4.0.9,这2天才发生的
嗯,这套集群已经跑了1年了多了,TIDB是千兆网卡,这几天在某些时间段 网卡直接被打满,通过nethogs基本是TIDB-SERVER 网络流量为received 达到100MB/S
慢查询里有慢语句么?
就是MYSQL 那个表语句没发现,业务表SQL请求集群正常情况都很快。
建议调整analyze的时间范围再观察看看。现在这种设置,现在应该在自动analyze的区间内
tidb server接收流量高 也可能是SQL执行计划有问题,看下慢SQL有异常或变化吗
最好通过 prometheus 观察下,先看看是哪些节点的网络流量有异常,在进行排查
是几个TIKV节点往TIDB-SERVER发,几个总流量旧把TIDB-SERVER节点打满了
业务SQL 基本没变化的,新加的SQL 正常查询都非常快
行 ,等晚上在观察观察看
收集统计太频繁了,引起了热点,0.5调成0.6,调整一下呢
看戏这张表的 最后analyze 是什么时候,及其表的健康度
业务表 是有很多健康度低的表,TIDB数据是通过DM写入的,业务表频繁的变更,很容易导致监控度变低
统计信息的时间段可以短一点, 限制在业务低峰期 或者 晚上