【 TiDB 使用环境】生产环境
【 TiDB 版本】5.3.0
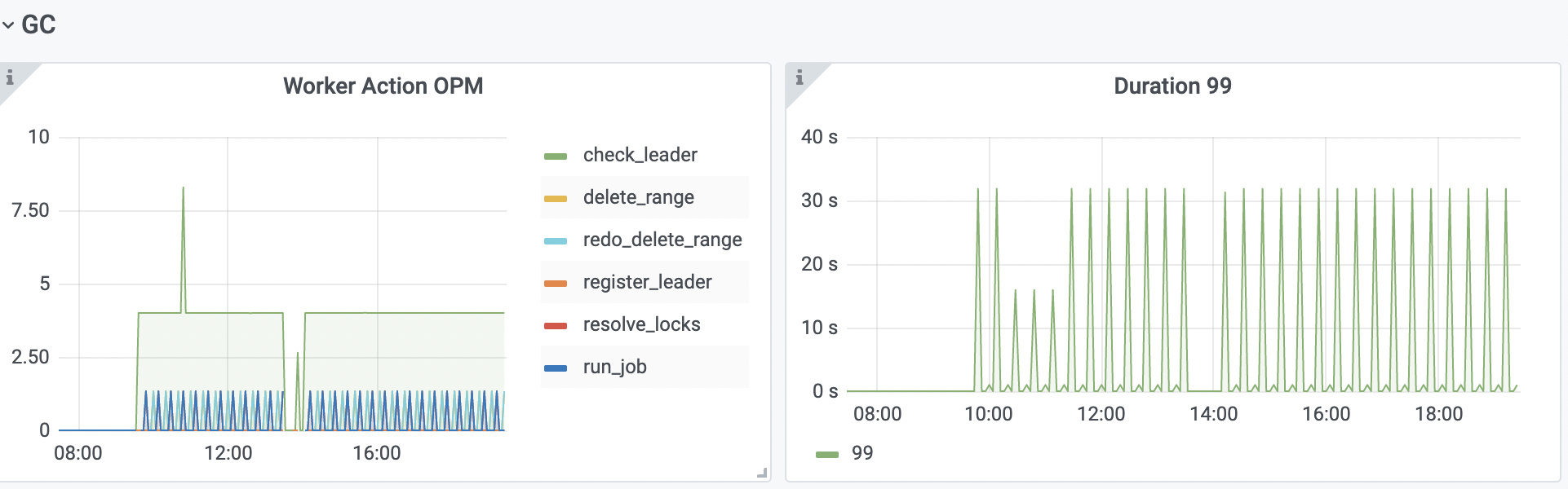
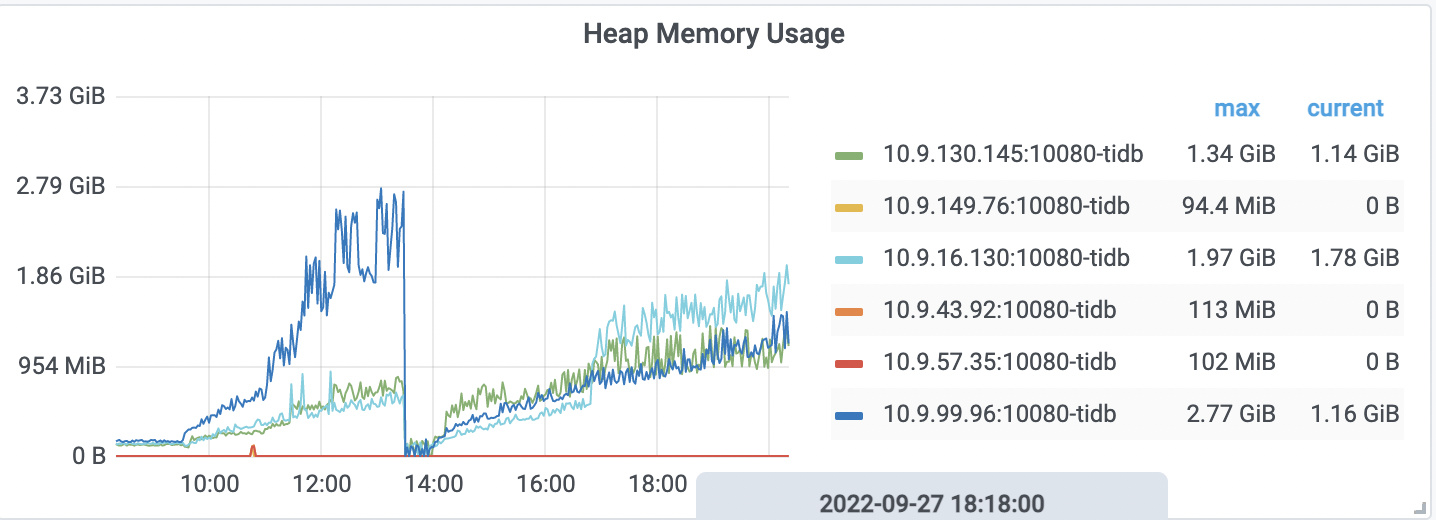
【遇到的问题】heap memory usage飙升
【复现路径】tiup升级集群4.0.6到5.3.0
【问题现象及影响】
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
【 TiDB 使用环境】生产环境
【 TiDB 版本】5.3.0
【遇到的问题】heap memory usage飙升
【复现路径】tiup升级集群4.0.6到5.3.0
【问题现象及影响】
【附件】
请提供各个组件的 version 信息,如 cdc/tikv,可通过执行 cdc version/tikv-server --version 获取。
tidb有oom现象 你看看有没有慢sql
有慢sql,主要集中在dashboard查询慢查询和一个之前的查询上面,怎么看有没有oom?
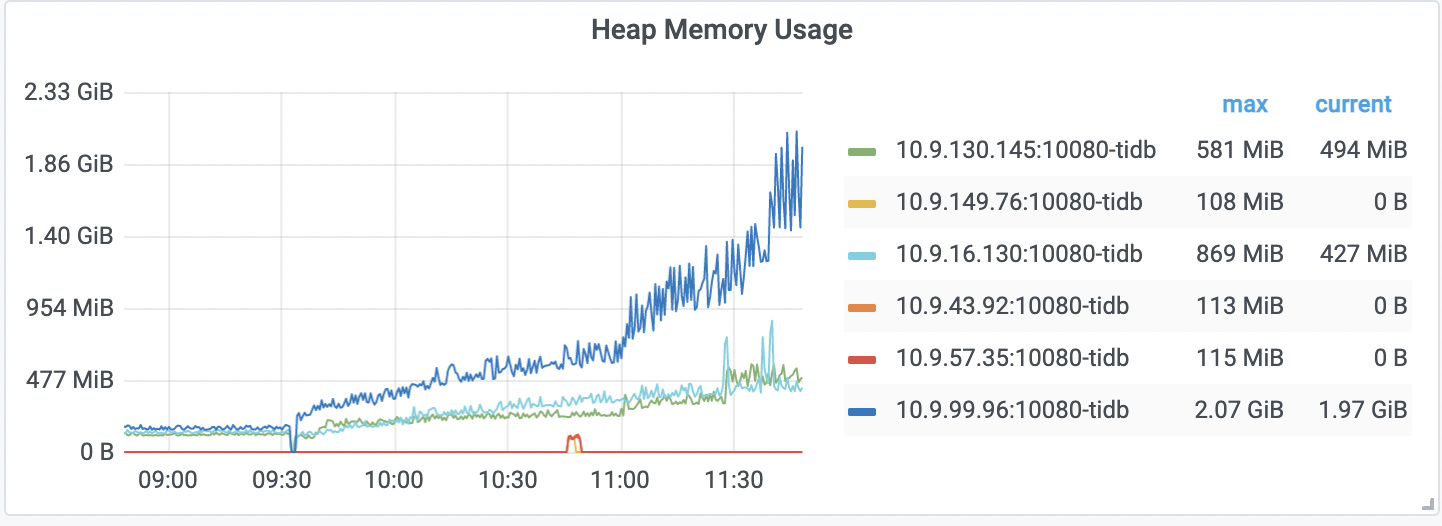
有没有人啊,目前看没有oom,heap memory还在涨啊,完全没有方向啊!
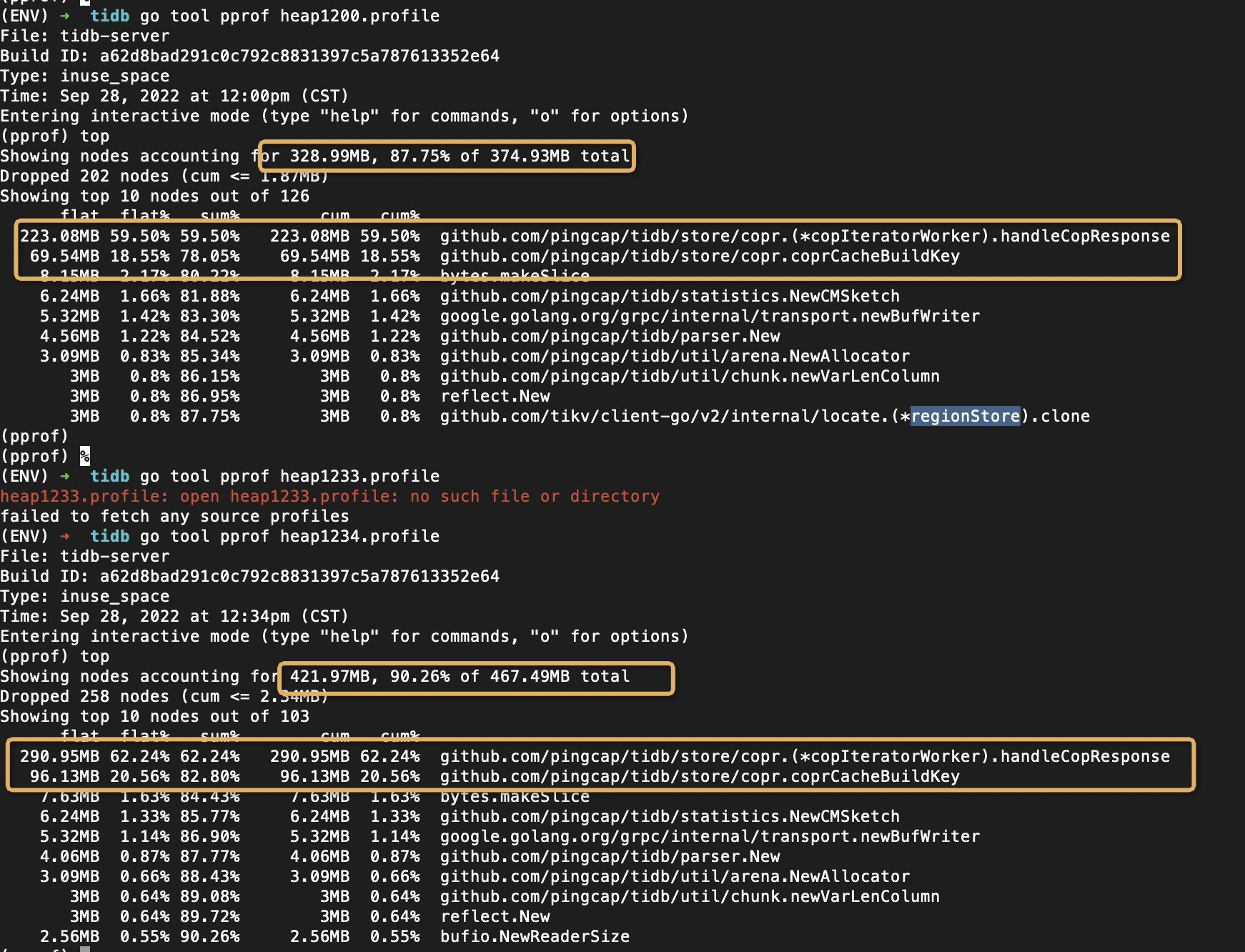
curl -G tidb_ip:10080/debug/pprof/heap > heap.profile
用上面方式 获取下pprofile,上传下结果文件
heap.profile (324.1 KB)
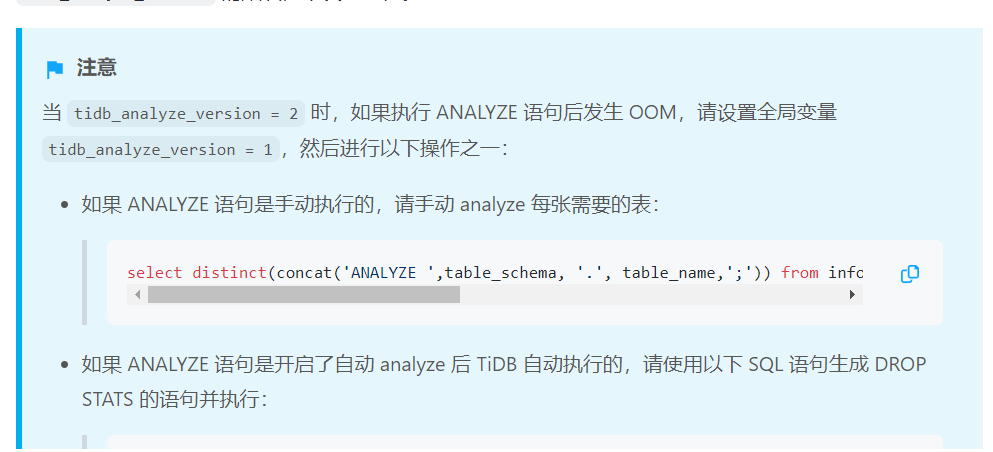
从heap看 最高的那个是慢日志相关的, 估计可能是5.x后这块处理机制有变化。检查下analyze_version变量值是否是2,如果是的话改为1.,同时按下面的把历史为2的统计信息清理下
查看dashboard的top SQL,看看消耗CPU的SQL,有可能执行计划有4.0到5.0发生了改变。
调整analyze后没有用,还是上涨,半个小时的profile,涨了100M,和heap memory usage里面的涨幅相当;
slow_query没有发现异常的查询,tidb.log里面也没有发现和analyze相关的日志,只有下面两条,对应tidb-server重启的时间点:
[tidb@tikv01 log]$ grep Analyze tidb.log
[2022/09/27 09:33:28.956 +08:00] [INFO] [domain.go:1422] [“autoAnalyzeWorker exited.”]
[2022/09/28 09:22:07.400 +08:00] [INFO] [domain.go:1422] [“autoAnalyzeWorker exited.”]
anlyze version 2的表统计信息也删除了吗? 是否可以观察时间长点,看内存能涨到多少就不涨了
sql计划没问题就不用,系统会自动分析
打补丁到5.3.3吧。是一个缺陷:https://github.com/pingcap/tidb/pull/32781
目前稳定在了2.4G,对比之前涨了2.2G,想问下除开 Coprocessor cache的1G,还有哪里的配置会导致这个内存涨幅?另外,怎么判断是否有自动的analyze呢?到tidb.log里面看有没有相关日志?
哪里导致的不清楚,anlalyze 在stats owner节点的tidb.log,可以用select tidb_ddl_owner()在每个server看下
如果你不通过dashboard 去查询慢sql,看下内存看会不会继续增长?