-
系统版本 & kernel 版本:
centos6 -
TiDB 版本:
2.1.6 -
磁盘型号:
ssd -
集群节点分布:
3pd 5tikv 3tidb -
数据量 & region 数量 & 副本数:
数据3亿
region数 1350
副本数 3 -
集群 QPS、.999-Duration、读写比例:
-
问题描述(我做了什么):
导入数据之后,tikv5个节点只有三个节点有region分布,其他两个节点没有;
后继续导入数据,在晚间没region的节点曾经出现过500多个Region, 但第二天早上看又全部转移到另外三个节点上去了。stores信息:
{
“count”: 5,
“stores”: [
{
“store”: {
“id”: 1,
“address”: “server1:20160”,
“version”: “2.1.6”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.8 TiB”,
“available”: “831 GiB”,
“leader_count”: 396,
“leader_weight”: 1,
“leader_score”: 46851,
“leader_size”: 46851,
“region_count”: 1356,
“region_weight”: 1,
“region_score”: 139112,
“region_size”: 139112,
“start_ts”: “2019-08-30T17:49:20+08:00”,
“last_heartbeat_ts”: “2019-09-03T10:32:07.47088465+08:00”,
“uptime”: “88h42m47.47088465s”
}
},
{
“store”: {
“id”: 4,
“address”: “server2:20160”,
“version”: “2.1.6”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.8 TiB”,
“available”: “596 GiB”,
“leader_weight”: 1,
“region_weight”: 1,
“region_score”: 400047722.26514226,
“start_ts”: “2019-09-02T14:52:50+08:00”,
“last_heartbeat_ts”: “2019-09-03T10:32:12.497016108+08:00”,
“uptime”: “19h39m22.497016108s”
}
},
{
“store”: {
“id”: 5,
“address”: “server3:20160”,
“version”: “2.1.6”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.8 TiB”,
“available”: “643 GiB”,
“leader_count”: 502,
“leader_weight”: 1,
“leader_score”: 46368,
“leader_size”: 46368,
“region_count”: 1356,
“region_weight”: 1,
“region_score”: 262591912.02775782,
“region_size”: 139112,
“start_ts”: “2019-08-30T17:48:43+08:00”,
“last_heartbeat_ts”: “2019-09-03T10:32:05.497334715+08:00”,
“uptime”: “88h43m22.497334715s”
}
},
{
“store”: {
“id”: 6,
“address”: “server4:20160”,
“version”: “2.1.6”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.8 TiB”,
“available”: “487 GiB”,
“leader_weight”: 1,
“region_weight”: 1,
“region_score”: 718598132.8772172,
“start_ts”: “2019-08-30T17:48:20+08:00”,
“last_heartbeat_ts”: “2019-09-03T10:32:08.574113626+08:00”,
“uptime”: “88h43m48.574113626s”
}
},
{
“store”: {
“id”: 7,
“address”: “server5:20160”,
“version”: “2.1.6”,
“state_name”: “Up”
},
“status”: {
“capacity”: “1.8 TiB”,
“available”: “613 GiB”,
“leader_count”: 458,
“leader_weight”: 1,
“leader_score”: 45893,
“leader_size”: 45893,
“region_count”: 1356,
“region_weight”: 1,
“region_score”: 352086555.48031425,
“region_size”: 139112,
“start_ts”: “2019-08-30T17:47:43+08:00”,
“last_heartbeat_ts”: “2019-09-03T10:32:09.976414906+08:00”,
“uptime”: “88h44m26.976414906s”
}
}
]
}没region的tikv节点日志:
2019/09/02 16:37:20.496 INFO peer.rs:911: [region 229594] destroy peer id: 245537 store_id: 4
2019/09/02 16:37:20.496 INFO read.rs:484: [region 229594] 245537 destroy ReadDelegate
2019/09/02 16:37:20.496 INFO peer.rs:513: [region 229594] 245537 begin to destroy
2019/09/02 16:37:20.496 INFO pd.rs:633: [region 229594] remove peer statistic record in pd
2019/09/02 16:37:20.496 INFO peer_storage.rs:1257: [region 229594] clear peer 1 meta key, 1 apply key, 1 raft key and 7 raft logs, takes 127.497µs
2019/09/02 16:37:20.496 INFO peer.rs:550: [region 229594] 245537 destroy itself, takes 387.25µs
2019/09/02 16:37:20.496 INFO region.rs:456: [region 229594] register deleting data in [zt200\000\000\000\000\000\001377:_i200\000\000\000\000377\000\000\001\003200\000\000\000377\0013241236\003200\000\000377\000\000\000\000\002\003200\000377\000\0007P/230\000\000375, zt200\000\000\000\000\000\001377:_i200\000\000\000\000377\000\000\001\003200\000\000\000377\0013241237\003200\000\000377\000\000\000\000\002\003200\000377\000\000:<310a\000\000375)
2019/09/02 16:37:24.297 INFO pd.rs:558: [region 35141] try to change peer AddNode id: 247777 store_id: 7
2019/09/02 16:37:24.297 INFO peer.rs:1850: [region 35141] 245552 propose conf change AddNode peer 247777
2019/09/02 16:37:24.372 INFO apply.rs:902: [region 35141] 245552 execute admin command cmd_type: ChangePeer change_peer {peer {id: 247777 store_id: 7}} at [term: 187, index: 880]
2019/09/02 16:37:24.372 INFO apply.rs:951: [region 35141] 245552 exec ConfChange “AddNode”, epoch: conf_ver: 1767 version: 145
2019/09/02 16:37:24.372 INFO apply.rs:1002: [region 35141] 245552 add peer id: 247777 store_id: 7 to region id: 35141 start_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377K
361\000\000\000\000\000372” end_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377Y260361\000\000\000\000\000372” region_epoch {conf_ver: 1767 version: 145} peers {id: 239735 store_id: 5} peers {id: 241268 store_id: 1} peers {id: 245552 store_id: 4} peers {id: 247777 store_id: 7 is_learner: true}
2019/09/02 16:37:24.372 INFO peer.rs:1018: [region 35141] 245552 notify pd with change peer region id: 35141 start_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377K
361\000\000\000\000\000372” end_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377Y260361\000\000\000\000\000372” region_epoch {conf_ver: 1768 version: 145} peers {id: 239735 store_id: 5} peers {id: 241268 store_id: 1} peers {id: 245552 store_id: 4} peers {id: 247777 store_id: 7}
2019/09/02 16:37:24.375 INFO pd.rs:575: [region 35141] try to transfer leader from id: 245552 store_id: 4 to id: 239735 store_id: 5
2019/09/02 16:37:24.375 INFO pd.rs:575: [region 35141] try to transfer leader from id: 245552 store_id: 4 to id: 239735 store_id: 5
2019/09/02 16:37:24.375 INFO peer.rs:1539: [region 35141] 245552 transfer leader to id: 239735 store_id: 5
2019/09/02 16:37:24.375 INFO :1277: [region 35141] 245552 [term 187] starts to transfer leadership to 239735
2019/09/02 16:37:24.375 INFO :1287: [region 35141] 245552 sends MsgTimeoutNow to 239735 immediately as 239735 already has up-to-date log
2019/09/02 16:37:24.375 INFO peer.rs:1539: [region 35141] 245552 transfer leader to id: 239735 store_id: 5
2019/09/02 16:37:24.375 INFO :1254: [region 35141] 245552 [term 187] transfer leadership to 239735 is in progress, ignores request to same node 239735
2019/09/02 16:37:24.376 INFO :923: [region 35141] 245552 [term: 187] received a MsgRequestVote message with higher term from 239735 [term: 188]
2019/09/02 16:37:24.376 INFO :722: [region 35141] 245552 became follower at term 188
2019/09/02 16:37:24.376 INFO :1091: [region 35141] 245552 [logterm: 187, index: 880, vote: 0] cast MsgRequestVote for 239735 [logterm: 187, index: 880] at term 188
2019/09/02 16:37:24.380 INFO apply.rs:902: [region 35141] 245552 execute admin command cmd_type: ChangePeer change_peer {change_type: RemoveNode peer {id: 245552 store_id: 4}} at [term: 188, index: 882]
2019/09/02 16:37:24.380 INFO apply.rs:951: [region 35141] 245552 exec ConfChange “RemoveNode”, epoch: conf_ver: 1768 version: 145
2019/09/02 16:37:24.380 INFO apply.rs:1045: [region 35141] 245552 remove 245552 from region 35141 start_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377K
35141 start_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377K
361\000\000\000\000\000372” end_key: “t200\000\000\000\000\000\001377\025_r200\000\000\000\000377Y260361\000\000\000\000\000372” region_epoch {conf_ver: 1768 version: 145} peers {id: 239735 store_id: 5} peers {id: 241268 store_id: 1} peers {id: 245552 store_id: 4} peers {id: 247777 store_id: 7}
2019/09/02 16:37:24.495 INFO peer.rs:911: [region 35141] destroy peer id: 245552 store_id: 4
2019/09/02 16:37:24.495 INFO read.rs:484: [region 35141] 245552 destroy ReadDelegate
2019/09/02 16:37:24.495 INFO peer.rs:513: [region 35141] 245552 begin to destroy
2019/09/02 16:37:24.495 INFO pd.rs:633: [region 35141] remove peer statistic record in pd
2019/09/02 16:37:24.495 INFO peer_storage.rs:1257: [region 35141] clear peer 1 meta key, 1 apply key, 1 raft key and 7 raft logs, takes 93.027µs
2019/09/02 16:37:24.495 INFO peer.rs:550: [region 35141] 245552 destroy itself, takes 316.253µs
2019/09/02 16:37:24.496 INFO region.rs:456: [region 35141] register deleting data in [zt200\000\000\000\000\000\001377\025_r200\000\000\000\000377K
361\000\000\000\000\000372, zt200\000\000\000\000\000\001377\025_r200\000\000\000\000377Y260361\000\000\000\000\000372)
2019/09/02 16:40:08.849 INFO region.rs:425: [region 20447] succeed in deleting data in [zt200\000\000\000\000\000\0003779_i200\000\000\000\000377\000\000\002\00175553779da5377a0c37764ea03778837782bea7377f377aae4637377377\000\000\000\000\000\000\000\000377367\000\000\000\000\000\000\000370, zt200\000\000\000\000\000\0003779_i200\000\000\000\000377\000\000\002\001c83537780c1377713377e47d0377a6377782c6d3772377fa25158377377\000\000\000\000\000\000\000\000377367\000\000\000\000\000\000\000370)
2019/09/02 16:40:08.850 INFO region.rs:425: [region 23030] succeed in deleting data in [zt200\000\000\000\000\000\001377\003\000\000\000\000\000\000\000370, zt200\000\000\000\000\000\001377\005\000\000\000\000\000\000\000370)
TiDB 操作系统版本要求部署需要在 centos 7.3 以上。
https://pingcap.com/docs-cn/v3.0/how-to/deploy/hardware-recommendations/
另外,辛苦发下 PD 的配置情况。可以使用 config show all 看下,TiKV 的store 信息也提供一份完整的 json 格式吧。
config show all:
all_config.json
all_config.json (2.7 KB)
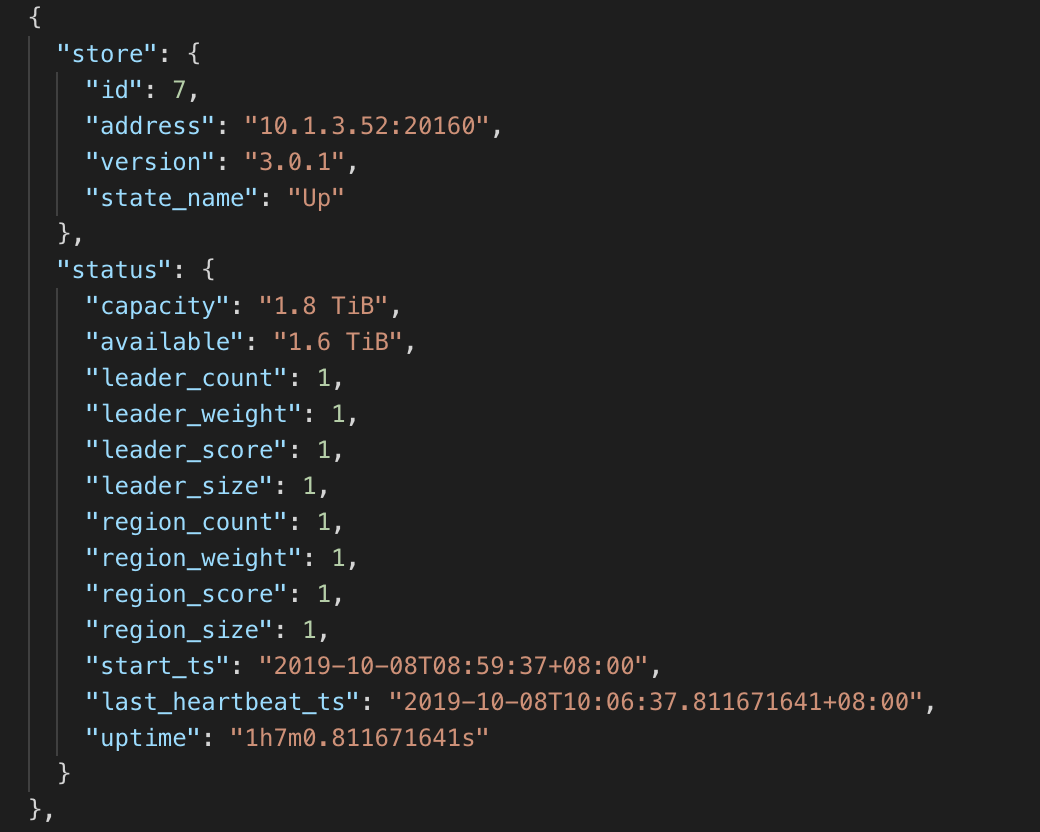
tikv在释放了两个无region分布的节点的部分存储空间后,region分布在四个节点上均衡了,但是之前有region分布的一个节点的region count变成了1,这个节点的剩余存储空间是五个里面最小的
tikv store info: tikv_store.json
tikv_store.json (3.2 KB)
scheduler show:
» scheduler show
[ "balance-region-scheduler", "balance-leader-scheduler", "balance-hot-region-scheduler", "label-scheduler" ]
手动调度一下试试,另外看下 PD 面板上 scheduler 有没有在正常进行 region 调度。
释放的两个无 region 分布的节点存储空间是怎么做的?看了 store 信息,store 7 只有一个 leader ,为什么会占用那么多存储空间?其次,TiDB 本身会自动进行数据的 balance ,监控看下 region 调度策略是不是有异常,具体看下 PD 面板 Scheduler 下面 Scheduler is running & Balance leader movement & Balance Region movement & Balance leader scheduler & Balance Region scheduler 这些指标项是不是正常的。
找到 store 7 上的 region_id:
pd-ctl -d -u http://xxxx:2379 region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(any(.==7))}"
根据 region_id 看看这个 region 多大,是不是比其他 region 大,这个 store 的 region 怎么这么大比较奇怪
tikv-ctl --db /path/to/tikv/db size -r 2
{
"store": {
"id": 7,
"address": "server5:20160",
"version": "2.1.6",
"state_name": "Up"
},
"status": {
"capacity": "1.8 TiB",
"available": "637 GiB",
"leader_count": 1,
"leader_weight": 1,
"leader_score": 10,
"leader_size": 10,
"region_count": 1,
"region_weight": 1,
"region_score": 282520009.65852684,
"region_size": 10,
"start_ts": "2019-08-30T17:47:43+08:00",
"last_heartbeat_ts": "2019-09-03T16:59:37.469121761+08:00",
"uptime": "95h11m54.469121761s"
}监控看下这个 TiKV 实例上面 region 的大小 PD -> Statistics - Balance -> Store Region size
你好,假期里我们集群中的一个节点重启之后,没有启动tidb相关进程,上班回来启动后发现region分布不均

我的配置如下config_show_all.json (3.1 KB)
tikv_store.json (3.2 KB)
scheduler show
[
“balance-region-scheduler”,
“balance-leader-scheduler”,
“balance-hot-region-scheduler”,
“label-scheduler”
]