【 TiDB 使用环境】生产\测试环境\ POC
生产
【 TiDB 版本】
5.4.1
【遇到的问题】
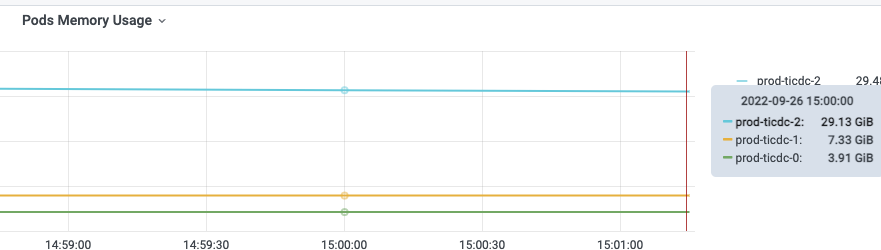
k8s搭建的ticdc集群任务分配不均匀,一个三个节点,每个pod资源上限16c64G,只有owner节点内存压力很高,能占到30+G,其他两个节点,内存占用都是10G以下。
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
【附件】
【 TiDB 使用环境】生产\测试环境\ POC
生产
【 TiDB 版本】
5.4.1
【遇到的问题】
k8s搭建的ticdc集群任务分配不均匀,一个三个节点,每个pod资源上限16c64G,只有owner节点内存压力很高,能占到30+G,其他两个节点,内存占用都是10G以下。
【复现路径】做过哪些操作出现的问题
【问题现象及影响】
【附件】
owner 节点的资源消耗比其它节点大是正常的。
综上所述,owner 节点资源消耗比其它节点高属于正常现象。
此外,还有一种可能是,owner 节点里面 processor 角色分配到的某张表的写入流量较大,则它可能会消耗较多的资源。
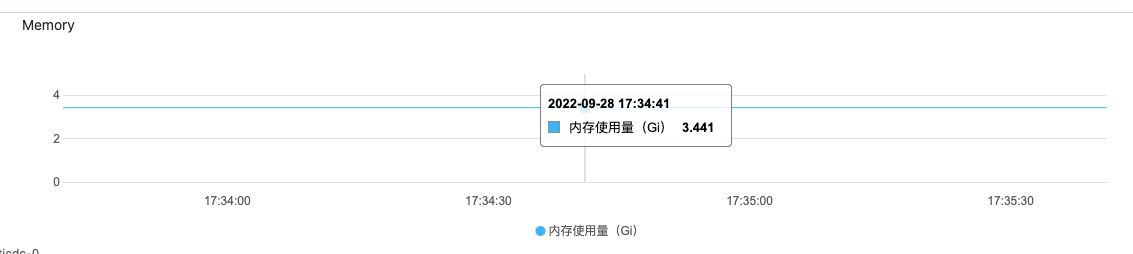
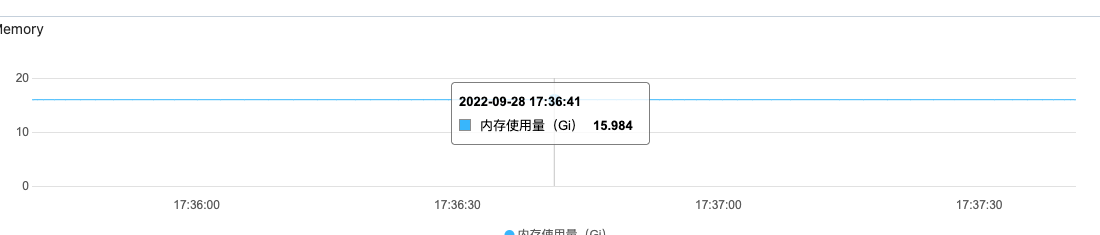
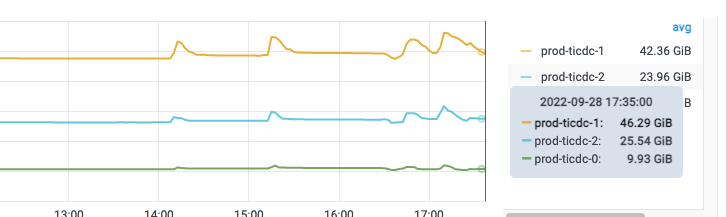
但是这个差距也太明显了吧。owner节点高的时候40G+,但是其余节点都是维持在10G一下。
关于changefeed里面的table,是如何负载均衡的呢?
均衡的源码在哪个文件里面呀。
帖子别沉啊 求大佬回复
CDC 现在是按照表的数量来进行负载均衡调度的,而不是根据表的流量进行负载均衡调度。因此当流量大的表被调度在 owner 节点的时候,owner 节点的资源消耗可能就会比较高。
另外一点,管理 changefeed ,并且对每个 changfeed 都维护一个 schemaStorage 是比较消耗内存的。
关于 v5.4.1 表调度的代码主逻辑在这里:https://github.com/pingcap/tiflow/blob/v5.4.1/cdc/owner/scheduler_v1.go#L71
关于 v5.4.1 owner 需要维护的 schemaStorage 的逻辑在这里:
https://github.com/pingcap/tiflow/blob/v5.4.1/cdc/owner/schema.go#L49
能麻烦说下上游 TiDB 集群的总共的库表数量吗?
上有的tidb主要使用一个数据库,库里面有1000+表。
cdc的同步 changefeed一共120+,每个changefeed监听一张表。
owner内存高的原因,是不是因为changefeed数量太高了呢?
还是说一个changefeed里面配置多张table才是合理的用法呢?
是的,多个 changefeed 会对 owner 带来较大的负担,因为对于每一个 changefeed owner 都会维护一份上游所有表的 schemaStorage,对于你的场景来说,就是 120 * 1000 = 120,000 份 tableInfo。除此之外,还有别的本来表和表之间共享的资源也会被创建多份。
对于普通的表,建议采取一个 changefeed 同步多张表的方式进行同步。
对于那些可能会产生较大事务和较大流量的表,再使用单独的 changefeed 进行同步。
我试过一个changgefeed里面监听5个table。3个节点,监听的table数量相对均匀,分配为2 2 1.
那如果一个changefeed里面监听1个table,3个节点,会优先分配到owner节点吗?
会进行均分,不会优先分配。
另外两个节点资源不均衡就是由于表的流量不均匀造成的,你可以先看看哪张表的流量比较大,然后使用 api 调度那张表到资源消耗较低的节点上:https://docs.pingcap.com/zh/tidb/v5.4/ticdc-open-api#手动调度表到其他节点
![]()
![]()
![]()
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。