【 TiDB 使用环境】调研
【 TiDB 版本】6.2
【遇到的问题】做主键的Index Lookup Join时效率低下
【问题现象及影响】
执行计划问题.txt (13.1 KB)
我在模拟Index Lookup Join观察执行效率时发现在读取内表数据时效率特别低(故意关闭了tidb端的缓存,多次重复执行后都是大约2秒左右)。
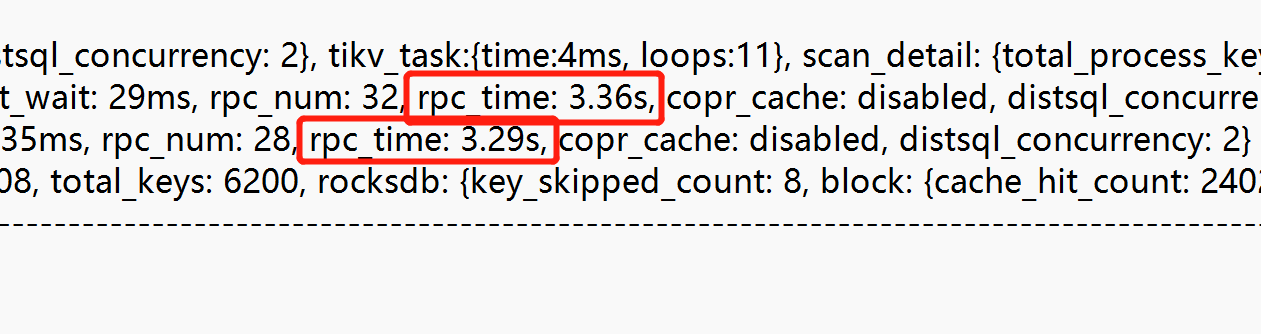
如附件中执行计划1所示内表是用主键C_CUSTKEY来做关联,在算子TableReader_56(Probe)中看到最大的一次cop_task任务需要363.3ms,max_proc_keys: 636 (通过total_process_keys: 6196,total_keys: 6200可以推测出max_keys也不会超过640),也就是扫描636个key而且都是内存读(block: {cache_hit_count: 24023},可以认定没有发生物理读),为何需要这么高的时间呢?
为了做对比模拟,直接单独查询customer表的主键C_CUSTKEY,模拟全内存读,扫描记录数大于640(这里设置为1000),反复多次试验找花费时间最久的一次,如附件执行计划2所示,可以看出tikv扫描total_process_keys: 999时几乎不花费时间。
所以请教下,记录数不大的关联,走主键索引的情况下还会出现这么慢的情况?
补充trace执行情况:
trace执行时间.txt (25.0 KB)
单看外表通过索引过滤的查询也是慢:select count(O_CUSTKEY) from orders b where b.O_ORDERDATE =‘1996-12-14’ 实际结果才6k多,但需要花费1秒多。
具体数据见附件:orders拆步单表查下慢数据.txt (16.0 KB)
看执行计划,效率差的SQL的现象是:cache_hit_count 远大于total_keys。也就是不知道为何做了那么多次的cache_hit_count,这个cache_hit_count是不是指的rocksdb的block的读取次数呢?