版本:v5.2.3 arm
问题:
中午14:00多发现CDC 异常,检查下游写入为0,cdc cli 检查有如下报错:
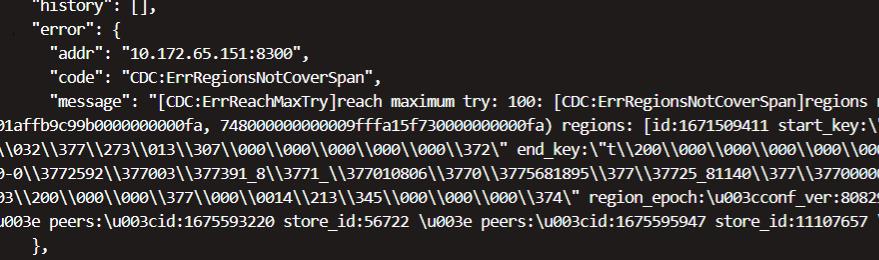
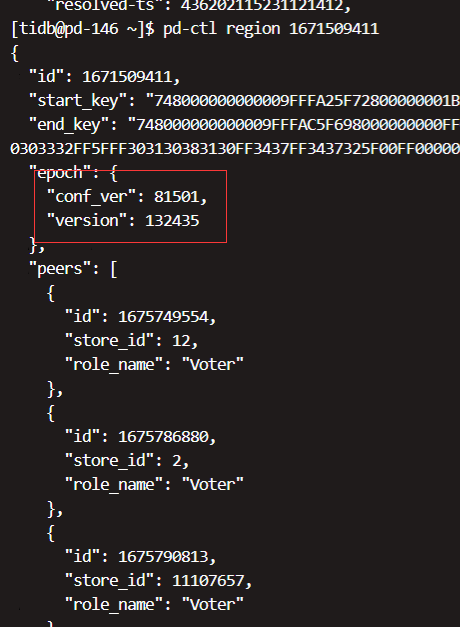
code": "CDC:ErrRegionsNotCoverSpan", "message": "[CDC:ErrReachMaxTry]reach maximum try: 100: [CDC:ErrRegionsNotCoverSpan]regions not completely left cover span, span [748000000000009fffa15f72800000001affb9c99b0000000000fa, 748000000000009fffa15f730000000000fa) regio ns: [id:1671509411 start_key:\"t\\200\\000\\000\\000\\000\\000\\237\\377\\241_r\\200\\000\\000\\000\\032\\377\\273\\013\\307\\000\\000\\000\\000\\000\\372\" end_key:\"t\\200\\000\\000\\000\\000\\000\\237\\377\\254_i\\200\\000\\000\\000 \\000\\377\\000\\000\\001\\00100-0\\3772592\\377003\\377391_8\\3771_\\377010806\\3770\\3775681895\\377\\37725_81140\\377\\3770000032\\377_\\377010810\\37747\\377472_\\000\\377\\000\\000\\000\\373\\003\\200\\000\\000\\377\\000\\0014\\21 3\\345\\000\\000\\000\\374\" region_epoch:\u003cconf_ver:80829 version:132267 \u003e peers:\u003cid:1675591530 store_id:11107291 \u003e peers:\u003cid:1675593220 store_id:56722 \u003e peers:\u003cid:1675595947 store_id:11107657 \u003e ]"
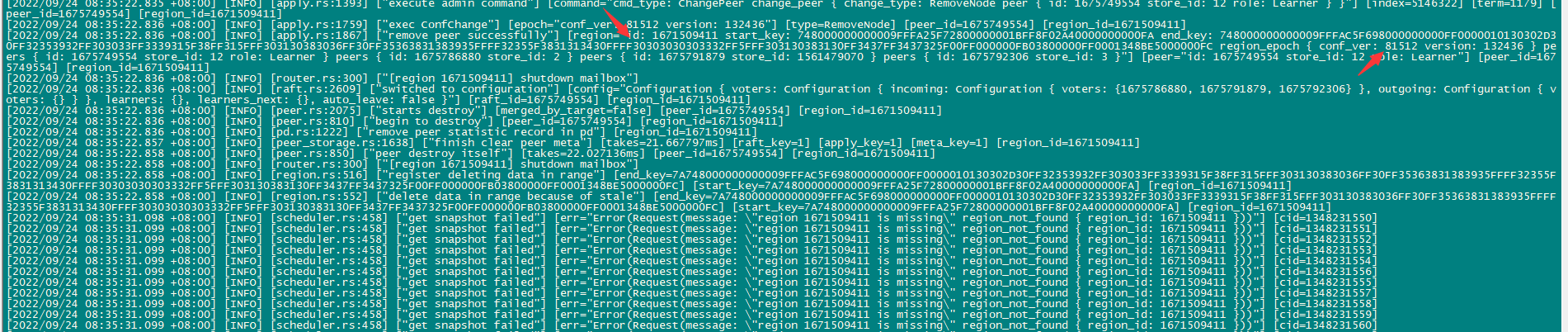
根据 错误信息 找到如下 已知问题: ScanRegions total retry time is too short · Issue #5230 · pingcap/tiflow (github.com) 该问题可能在5.2版本中目前没有修复,于是重启了cdc ,之后正常 ,过了一会后恢复正常,开始往下游写入数据, 18:00左右 再次检查发现下游写入出现断断续续的情况,于进行2次重启后恢复正常,一段时间后又不正常了。
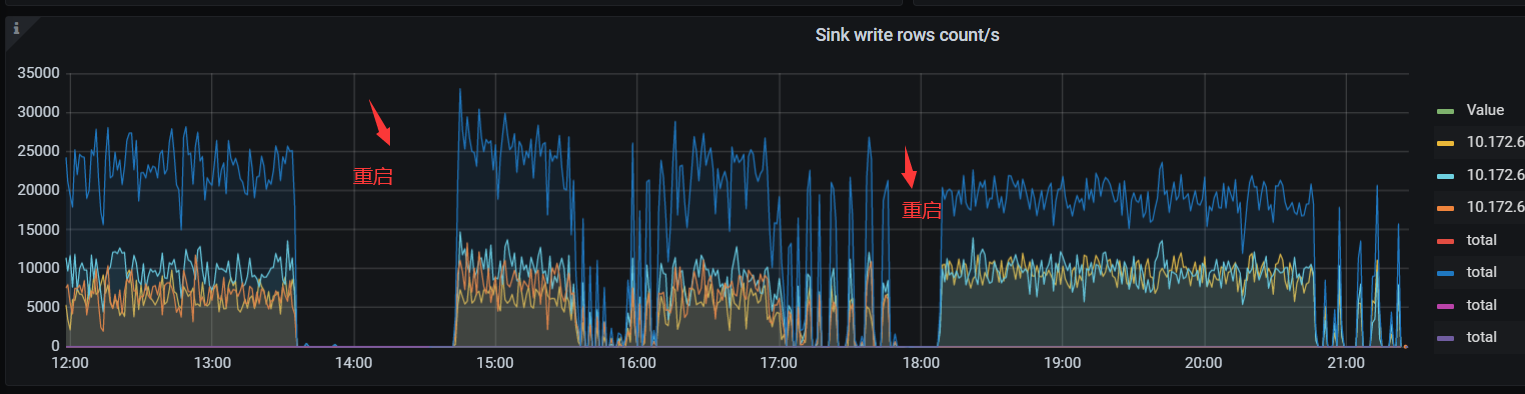
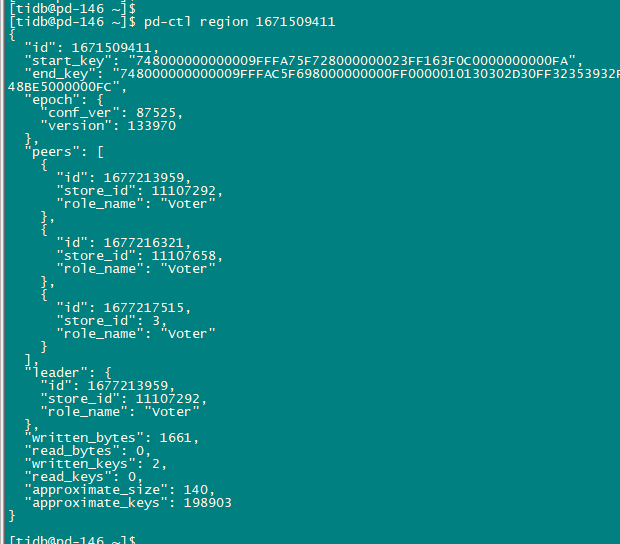
后2次重启cdc 检查changefeed 状态 仍然显示相同错误

等待CDC开始往下游写数据后,检查cdc 状态仍有上述报错,似乎下游写入问题和这个报错没有关系。

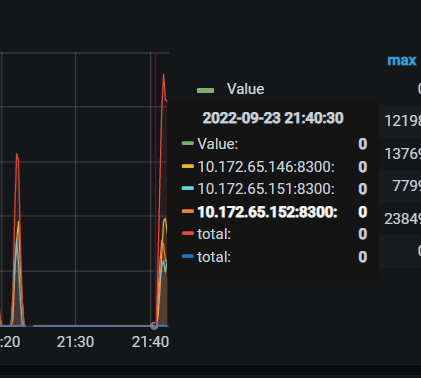
146节点日志
cdc.log.tar.gz (13.3 MB) cdc-2022-09-23T20-28-40.335.log.gz (18.3 MB)
151节点日志
cdc-2022-09-23T13-36-18.561.log.gz (17.1 MB) cdc-2022-09-23T17-52-35.450.log.gz (19.2 MB)
152节点日志
cdc-2022-09-23T17-32-17.523.log.gz (16.9 MB)
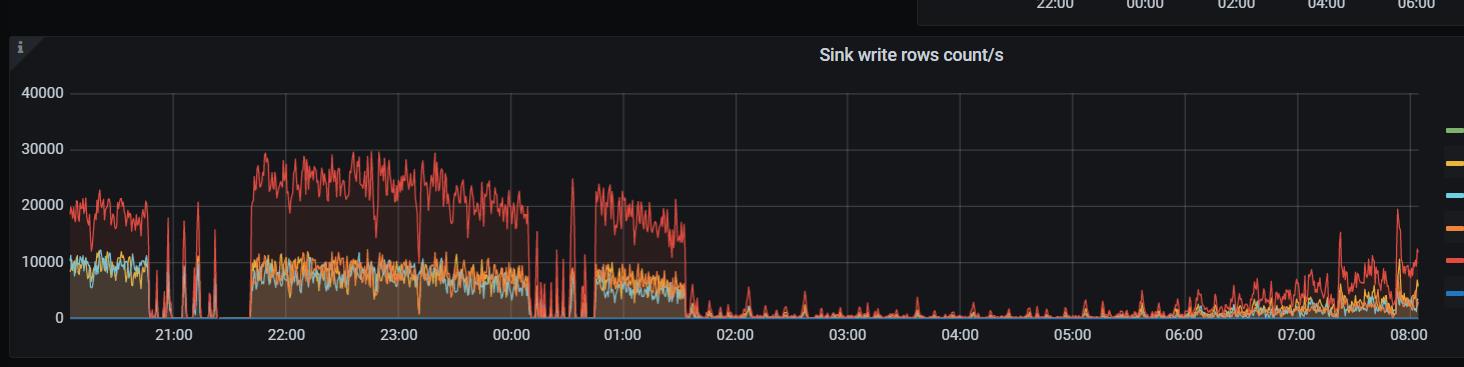
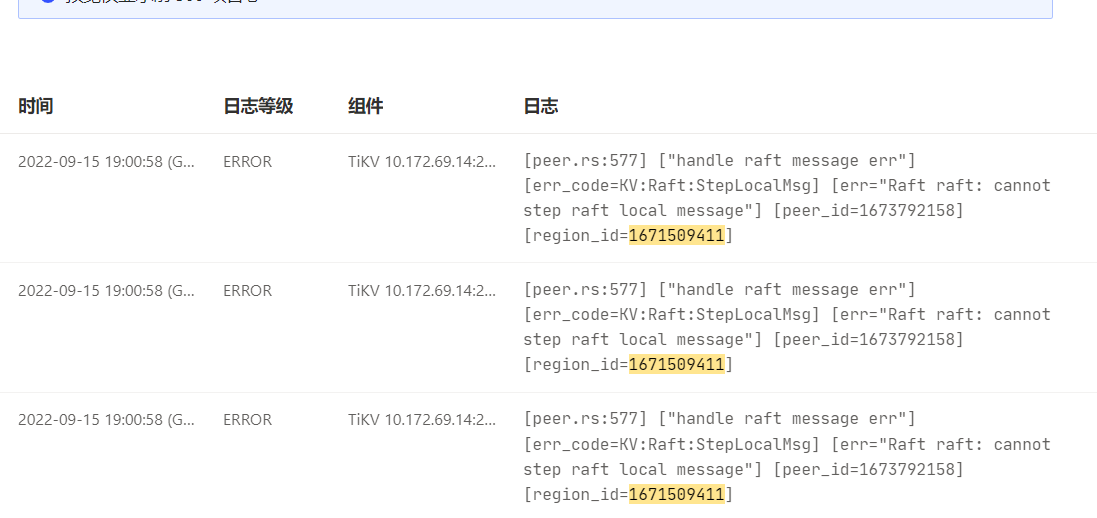
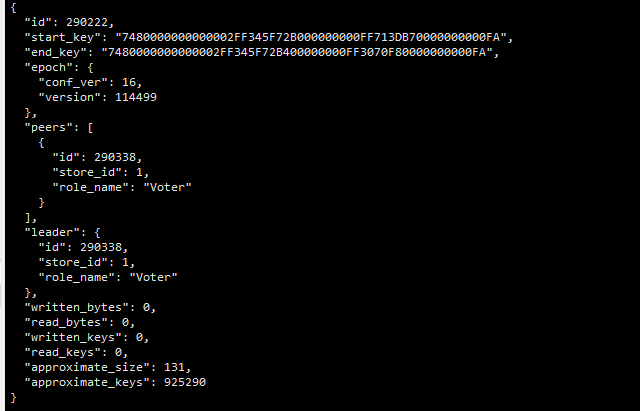 我这个是从库用的单副本的
我这个是从库用的单副本的