看了TiDB V6的PiTR文档后(https://docs.pingcap.com/zh/tidb/v6.2/point-in-time-recovery),有点疑问:
假设一个分布式事务DT1在三个节点是执行:
A节点 1s800ms
B节点 1s950ms
C节点 2s100ms
在每个节点上的binlog应该都是按照这个时间记录的,如果我指定时间点恢复是2s000ms来恢复,A和B应该是回滚成功的,但是C节点因为在2s100ms才commit,应该是不会加载成功的,这样就导致了DT1这个分布式事务在C节点上缺少了一个子交易。
在TiDB的PiTR设计里边是否会根据分布式事务的记录,把C节点的恢复时间往前移动一点,把这个2s100ms的子交易前滚回来呢?
yilong
(yi888long)
2
感谢答复,两阶段提交的commit ts我相信能够保持一致,因为申请到的tso都会给到分布式交易的多个节点,但是不同节点执行的时候并不能保证同一时间完成,因为不可能所有节点都去做消息沟通说我们一起完成(硬件延迟、网络延迟等情况),所以记录到不同的binlog中的子交易完成的时间一定会不同,我的疑问刚好在这里:如果ABC三个节点完成的时候不同,我给定一个时间去做回滚,ABC如果接受我的时间,而不去处理这个分布式交易恢复的一致性,就会出现丢失子交易的情况。而如果要去记录这个分布式交易,就需要保存所有的分布式交易所涉及到的节点。
这个问题不是生产的时候会出现的问题,而是在做PiTR的时候会出现的问题。需要了解更多一点PiTR的实现细节,关于分布式交易一致性的问题。
在进行 PITR 需要的备份的时候,A、B、C 节点都会定期记录下属于自己节点的 local checkpoint ts,代表着该节点上 txn commit ts 早于 checkpoint ts 的数据都已经被备份下来了。然后计算所有节点的最小 checkpoint ts 就是备份 global checkpoint
进行指定时间点恢复的时候,PITR 只能恢复 global checkpoint 之前的时间点,这就保证了不会有数据丢失。
这是 PITR 的保证, 与数据写入时间无关。比如按照上面给的例子,如果 DT1 的 comit ts < 2s000ms ,用户指定恢复到 2s000ms 恢复,但是 C 的 DT1 数据还没备份下来时,PITR 是会报错不能恢复的
设计概要可以看这个 https://github.com/pingcap/docs-cn/blob/57c080287da40c3b4f44ff8684c045fc818a140e/br/br-log-architecture.md
2 个赞
我理解楼主的意思是担心即使分布式事务拿到了相同的 commitTs ,但是 primary key 先持久化 commitTs 后就认为事务提交了,其他 key 是一个异步的过程,可能会导致 PiTR miss 掉一部分数据。
这是不会的。因为其他 key 没有持久化 commitTs 之前,其他 key 的记录上会有 startTs 的 lock 记录,PiTR 遇到这种 lock 记录会根据事务状态推进或者删除锁,只有等待锁处理之后才会推进 local checkpointTs。
也就是说即使其他节点的 local checkpointTs 已经推进到了某个 commitTs 10,但是只要还存在一个节点的 commitTs 10 还没有提交,那这个节点的 local checkpointTs 就是 9, 这个时候 global checkpointTs 还是 9, 没法保证 commitTs 10 的事物能完全恢复。
1 个赞
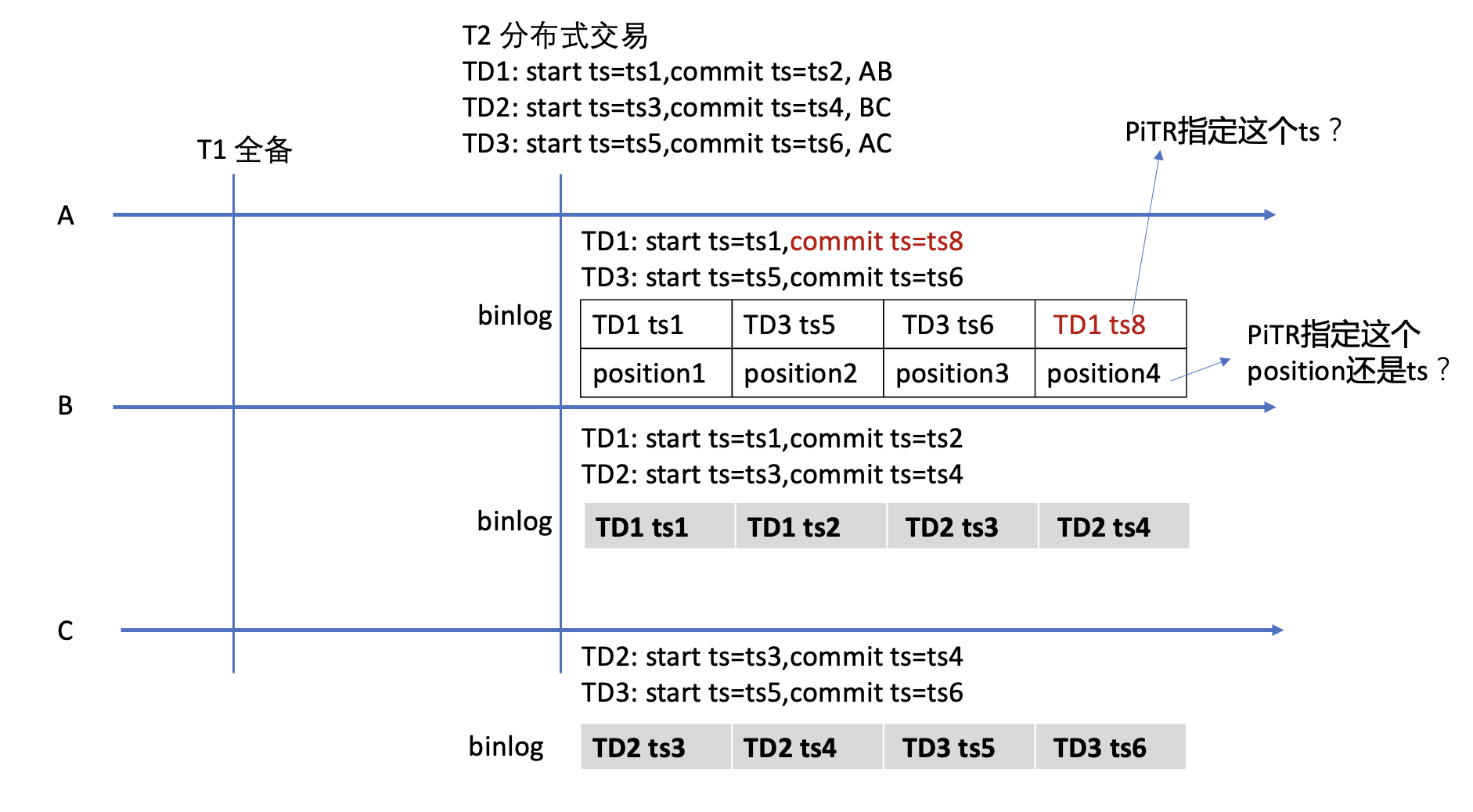
感谢两位的答复,我学习到了很多知识,但是我仍然是有疑问的,我画了一张图。
假设三个节点A、B、C,在T1的时候做了全备份。
然后在T2时刻有三个分布式交易TD1、TD2、TD3,分别的start ts和commit ts图上有表达。
第一个问题是:Tidb在做PiTR的时候,每个节点的binlog恢复是指定commit ts去恢复日志?还是类似mysql的binlog中只能指定position或者local timestamp去恢复?
在第一个问题中,如果是指定commit ts去恢复,那么就要求分布式交易在每个节点上,将binlog中的日志按照TD1、TD2、TD3这样合并成一个完整的交易去进行日志加载,是这样实现的吗?
如果是类似mysql指定local的position/ts去恢复,那么就要保证在pd拿到的ts靠前的先处理,而且要等这个交易提交成功后才能提交其他的,否则就会出现TD1、TD2、TD3不是顺序而是乱序的情况。
在这种情况下,我可以比较轻松的模拟一个交易TD1,在B节点拿到commit ts=ts2之后,很正常的执行完成了,对应的B节点的local ts也是ts2(NTP保障节点间时间一直,但仍然可以有200ms以上的误差)。而在A节点上,因为某些原因,TD1 的local commit ts并不是ts2,而可能是ts8或者更后面的时间。
这时候,我们采用PiTR指定一个时间点ts2去加载日志,此时B节点几乎正常的加载了TD1的交易,而A节点因为TD1的local commit ts时间是ts8,所以势必就会丢失,造成TD1在做PiTR的时候出现B节点有,而A节点没有的情况。
@maxshuang的答复中,我理解是备份时间点的时候会这么处理,而在PiTR的时候也是这样处理的吗?因为PiTR肯定只是加载日志。
@IANTHEREAL的的答复中,我能理解你想得到一个global checkpoint ts,但是如果只是根据每个节点的最小的local commit ts得出,而不考虑当时这个时间全局所有的分布式交易涉及到哪些节点去判断,实际上还是会出现某些分布式交易恢复不一致的问题。