tidb version: v6.1.1
集群内约4000张表,1.1T 存储空间,2.3万 region:
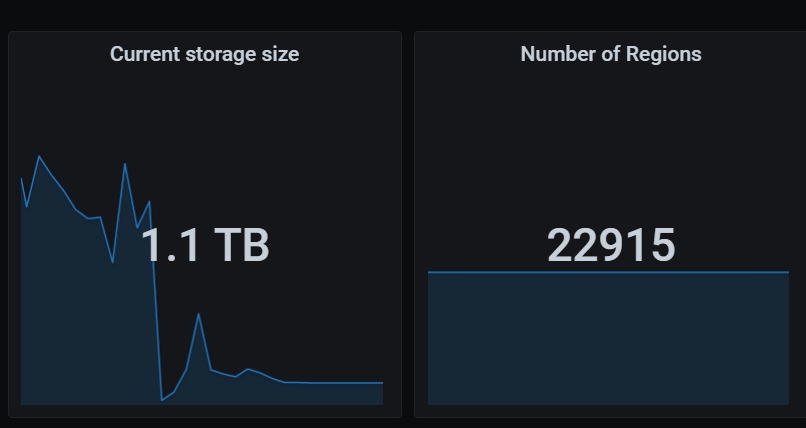
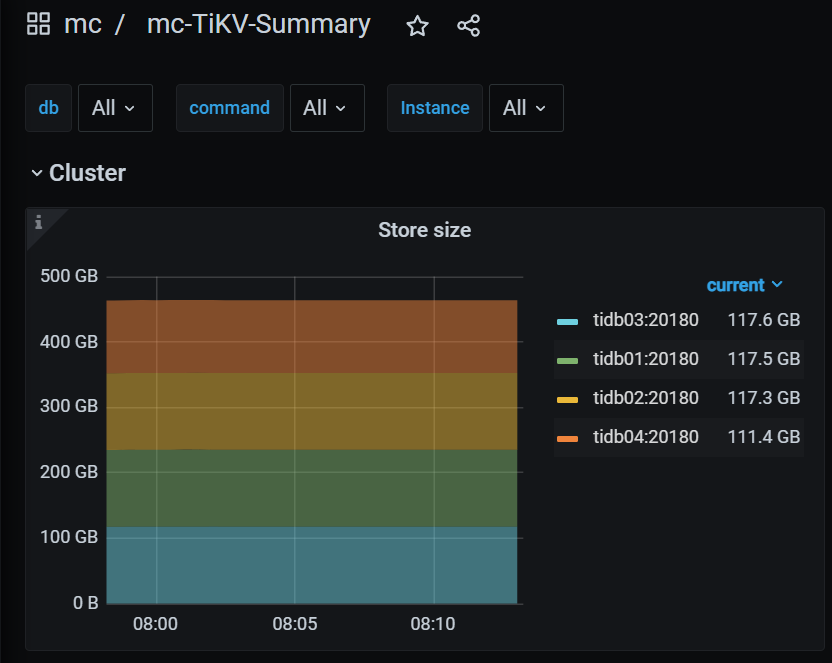
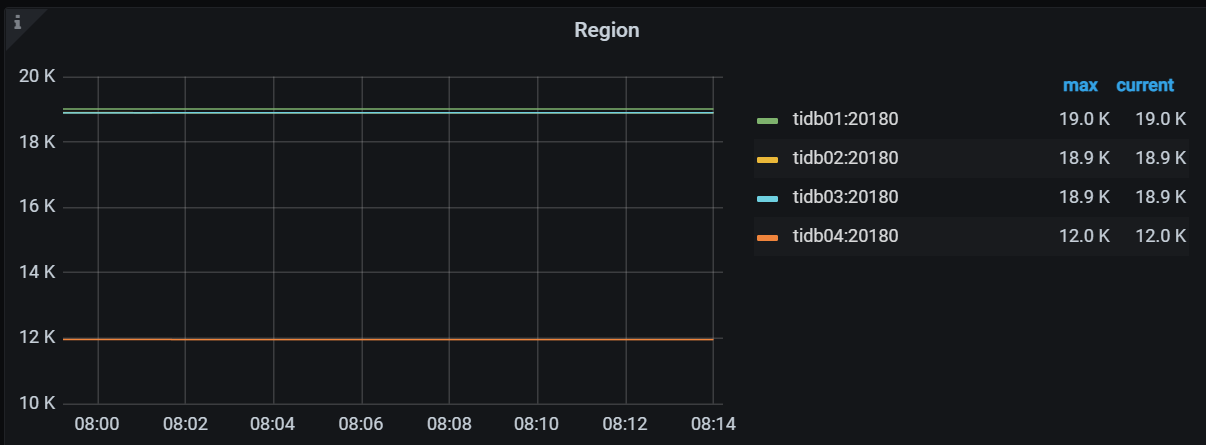
tikv的store size, leader, region如下:
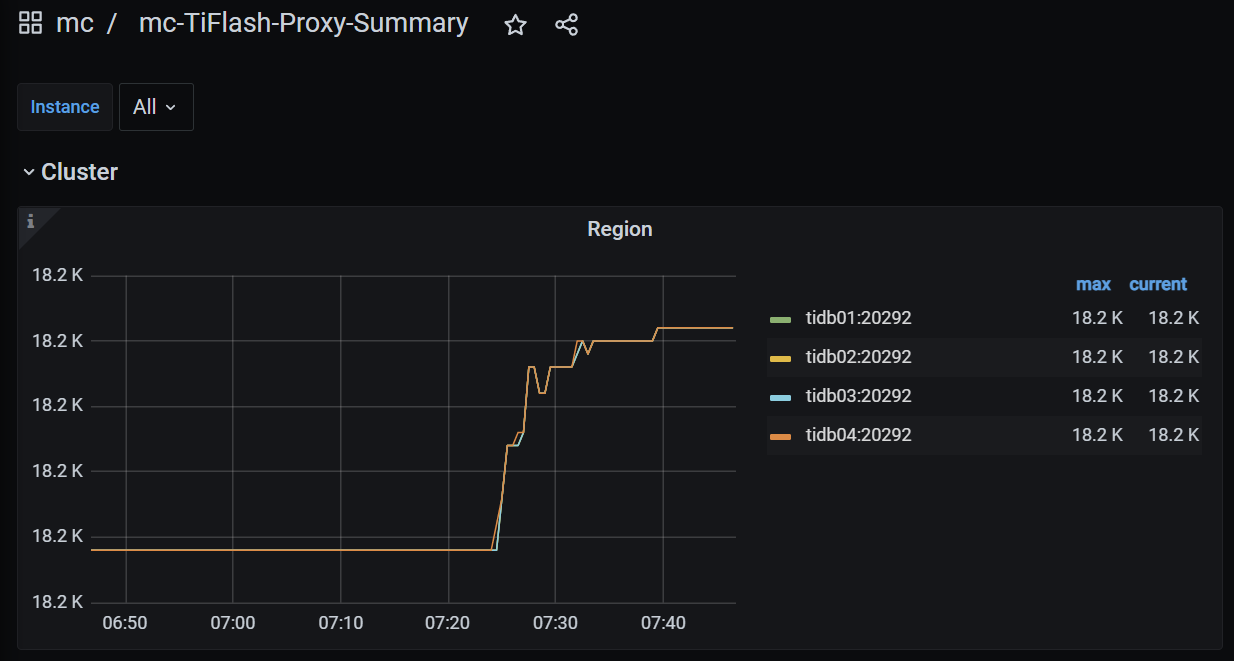
所有表都设置了tiflash副本数为4,共1.8万 region,4个节点完全对称
在该集群上执行压测,20并发回放约450万条SQL
4个tidb节点,连接均匀分布,cpu负载也较为平衡:
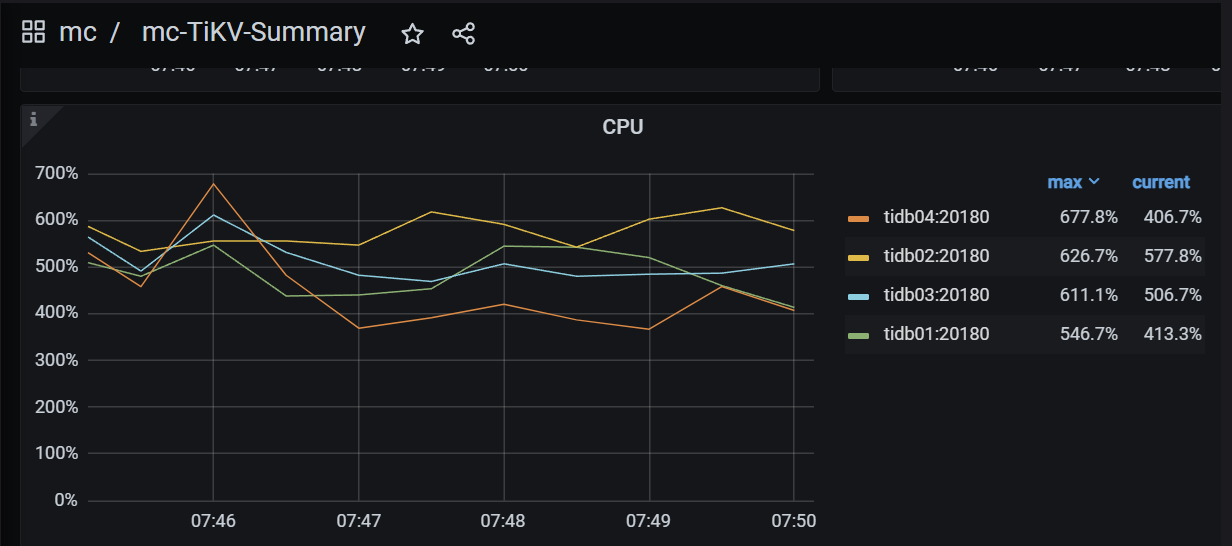
4个tikv节点的负载也较为平衡:
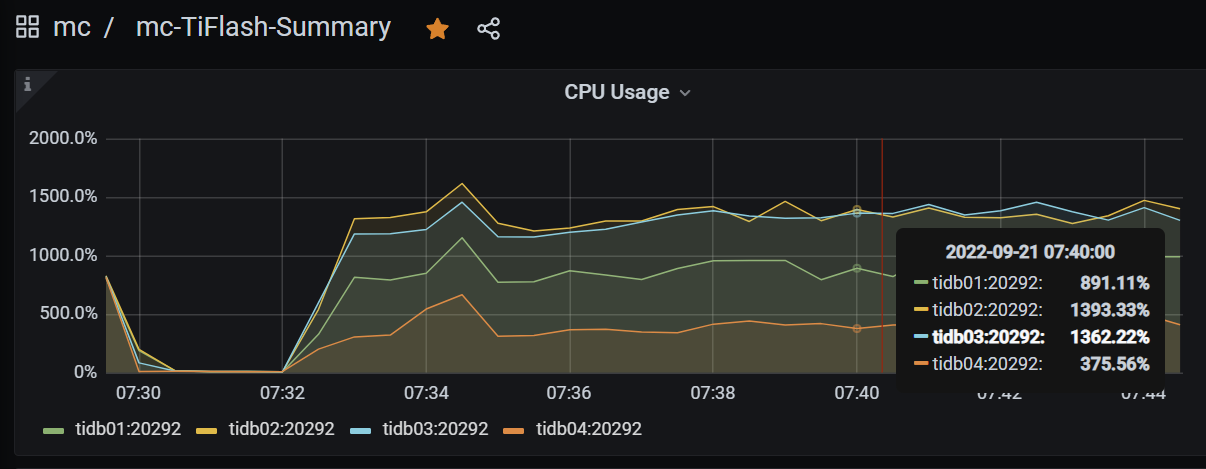
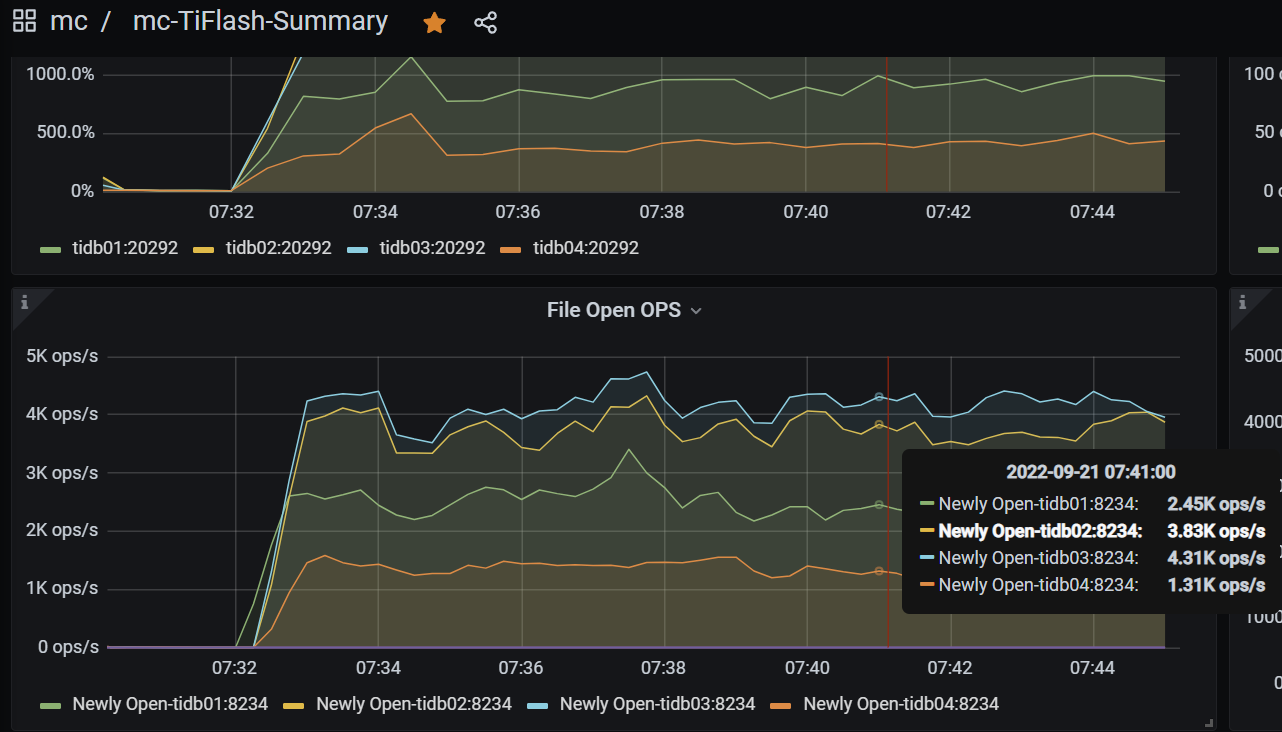
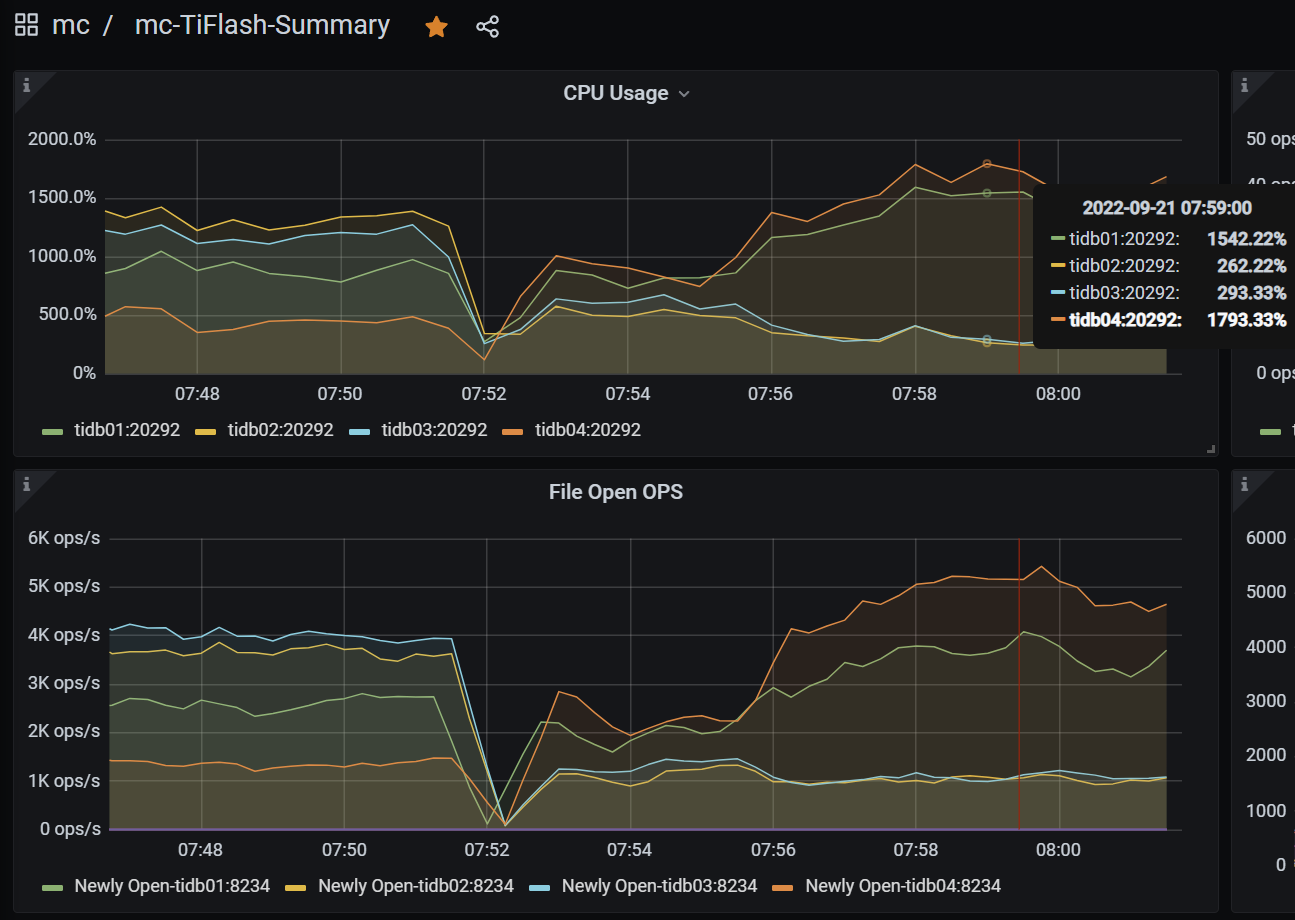
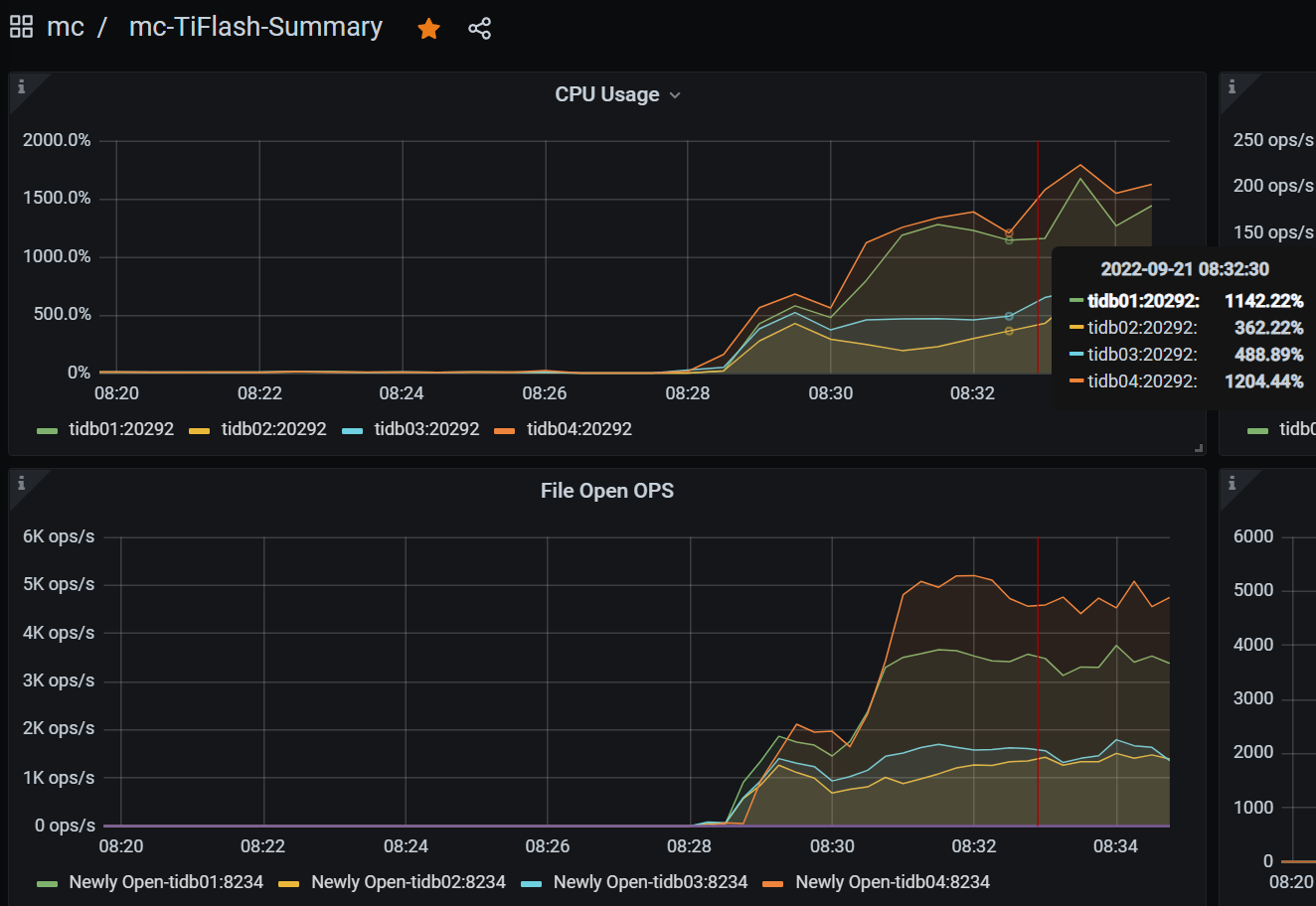
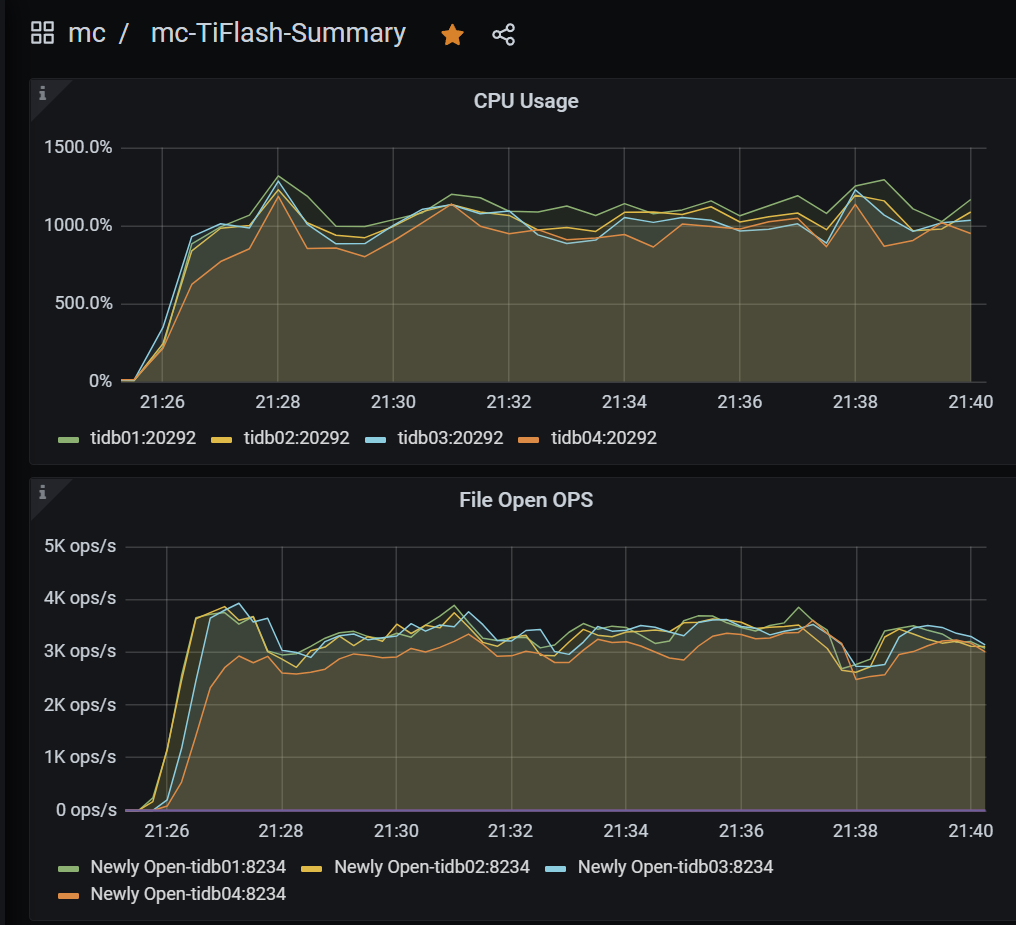
但是tiflash的负载非常的不平衡,打开文件数也同样不平衡,如图:
我注意到git上有关于此问题的issue,仍然是open状态:https://github.com/pingcap/tidb/issues/35418
按照issue中的描述,某个tiflash节点挂掉再恢复,tidb的region缓存会导致其上无负载
接下来我重启了整个集群(tiup cluster restart xxx -y)
我的问题是:
麻烦用这个工具 https://metricstool.pingcap.com/ 导出 tiflash-summary 监控
确实存在不同 tiflash 节点间请求不均衡的情况
目前 TiDB 在生成 TiFlash MPP 任务的时候,会根据这个表的所有 region 在所有 TiFlash 之间做一个均衡,比如如果这个表有 100 个region,那么 TiDB 会尽量保证每个 TiFlash 读 25 个 region,你们这个场景里面应该有 4 节点 4 副本,所以应该能保证每个 TiFlash 读 25 个 region 的。
继续请教一下:
如果是用 MPP 或者 BatchCop 访问 TiFlash 的话,是选择了一个 region 的副本之后一直用这个副本,直到这个副本上遇到错误,如果是用 cop 访问 TiFlash 的话,每次查询是会切换到下一个副本的。
这样确实解释了我这个现象了
我现实的业务场景,就是这个数据分布和SQL分布,tiflash资源就浪费了
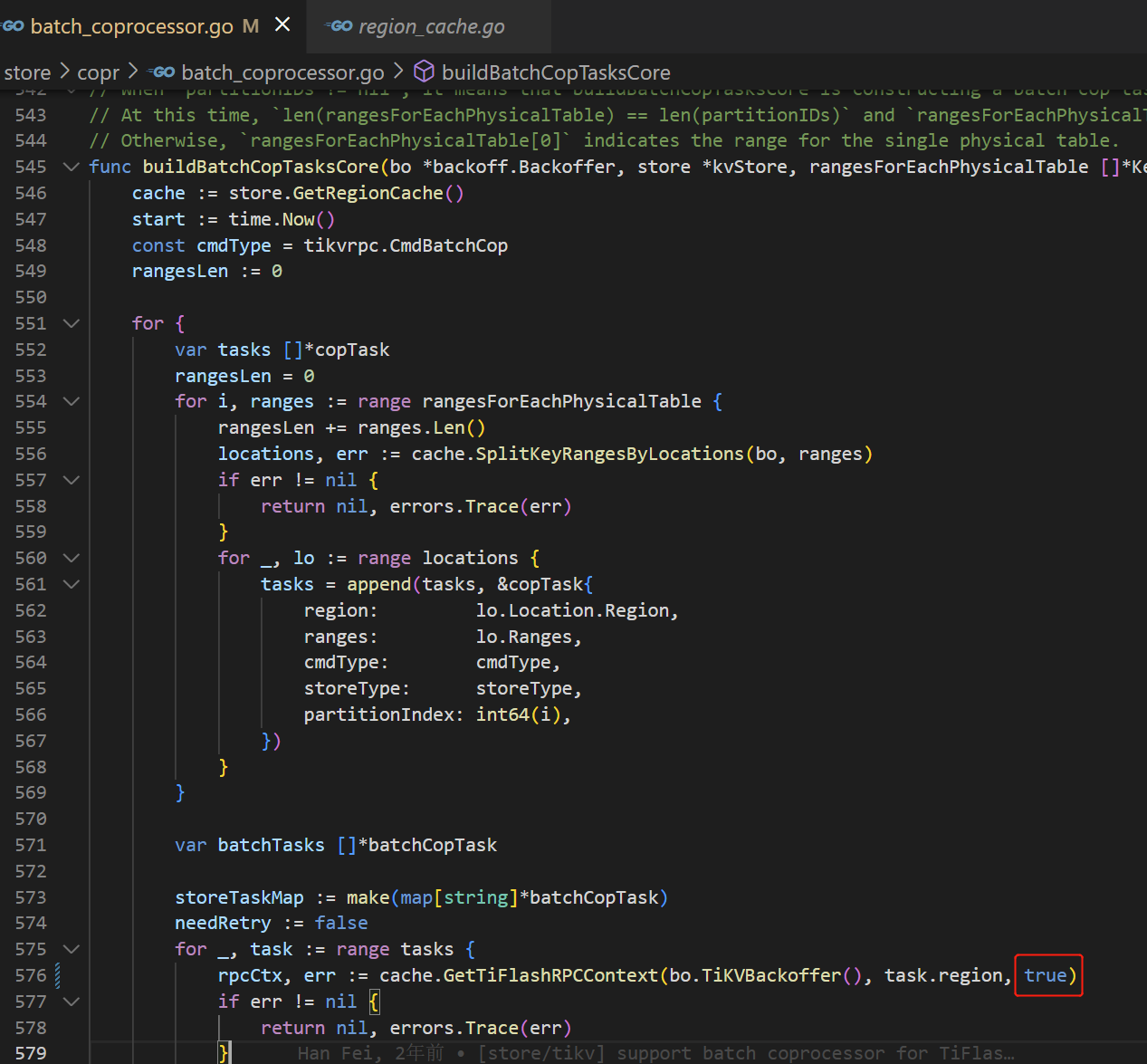
我研究了一下代码,把这个参数从 false 改为了 true
因为我发现 GetTiFlashRPCContext 函数内部,如果loadBalance= false 的话,总是返回找到的所有store中的第一个,就造成了热点,改为true的话每次会换一个。
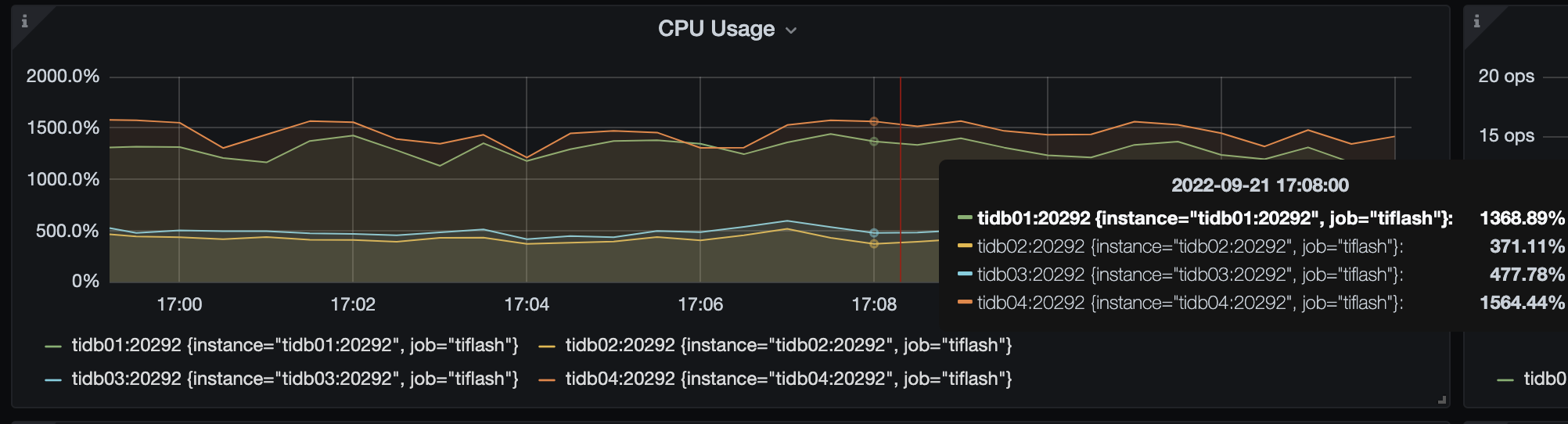
目前编译替换后,跑压测就完全平衡了:
但是不知道原来传入false是什么考虑,改为true了有什么副作用没?是不是就是注释里说的:loadBalance is an option. For MPP and batch cop, it is pointless and might cause try the failed store repeatly.
请专家指点
这个是历史原因造成的,目前对 MPP 来说,完全可以改成 true,batchCop 可能还有问题,但是因为 batchCop 基本上可以被 MPP 完全代替,所以改成 true 没什么问题。
如果不放心 batchCop 可以判断 mppStoreLastFailTime 是否为 nil,不为 nil 的话,是 MPP,为 nil 的话是 batchCop,这样可以只对 mpp 开启 region load balance
夜里跑完了全部压测,没有出任何异常情况
1 个赞
是的,我们加了 query 内之间的 load balance 之后忽略了 query 之间的 load balance 了,准备在最新的 tidb 上 fix 一下这个问题。
system
2022 年11 月 25 日 08:03
18
此话题已在最后回复的 60 天后被自动关闭。不再允许新回复。