blaine
(Blaine)
1
【 TiDB 使用环境】
【概述】生产环境的一个pd节点,出现内存告警。
【背景】没有做过什么操作
【现象】业务没有什么影响
【TiDB 版本】 v4.0.9
下面是排查的结果:
1.频繁收到下面的告警
告警主题: memory used more than 80%
告警详情: cluster: ENV_LABELS_ENV, instance: xxx.xxx.xxx.xxx:9100, values: 83.36075527667572
触发时间: 2021-08-01 21:49:05
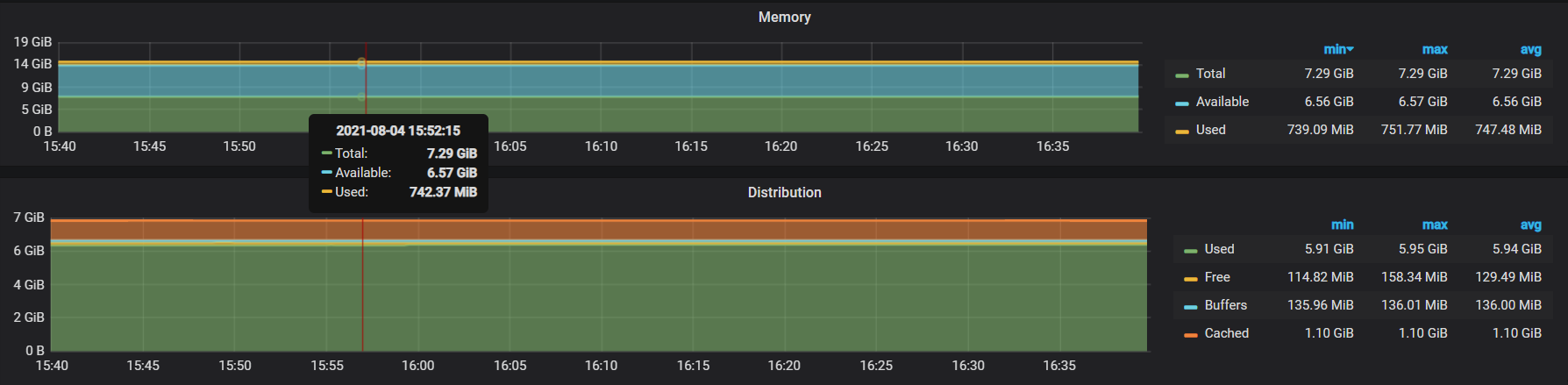
2.查看grafana-----》cluster-node-exporte里面的内存情况
发现总内存是7.29G,user内存平均是5.94G ,确实超过了80%
3.到这台服务器上查看内存情况
发现总内存7.3G,user内存才400多M,没有超过物理内存的80%
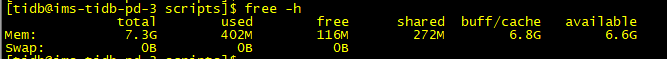
4.所以现在看来是服务器的物理内存使用和grafana上面告警的内存不符合,但是其他节点的又是正常的。怀疑是否是监控出现了问题,将监控grafama,prometheus,alertmanager,都重新启动了。还是出现这样的情况。现在不知道是哪个方面的问题导致的。
5.在grafana上面看到,内存使用计算是:
node_memory_MemTotal_bytes{instance=“$host”} - (node_memory_MemFree_bytes{instance=“$host”} + node_memory_Buffers_bytes{instance=“$host”} + node_memory_Cached_bytes{instance=“$host”})
发现node_memory_Cached_bytes 和服务器的不符,grafana上面收集的Cached是1.1G,而服务器上free查看的是6.8G,通过node_exporter查看结果
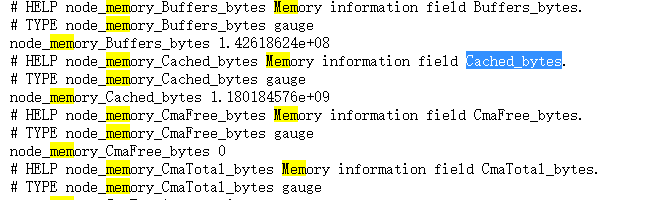
现在不知道是服务器free命令查看有问题,还是grafana收集的信息有问题,为什么cache收集的相差这么多?
blaine
(Blaine)
3
这里的分配内存说明一直都是5,9G左右。我已经选择就是同一台机器,也就是告警的那台机器,因为处于安全考虑,所以没有发具体的IP,触发时间是说明是那个时间点触发的,一直到现在都是这样告警,没有消除,所以一直告警。而告警计算的公式是:
node_memory_MemTotal_bytes{instance=“$host”} - (node_memory_MemFree_bytes{instance=“$host”} + node_memory_Buffers_bytes{instance=“$host”} + node_memory_Cached_bytes{instance=“$host”})
噢 我的错 确实报警时间是起始时间。
用 free 命令看到的 used 和报警说的 used 不是一回事。
告警的 prometheus rule 是 total - free - cache
(((node_memory_MemTotal_bytes
- node_memory_MemFree_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes)
* 100)) >= 80
你可以在 prometheus 的 rules 页面看到这个:
free 看到的是 buff/cache 两者的和,不是单独的 cache
你可以用 vmstat 2 5 看几条数据,这里对内存区分了 buff 和 cache (但是跟 node exporter 的计算是否完全一致 我没有去确认)
P.S.
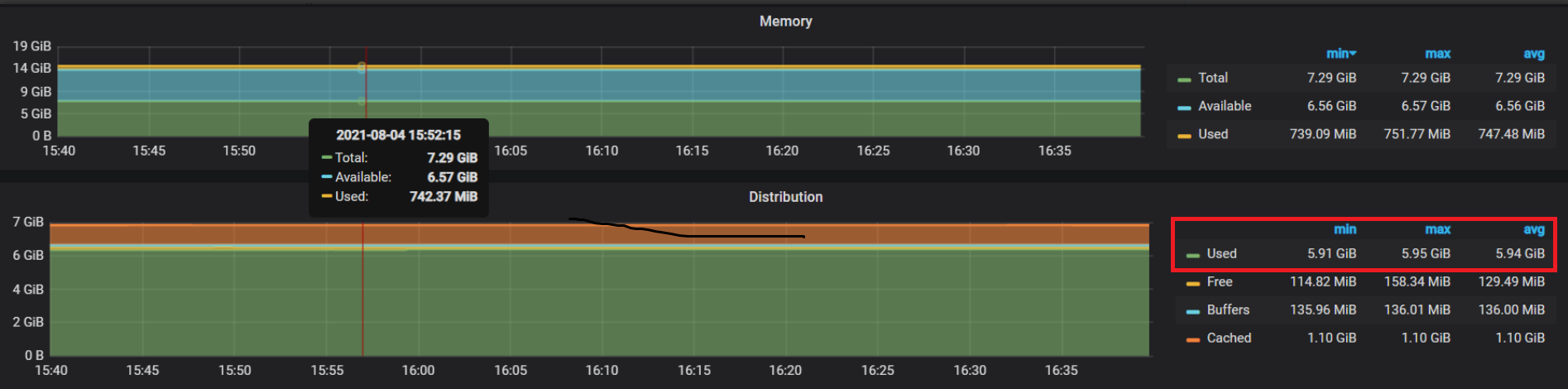
我看了 Grafana 作图用的表达式,你截图里的:上面 Memory 图 Used 和下面 Distribution 图的 Used ,表达式不一样,一个不包含 buff/cache 一个包含 buff/cache, 还都是一样的图例 Used, 而且还跟 prometheus 报警表达式不一致,好混乱
blaine
(Blaine)
5
vmstat 里面的Cached也是6.6G.
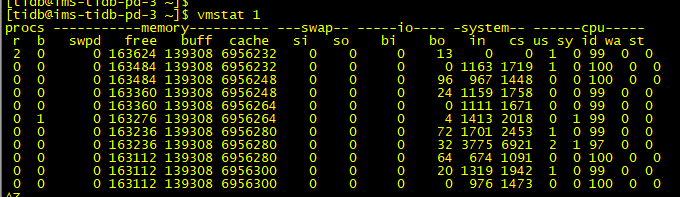
按照他的计算公式也没有超过啊。上面 Memory 图 Used 和下面 Distribution 图的 Used 是不一样的,我没参照这个看,因为在 prometheus 的 rules 页面看到这个:
是这样计算公式,那我把服务器和grafana上面对比,就是 Distribution 图的 Used 计算公式。但是对应的服务器却并没有超过80%。但是依然一直告警。所以不知道啥情况?
如果你要验证是不是误报,那你既不能用 free 命令验证,也不能用 Grafana 展示的那几个图来验证。
报警是 prometheus rule 决定的,你直接去 prometheus 里查这个, 值如果没有超过 80 是不会触发报警的。
(((node_memory_MemTotal_bytes
- node_memory_MemFree_bytes - node_memory_Cached_bytes) / (node_memory_MemTotal_bytes)
* 100))
system
(system)
关闭
7
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。