阿ken
(Aken)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】现网
【概述】场景+问题概述
tikv一节点磁盘损坏,就直接把这个节点缩容了。
后来这个节点磁盘修好了,就想把这个节点扩进来,结果发现有问题。
tikv.log 报错 [FATAL] [lib.rs:482] [“couldn’t find the OPTIONS file”]
【背景】做过哪些操作
对这个tikv节点,下线缩容,扩容。
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】
v4.0.12
【附件】
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
xfworld
(魔幻之翼)
2
建议旧的节点下线后,清理掉原来的信息,做为新的节点加进去
然后通过region 的平衡和调度,就自动的开始服务了,这样比较稳妥
阿ken
(Aken)
3
tiup cluster scale-in test-custer --force --node 10.33.25.22:20160
是执行这个命令,强制缩容的。tikv上的部署目录和数据目录都清理了。
xfworld
(魔幻之翼)
4
现在也是一样的,如果起不来,集群没这个节点的话,还是清理下信息,在重新入群就行了;
阿ken
(Aken)
5
清理什么信息,tiup cluster display 看 已经没有这个节点了
xfworld
(魔幻之翼)
6
就是原来的那个节点,通过 tiup 初始化之后的用户目录下的相关信息,全都删掉
数据信息也清理掉,什么都不要留
1 个赞
变又未变
(变又未变)
7
用pd-ctl store指令看一下,看看刚刚下线的节点还在不在,如果在的话,使用 curl -X POST http://:/pd/api/v1/store//state?state=Tombstone这个指令将刚刚强制缩容的tikv下线掉
阿ken
(Aken)
9
想问下执行缩容命令后
tiup cluster scale-in tidb-cluster --node 10.33.25.22:20160
大概多久才会到tombstone状态
如果期间用 http://:/pd/api/v1/store//state?state=Tombstone 这个命令强制 转为 tombstone 状态,会对集群数据有什么影响吗?
变又未变
(变又未变)
10
看数据大小的,数据越小,越快,
不好意思,刚刚指令写漏了store-ID,这个是将你刚刚强制下线的store给下线掉,因为有的时候,–force强制下线,pd中可能没有删除信息,用这个强制下线
这个对集群数据我觉得应该没有影响,我用过几次,数据都还在,可以研究一下,然后我们再讨论讨论:joy:
我curl -X POST http://pd的ip:pd的端口/pd/api/v1/store/<节点ID>/state?state=Tombstone
store-ID发不了。。。刚刚输入的store-ID,写不上
阿ken
(Aken)
11
想问下这种TiKV节点磁盘损坏,导致 tikv down掉 的情况,最好应该怎样处理呢。
我是直接把这个节点缩容掉,因为节点上的tikv-server已经挂了,所以需要等到节点状态变成 Tombstone 后,再修复磁盘吗?或者说,这个节点服务已经挂了,还能自己到 Tombstone 状态吗?
xfworld
(魔幻之翼)
12
6.3.2 TiKV 节点已经下线完成,如何重新上线 TiKV 节点
如果 TiKV 节点已经下线完成,想要重新将该 TiKV 节点上线,可以删除该节点上 {deploy_dir}/data 以及 {deploy_dir}/log/tikv* 相关历史文件后,参照扩容 TiKV 步骤进行扩容,但是需要注意:
- 如果是正常下线完成,等待 TiKV 节点状态变为 Tombstone 后,可以直接参照扩容 TiKV 步骤进行扩容
- 如果未正常下线,需要修改 tikv_port 端口,与原先该节点上的 tikv_port 不一致,因为 tikv 节点的信息会以 IP + tikv_port 作为唯一标识记录在 PD 中,目前该信息无法从 PD 中清除,所以需要更换 tikv_port 后重新上线。
6.4 PD 缩容操作回退
PD 组件缩容过程中如果有异常或者想取消缩容,可以按照扩容步骤重新操作即可,但在执行扩容操作之前需要删除 {deploy_dir}/data.pd 以及 {deploy_dir}/log/pd* 相关历史文件再进行扩容步骤。
建议参考这个文档:
阿ken
(Aken)
13
文档看过了,还是有两个疑问哈,辛苦帮忙解解惑。
1,上一个磁盘坏掉的TiKV节点 A,服务已经down掉,我是直接执行的 tiup scale-in 命令缩容,但是看它的状态一直不变,就手动执行了 curl -X POST http://127.0.0.1:2379/pd/api/v1/store//state?state=Tombstone,将节点状态置为 Tombstone,请问这样会对集群数据有影响吗?,然后执行了 tiup cluster scale-in tidb-cluster --force --node 10.33.25.22:20160 强行从集群中删除这个节点。刚才我再将A节点扩进来,ip 和 port 都没变,看起来是扩成功了。。。。
2,现在又有个tikv节点磁盘挂掉。。。。想问下服务挂掉了,下线节点后他还能变成Tombstone状态吗?还是需要自己手动
阿ken
(Aken)
14
扩容了一个节点后,看grafana 上的 TiKV ,每台机器上 leader 和 region 没有下降,也并未出现新扩容的节点。
xfworld
(魔幻之翼)
15
问题1: 数量影响
答: 这个取决于副本的数量,按照默认的一般是3节点,3副本,其中一个节点挂掉了,还有2个节点上都拥有副本数据,就不会有任何影响。然后扩容节点后,按照region和调度的配置,会同步节点上的副本数据
问题2: 又挂了
答: 可以观察下状态,如果等了很久还没自动更新状态,可以手动处理;
阿ken
(Aken)
16
扩容了A节点后,看grafana 上的 TiKV ,每台机器上 leader 和 region 没有下降,也并未出现新扩容的节点。
应该怎么样检测tikv是否扩容成功呢?tiup cluster display 看是没问题的,看节点tikv日志也没问题,data目录也在涨,虽然比较慢。
xfworld
(魔幻之翼)
17
阿ken
(Aken)
18
是集群中有节点down,prometheus重启没完成导致的。
现在看这台tikv的 region数 和 leader数在慢慢上升了,但是很缓慢,正常tikv上的都有50k leader,150kregion。已经一个小时了,新扩入的tikv上只有3k region,3k leader,是不是这3k region 全是 leader?
我调整了下面两个参数:
“leader-schedule-limit”: 64,
“region-schedule-limit”: 64,
但是发现没什么变化。
查看pd日志发现有大量的 [“operator canceled”] 日志如下:
[“operator canceled”] [region-id=13014892] [takes=0s] [operator="“balance-leader {transfer leader: store 6 to 35913828} (kind:leader,balance, region:13014892(27718,1499), createAt:2021-07-30 19:27:29.282207391 +0800 CST m=+6252729.714218083, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, steps:[transfer leader from store 6 to store 35913828])”"]
35913828 就是新扩入的store id,这是不是有问题?
xfworld
(魔幻之翼)
19
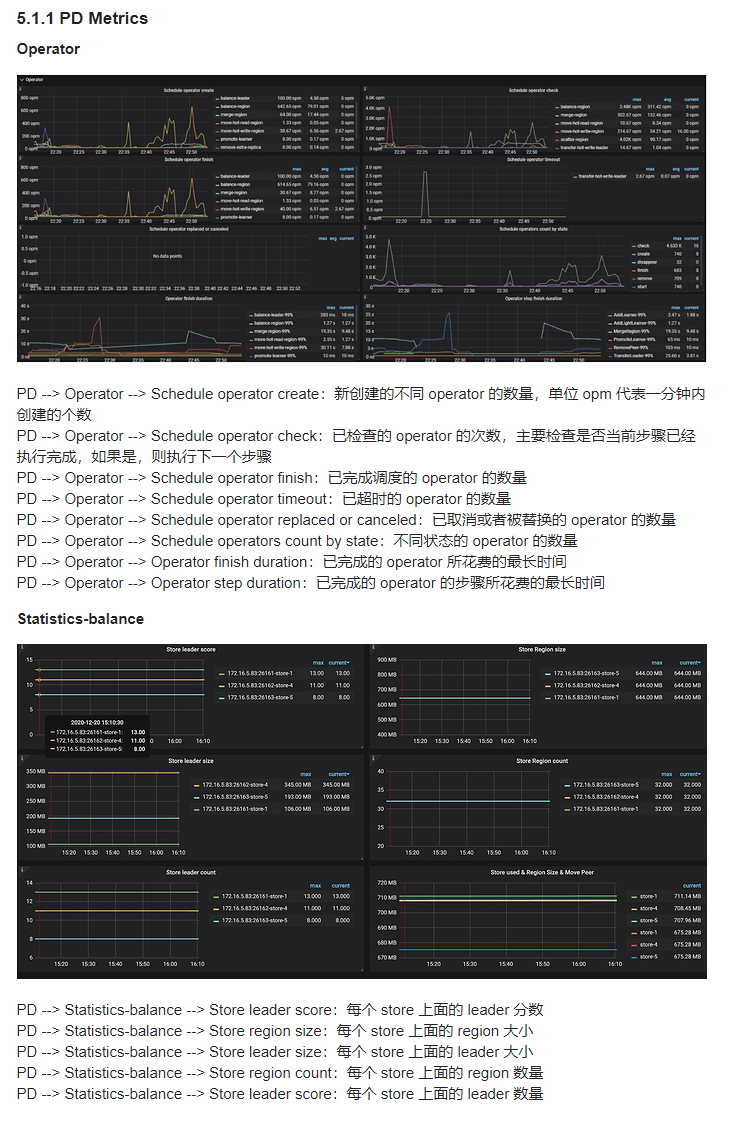
可以参考下监控指标,看下实际的结果是不是达到预期了
system
(system)
关闭
20
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。