1.环境背景:
使用ticdc 将集群A 的数据同步到集群B 。版本: 5.1.0
集群A 拓扑信息如下:
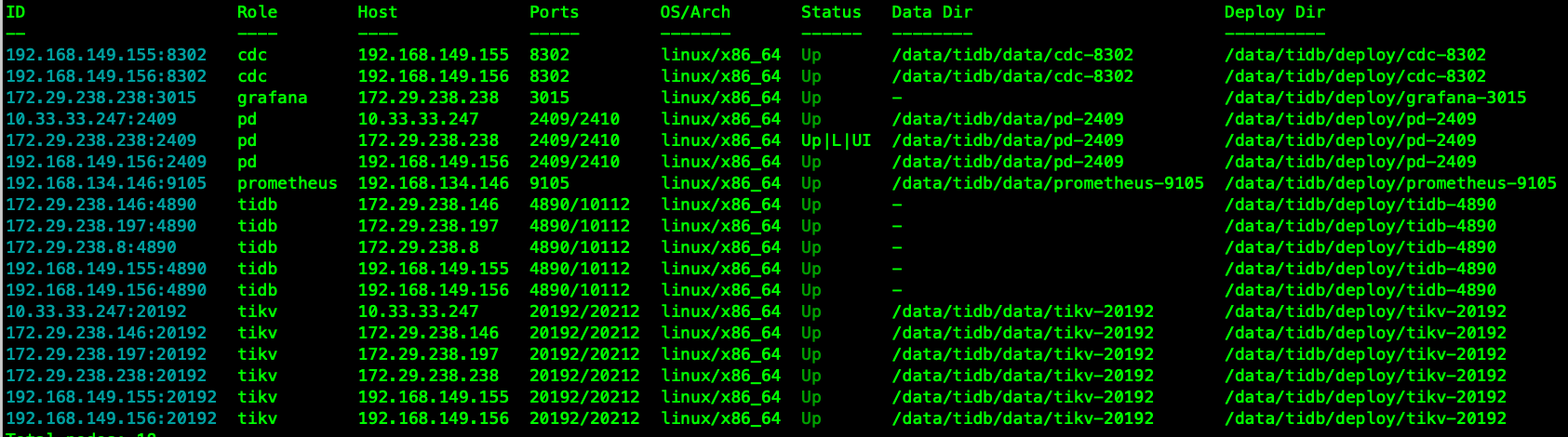
集群B 的tidb-server 之一为: 172.29.238.238:4920
ticdc 任务配置如下:
"info": {
"sink-uri": "mysql://root:xxxxxxxxxx@172.29.238.238:4920/?worker-count=32\u0026max-txn-row=5000",
"opts": {
"sort-engine": "memory" }
2.操作过程
在集群A 进行数据删除操作
MySQL [oom]> select count(*) from sbtest2;
+----------+
| count(*) |
+----------+
| 19882500 |
+----------+
MySQL [oom]> delete from sbtest2 limit 50000;
观察两个ticdc 以及下游tidb-server 的日志输出
从下面的日志可以看出,从ticdc 输出sink 信息到tidb-server 的日志输出,差了两分钟,请问是否符合预期 ????
[2021/07/29 17:08:58.961 +08:00] [INFO] [statistics.go:126] ["sink replication status"]
[name=mysql] [changefeed=oomoo] [capture=192.168.149.156:8302] [count=50000] [qps=83]
-----
[2021/07/29 17:10:25.329 +08:00] [INFO] [2pc.go:410] ["[BIG_TXN]"] [session=37]
["key sample"=7480000000000001605f698000000000000001038000000000414c27038000000000026707]
[size=2800000] [keys=100000] [puts=0] [dels=100000] [locks=0] [checks=0] [txnStartTS=426652385944010753]
观察ticdc 的监控延迟
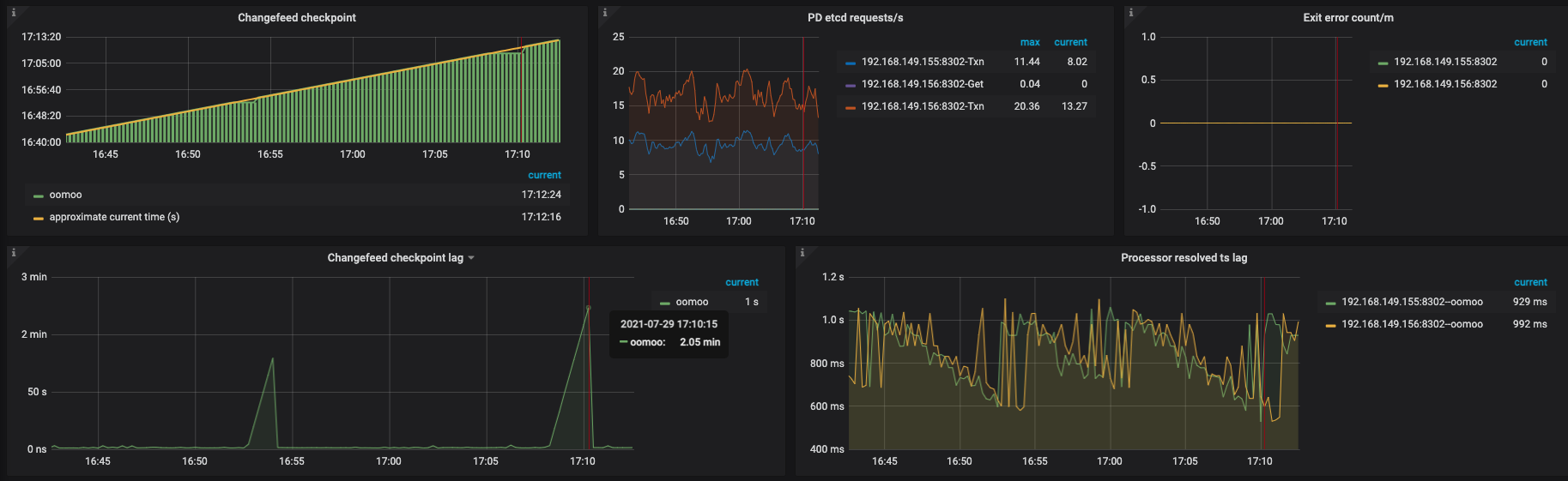
请问是否有方法优化这种延迟 ?
附件: ticdc 整体的监控信息
tidb-oooom-TiCDC_2021-07-29T09_15_14.558Z.json (1.2 MB)