新加tikv报错
!
1 个赞
2021-07-28T14:58:22.565+0800 DEBUG TaskFinish {“task”: “ClusterOperate: operation=RestartOperation, options={Roles:[prometheus] Nodes:[] Force:false SSHTimeout:0 OptTimeout:120 APITimeout:0 IgnoreConfigCheck:false RetainDataRoles:[] RetainDataNodes:[]}”}
2021-07-28T14:58:22.565+0800 INFO + [ Serial ] - UpdateTopology: cluster=tidb-federated
2021-07-28T14:58:22.565+0800 DEBUG TaskBegin {“task”: “UpdateTopology: cluster=tidb-federated”}
2021-07-28T14:58:33.582+0800 DEBUG TaskFinish {“task”: “UpdateTopology: cluster=tidb-federated”, “error”: “etcdserver: request timed out, possibly due to previous leader failure”}
2021-07-28T14:58:33.582+0800 INFO Execute command finished {“code”: 1, “error”: “etcdserver: request timed out, possibly due to previous leader failure”, “errorVerbose”: “etcdserver: request timed out, possibly due to previous leader failure\ngithub.com/pingcap/errors.AddStack\
\tgithub.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/errors.go:174\
github.com/pingcap/errors.Trace\
\tgithub.com/pingcap/errors@v0.11.5-0.20190809092503-95897b64e011/juju_adaptor.go:15\
github.com/pingcap/tiup/components/cluster/command.scaleOut\
\tgithub.com/pingcap/tiup@/components/cluster/command/scale_out.go:149\
github.com/pingcap/tiup/components/cluster/command.newScaleOutCmd.func1\
\tgithub.com/pingcap/tiup@/components/cluster/command/scale_out.go:61\
github.com/spf13/cobra.(*Command).execute\
\tgithub.com/spf13/cobra@v1.0.0/command.go:842\
github.com/spf13/cobra.(*Command).ExecuteC\
\tgithub.com/spf13/cobra@v1.0.0/command.go:950\
github.com/spf13/cobra.(*Command).Execute\
\tgithub.com/spf13/cobra@v1.0.0/command.go:887\
github.com/pingcap/tiup/components/cluster/command.Execute\
\tgithub.com/pingcap/tiup@/components/cluster/command/root.go:228\
main.main\
\tgithub.com/pingcap/tiup@/components/cluster/main.go:19\
runtime.main\
\truntime/proc.go:203\
runtime.goexit\
\truntime/asm_amd64.s:1357”}
1 个赞
在添加tikv节点时报如上错误
1 个赞
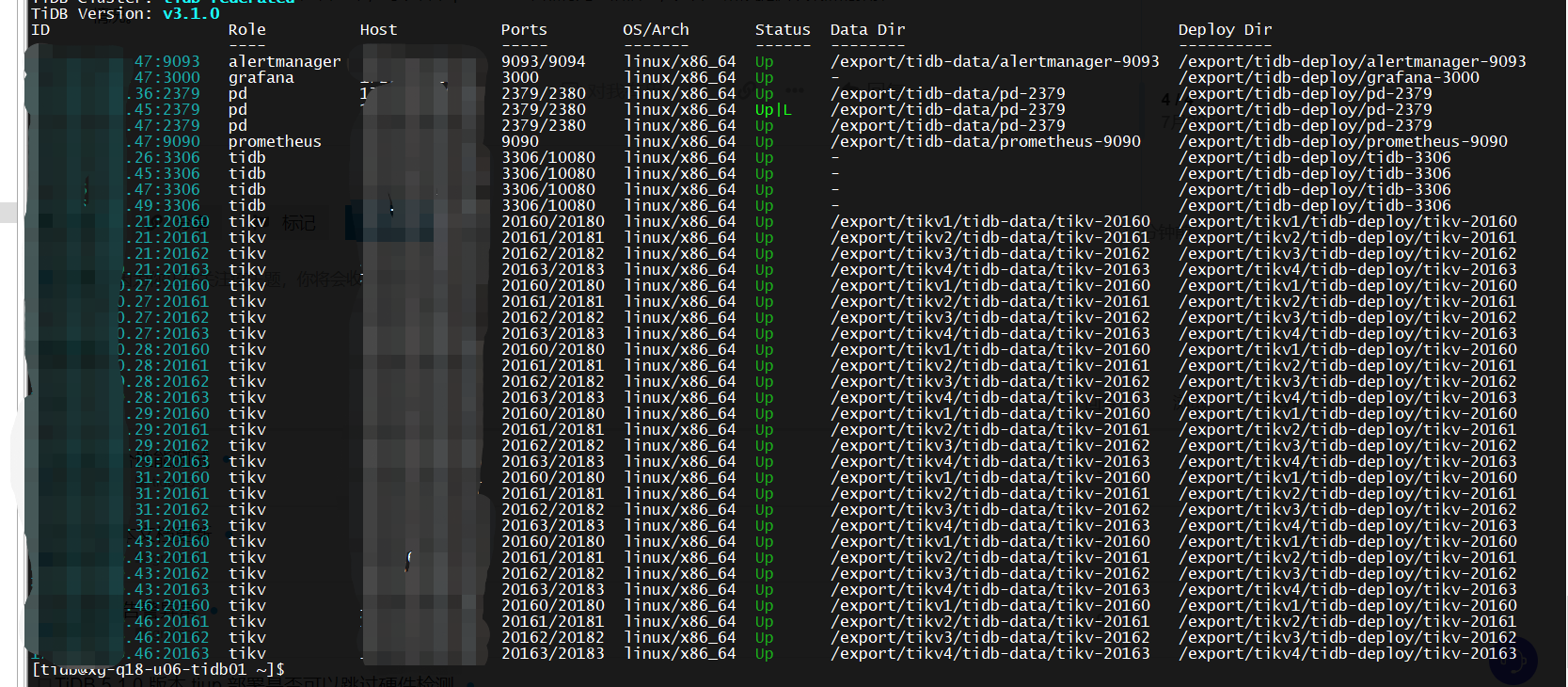
麻烦先检查下 pd 节点的状态是否正常,可以看下 pd leader 节点有无报错信息,另外也麻烦提供下集群的拓扑情况。
1 个赞
1 个赞
怎么检查?
1 个赞
从拓扑上看 45 这条是 pd leader ,麻烦检查下 pd.log 日志有无报错信息,并检查下 45 和新扩容的 tikv 节点之间的网络通信是否正常。
1 个赞
pd报错信息:
[2021/07/28 14:58:22.428 +08:00] [WARN] [stream.go:436] [“lost TCP streaming connection with remote peer”] [stream-reader-type=“stream Message”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c] [error=“unexpected EOF”]
[2021/07/28 14:58:22.428 +08:00] [ERROR] [client.go:171] [“region sync with leader meet error”] [error=“rpc error: code = Unavailable desc = transport is closing”]
[2021/07/28 14:58:22.428 +08:00] [WARN] [peer_status.go:68] [“peer became inactive (message send to peer failed)”] [peer-id=d82444f0597bcf6c] [error=“failed to read d82444f0597bcf6c on stream Message (unexpected EOF)”]
[2021/07/28 14:58:22.429 +08:00] [WARN] [grpclog.go:60] [“grpc: addrConn.createTransport failed to connect to {172.26.110.47:2379 0 }. Err :connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused”. Reconnecting…”]
[2021/07/28 14:58:22.428 +08:00] [WARN] [stream.go:436] [“lost TCP streaming connection with remote peer”] [stream-reader-type=“stream MsgApp v2”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c] [error=“unexpected EOF”]
[2021/07/28 14:58:22.444 +08:00] [WARN] [stream.go:224] [“lost TCP streaming connection with remote peer”] [stream-writer-type=“stream Message”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c]
[2021/07/28 14:58:23.429 +08:00] [WARN] [grpclog.go:60] [“grpc: addrConn.createTransport failed to connect to {172.26.110.47:2379 0 }. Err :connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused”. Reconnecting…”]
[2021/07/28 14:58:23.432 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:24.433 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:24.609 +08:00] [INFO] [raft.go:923] [“18df403eb0b3fee8 is starting a new election at term 6”]
[2021/07/28 14:58:24.609 +08:00] [INFO] [raft.go:729] [“18df403eb0b3fee8 became pre-candidate at term 6”]
[2021/07/28 14:58:24.609 +08:00] [INFO] [raft.go:824] [“18df403eb0b3fee8 received MsgPreVoteResp from 18df403eb0b3fee8 at term 6”]
[2021/07/28 14:58:24.609 +08:00] [INFO] [raft.go:811] [“18df403eb0b3fee8 [logterm: 6, index: 10920739] sent MsgPreVote request to c1d62ec49e409e47 at term 6”]
[2021/07/28 14:58:24.609 +08:00] [INFO] [raft.go:811] [“18df403eb0b3fee8 [logterm: 6, index: 10920739] sent MsgPreVote request to d82444f0597bcf6c at term 6”]
[2021/07/28 14:58:24.609 +08:00] [INFO] [node.go:331] [“raft.node: 18df403eb0b3fee8 lost leader d82444f0597bcf6c at term 6”]
[2021/07/28 14:58:24.610 +08:00] [INFO] [raft.go:824] [“18df403eb0b3fee8 received MsgPreVoteResp from c1d62ec49e409e47 at term 6”]
[2021/07/28 14:58:24.610 +08:00] [INFO] [raft.go:1302] [“18df403eb0b3fee8 has received 2 MsgPreVoteResp votes and 0 vote rejections”]
[2021/07/28 14:58:24.610 +08:00] [INFO] [raft.go:713] [“18df403eb0b3fee8 became candidate at term 7”]
[2021/07/28 14:58:24.610 +08:00] [INFO] [raft.go:824] [“18df403eb0b3fee8 received MsgVoteResp from 18df403eb0b3fee8 at term 7”]
[2021/07/28 14:58:24.610 +08:00] [INFO] [raft.go:811] [“18df403eb0b3fee8 [logterm: 6, index: 10920739] sent MsgVote request to c1d62ec49e409e47 at term 7”]
[2021/07/28 14:58:24.610 +08:00] [INFO] [raft.go:811] [“18df403eb0b3fee8 [logterm: 6, index: 10920739] sent MsgVote request to d82444f0597bcf6c at term 7”]
[2021/07/28 14:58:24.611 +08:00] [INFO] [raft.go:824] [“18df403eb0b3fee8 received MsgVoteResp from c1d62ec49e409e47 at term 7”]
[2021/07/28 14:58:24.611 +08:00] [INFO] [raft.go:1302] [“18df403eb0b3fee8 has received 2 MsgVoteResp votes and 0 vote rejections”]
[2021/07/28 14:58:24.611 +08:00] [INFO] [raft.go:765] [“18df403eb0b3fee8 became leader at term 7”]
[2021/07/28 14:58:24.611 +08:00] [INFO] [node.go:325] [“raft.node: 18df403eb0b3fee8 elected leader 18df403eb0b3fee8 at term 7”]
[2021/07/28 14:58:24.616 +08:00] [WARN] [cluster_util.go:315] [“failed to reach the peer URL”] [address=http://172.26.110.47:2380/version] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:24.616 +08:00] [WARN] [cluster_util.go:168] [“failed to get version”] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:24.899 +08:00] [WARN] [grpclog.go:60] [“grpc: addrConn.createTransport failed to connect to {172.26.110.47:2379 0 }. Err :connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused”. Reconnecting…”]
[2021/07/28 14:58:25.433 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:25.618 +08:00] [WARN] [stream.go:193] [“lost TCP streaming connection with remote peer”] [stream-writer-type=“stream MsgApp v2”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c]
[2021/07/28 14:58:26.435 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:27.104 +08:00] [WARN] [grpclog.go:60] [“grpc: addrConn.createTransport failed to connect to {172.26.110.47:2379 0 }. Err :connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused”. Reconnecting…”]
[2021/07/28 14:58:27.435 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:28.435 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:28.617 +08:00] [WARN] [cluster_util.go:315] [“failed to reach the peer URL”] [address=http://172.26.110.47:2380/version] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:28.617 +08:00] [WARN] [cluster_util.go:168] [“failed to get version”] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:29.269 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=4.655808038s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/store/gcworker/saved_safe_point” “] [response=] [error=“context canceled”]
[2021/07/28 14:58:29.269 +08:00] [INFO] [trace.go:145] [“trace[1723663758] range”] [detail=”{range_begin:/tidb/store/gcworker/saved_safe_point; range_end:; }”] [duration=4.65595721s] [start=2021/07/28 14:58:24.613 +08:00] [end=2021/07/28 14:58:29.269 +08:00] [steps="[“trace[1723663758] ‘agreement among raft nodes before linearized reading’ (duration: 4.655805938s)”]"]
[2021/07/28 14:58:29.444 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:29.639 +08:00] [WARN] [grpclog.go:60] [“grpc: addrConn.createTransport failed to connect to {172.26.110.47:2379 0 }. Err :connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused”. Reconnecting…”]
[2021/07/28 14:58:30.433 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=4.999787456s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/store/gcworker/saved_safe_point” “] [response=] [error=“context canceled”]
[2021/07/28 14:58:30.433 +08:00] [INFO] [trace.go:145] [“trace[1957738511] range”] [detail=”{range_begin:/tidb/store/gcworker/saved_safe_point; range_end:; }”] [duration=5.000022478s] [start=2021/07/28 14:58:25.433 +08:00] [end=2021/07/28 14:58:30.433 +08:00] [steps="[“trace[1957738511] ‘agreement among raft nodes before linearized reading’ (duration: 4.999778855s)”]"]
[2021/07/28 14:58:30.444 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:31.445 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:32.445 +08:00] [ERROR] [client.go:163] [“server failed to establish sync stream with leader”] [server=pd-172.26.110.45-2379] [leader=pd-172.26.110.47-2379] [error=“rpc error: code = Unavailable desc = all SubConns are in TransientFailure, latest connection error: connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused””]
[2021/07/28 14:58:32.618 +08:00] [WARN] [cluster_util.go:315] [“failed to reach the peer URL”] [address=http://172.26.110.47:2380/version] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:32.619 +08:00] [WARN] [cluster_util.go:168] [“failed to get version”] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:32.726 +08:00] [WARN] [grpclog.go:60] [“grpc: addrConn.createTransport failed to connect to {172.26.110.47:2379 0 }. Err :connection error: desc = “transport: Error while dialing dial tcp 172.26.110.47:2379: connect: connection refused”. Reconnecting…”]
[2021/07/28 14:58:32.920 +08:00] [INFO] [leader.go:384] [“leader is deleted”]
[2021/07/28 14:58:33.445 +08:00] [INFO] [server.go:1020] [“leader changed, try to campaign leader”]
[2021/07/28 14:58:33.445 +08:00] [INFO] [server.go:1036] [“start to campaign leader”] [campaign-leader-name=pd-172.26.110.45-2379]
[2021/07/28 14:58:33.490 +08:00] [INFO] [server.go:1053] [“campaign leader ok”] [campaign-leader-name=pd-172.26.110.45-2379]
[2021/07/28 14:58:33.636 +08:00] [INFO] [server.go:149] [“establish sync region stream”] [requested-server=pd-172.26.110.36-2379] [url=http://172.26.110.36:2379]
[2021/07/28 14:58:33.639 +08:00] [INFO] [server.go:167] [“requested server has already in sync with server”] [requested-server=pd-172.26.110.36-2379] [server=pd-172.26.110.45-2379] [last-index=51852859]
[2021/07/28 14:58:34.439 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=0]
[2021/07/28 14:58:34.640 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=1]
[2021/07/28 14:58:34.845 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=2]
[2021/07/28 14:58:35.046 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=3]
[2021/07/28 14:58:35.246 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=4]
[2021/07/28 14:58:35.297 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=4.999933306s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/store/gcworker/saved_safe_point” “] [response=] [error=“context deadline exceeded”]
[2021/07/28 14:58:35.297 +08:00] [INFO] [trace.go:145] [“trace[989537878] range”] [detail=”{range_begin:/tidb/store/gcworker/saved_safe_point; range_end:; }”] [duration=5.000030863s] [start=2021/07/28 14:58:30.297 +08:00] [end=2021/07/28 14:58:35.297 +08:00] [steps="[“trace[989537878] ‘agreement among raft nodes before linearized reading’ (duration: 4.999925534s)”]"]
[2021/07/28 14:58:35.434 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=0]
[2021/07/28 14:58:35.438 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=0]
[2021/07/28 14:58:35.445 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=0]
[2021/07/28 14:58:35.446 +08:00] [ERROR] [tso.go:275] [“we haven’t synced timestamp ok, wait and retry”] [retry-count=5]
[2021/07/28 14:58:35.614 +08:00] [WARN] [v3_server.go:750] [“timed out waiting for read index response (local node might have slow network)”] [timeout=11s]
[2021/07/28 14:58:35.614 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=2.123064719s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/pd/6853966776932689968/timestamp” “] [response=“range_response_count:1 size:68”] []
[2021/07/28 14:58:35.614 +08:00] [INFO] [trace.go:145] [“trace[1321398673] range”] [detail=”{range_begin:/pd/6853966776932689968/timestamp; range_end:; response_count:1; response_revision:10911535; }”] [duration=2.123131482s] [start=2021/07/28 14:58:33.491 +08:00] [end=2021/07/28 14:58:35.614 +08:00] [steps="[“trace[1321398673] ‘agreement among raft nodes before linearized reading’ (duration: 2.122962497s)”]"]
[2021/07/28 14:58:35.614 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=3.620912558s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/store/gcworker/saved_safe_point” “] [response=“range_response_count:1 size:82”] []
[2021/07/28 14:58:35.614 +08:00] [INFO] [trace.go:145] [“trace[1920351476] range”] [detail=”{range_begin:/tidb/store/gcworker/saved_safe_point; range_end:; response_count:1; response_revision:10911535; }”] [duration=3.621036565s] [start=2021/07/28 14:58:31.993 +08:00] [end=2021/07/28 14:58:35.614 +08:00] [steps="[“trace[1920351476] ‘agreement among raft nodes before linearized reading’ (duration: 3.620804158s)”]"]
[2021/07/28 14:58:35.614 +08:00] [WARN] [etcdutil.go:111] [“kv gets too slow”] [request-key=/pd/6853966776932689968/timestamp] [cost=2.123442054s] []
[2021/07/28 14:58:35.614 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=2.131735982s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/stats/owner/” range_end:”/tidb/stats/owner0" limit:1 sort_order:DESCEND sort_target:CREATE max_create_revision:732176 “] [response=“range_response_count:1 size:103”] []
[2021/07/28 14:58:35.614 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=2.13266193s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/stats/owner/” range_end:”/tidb/stats/owner0” limit:1 sort_order:DESCEND sort_target:CREATE max_create_revision:10850912 “] [response=“range_response_count:1 size:109”] []
[2021/07/28 14:58:35.614 +08:00] [INFO] [trace.go:145] [“trace[531846024] range”] [detail=”{range_begin:/tidb/stats/owner/; range_end:/tidb/stats/owner0; response_count:1; response_revision:10911535; }"] [duration=2.133001104s] [start=2021/07/28 14:58:33.481 +08:00] [end=2021/07/28 14:58:35.614 +08:00] [steps="[“trace[531846024] ‘agreement among raft nodes before linearized reading’ (duration: 2.132540021s)”]"]
[2021/07/28 14:58:35.614 +08:00] [WARN] [util.go:144] [“apply request took too long”] [took=2.131550334s] [expected-duration=100ms] [prefix=“read-only range “] [request=“key:”/tidb/stats/owner/” range_end:”/tidb/stats/owner0" limit:1 sort_order:DESCEND sort_target:CREATE max_create_revision:10676699 “] [response=“range_response_count:1 size:107”] []
[2021/07/28 14:58:35.615 +08:00] [INFO] [trace.go:145] [“trace[1582705153] range”] [detail=”{range_begin:/tidb/stats/owner/; range_end:/tidb/stats/owner0; response_count:1; response_revision:10911535; }"] [duration=2.131948864s] [start=2021/07/28 14:58:33.483 +08:00] [end=2021/07/28 14:58:35.615 +08:00] [steps="[“trace[1582705153] ‘agreement among raft nodes before linearized reading’ (duration: 2.13143031s)”]"]
[2021/07/28 14:58:35.614 +08:00] [INFO] [trace.go:145] [“trace[271543315] range”] [detail="{range_begin:/tidb/stats/owner/; range_end:/tidb/stats/owner0; response_count:1; response_revision:10911535; }"] [duration=2.132026094s] [start=2021/07/28 14:58:33.482 +08:00] [end=2021/07/28 14:58:35.614 +08:00] [steps="[“trace[271543315] ‘agreement among raft nodes before linearized reading’ (duration: 2.131615611s)”]"]
[2021/07/28 14:58:35.616 +08:00] [INFO] [tso.go:137] [“sync and save timestamp”] [last=2021/07/28 14:58:23.778 +08:00] [save=2021/07/28 14:58:38.614 +08:00] [next=2021/07/28 14:58:35.614 +08:00]
[2021/07/28 14:58:35.616 +08:00] [INFO] [server.go:1272] [“server enable region storage”]
[2021/07/28 14:58:35.635 +08:00] [WARN] [grpc_service.go:99] [“get timestamp too slow”] [cost=200.148789ms]
[2021/07/28 14:58:35.638 +08:00] [WARN] [grpc_service.go:99] [“get timestamp too slow”] [cost=200.142527ms]
[2021/07/28 14:58:35.645 +08:00] [WARN] [grpc_service.go:99] [“get timestamp too slow”] [cost=200.111084ms]
[2021/07/28 14:58:35.647 +08:00] [WARN] [grpc_service.go:99] [“get timestamp too slow”] [cost=1.207299065s]
[2021/07/28 14:58:35.655 +08:00] [INFO] [cluster.go:244] [“load stores”] [count=28] [cost=36.924966ms]
[2021/07/28 14:58:35.655 +08:00] [INFO] [cluster.go:255] [“load regions”] [count=551518] [cost=1.141µs]
[2021/07/28 14:58:35.658 +08:00] [INFO] [util.go:85] [“load cluster version”] [cluster-version=3.1.0]
[2021/07/28 14:58:35.658 +08:00] [INFO] [coordinator.go:166] [“coordinator starts to collect cluster information”]
[2021/07/28 14:58:35.658 +08:00] [INFO] [server.go:1079] [“PD cluster leader is ready to serve”] [leader-name=pd-172.26.110.45-2379]
[2021/07/28 14:58:36.620 +08:00] [WARN] [cluster_util.go:315] [“failed to reach the peer URL”] [address=http://172.26.110.47:2380/version] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:36.620 +08:00] [WARN] [cluster_util.go:168] [“failed to get version”] [remote-member-id=d82444f0597bcf6c] [error=“Get http://172.26.110.47:2380/version: dial tcp 172.26.110.47:2380: connect: connection refused”]
[2021/07/28 14:58:38.372 +08:00] [INFO] [stream.go:250] [“set message encoder”] [from=18df403eb0b3fee8] [to=18df403eb0b3fee8] [stream-type=“stream Message”]
[2021/07/28 14:58:38.372 +08:00] [INFO] [peer_status.go:51] [“peer became active”] [peer-id=d82444f0597bcf6c]
[2021/07/28 14:58:38.372 +08:00] [WARN] [stream.go:277] [“established TCP streaming connection with remote peer”] [stream-writer-type=“stream Message”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c]
[2021/07/28 14:58:38.373 +08:00] [INFO] [stream.go:250] [“set message encoder”] [from=18df403eb0b3fee8] [to=18df403eb0b3fee8] [stream-type=“stream MsgApp v2”]
[2021/07/28 14:58:38.373 +08:00] [WARN] [stream.go:277] [“established TCP streaming connection with remote peer”] [stream-writer-type=“stream MsgApp v2”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c]
[2021/07/28 14:58:38.383 +08:00] [INFO] [stream.go:425] [“established TCP streaming connection with remote peer”] [stream-reader-type=“stream MsgApp v2”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c]
[2021/07/28 14:58:38.383 +08:00] [INFO] [stream.go:425] [“established TCP streaming connection with remote peer”] [stream-reader-type=“stream Message”] [local-member-id=18df403eb0b3fee8] [remote-peer-id=d82444f0597bcf6c]
[2021/07/28 14:59:00.170 +08:00] [INFO] [cluster.go:442] [“region ConfVer changed”] [region-id=92931327] [detail=“Add peer:{id:228321795 store_id:228321669 is_learner:true }”] [old-confver=225569] [new-confver=225570]
[2021/07/28 14:59:04.175 +08:00] [INFO] [server.go:149] [“establish sync region stream”] [requested-server=pd-172.26.110.47-2379] [url=http://172.26.110.47:2379]
[2021/07/28 14:59:04.176 +08:00] [INFO] [server.go:201] [“sync the history regions with server”] [server=pd-172.26.110.47-2379] [from-index=51852800] [last-index=51852860] [records-length=60]
[2021/07/28 14:59:40.870 +08:00] [WARN] [grpc_service.go:99] [“get timestamp too slow”] [cost=5.235137ms]
[2021/07/28 14:59:42.236 +08:00] [INFO] [id.go:110] [“idAllocator allocates a new id”] [alloc-id=228323000]
[2021/07/28 14:59:42.236 +08:00] [INFO] [cluster_worker.go:130] [“alloc ids for region split”] [region-id=228322001] [peer-ids="[228322002,228322003,228322004]"]
[2021/07/28 14:59:42.239 +08:00] [INFO] [cluster_worker.go:217] [“region batch split, generate new regions”] [region-id=224169077] [origin=“id:228322001 start_key:“748000000000000BFF955F698000000000FF0000070136323838FF38383835FF363030FF3030303132FF3132FF350000000000FA03FF800000022DBAB097FF0000000000000000F7” end_key:“748000000000000BFF955F698000000000FF0000070136323838FF38383835FF363030FF3030303132FF3631FF330000000000FA03FF8000000252B88E02FF0000000000000000F7” region_epoch:<conf_ver:1199 version:1843 > peers:<id:228322002 store_id:1 > peers:<id:228322003 store_id:17 > peers:<id:228322004 store_id:183788288 >”] [total=1]
[2021/07/28 14:59:46.699 +08:00] [INFO] [cluster.go:454] [“leader changed”] [region-id=280047] [from=4] [to=17]
[2021/07/28 14:59:51.726 +08:00] [INFO] [cluster.go:454] [“leader changed”] [region-id=98166676] [from=183788288] [to=22]
[2021/07/28 14:59:53.678 +08:00] [INFO] [cluster.go:454] [“leader changed”] [region-id=588135] [from=183788287] [to=15]
[2021/07/28 15:00:23.658 +08:00] [INFO] [coordinator.go:169] [“coordinator has finished cluster information preparation”]
[2021/07/28 15:00:23.658 +08:00] [INFO] [coordinator.go:179] [“coordinator starts to run schedulers”]
[2021/07/28 15:00:23.661 +08:00] [INFO] [coordinator.go:221] [“create scheduler with independent configuration”] [scheduler-name=balance-hot-region-scheduler]
[2021/07/28 15:00:23.662 +08:00] [INFO] [coordinator.go:221] [“create scheduler with independent configuration”] [scheduler-name=balance-leader-scheduler]
[2021/07/28 15:00:23.663 +08:00] [INFO] [coordinator.go:221] [“create scheduler with independent configuration”] [scheduler-name=balance-region-scheduler]
[2021/07/28 15:00:23.664 +08:00] [INFO] [coordinator.go:221] [“create scheduler with independent configuration”] [scheduler-name=label-scheduler]
[2021/07/28 15:00:23.665 +08:00] [INFO] [coordinator.go:243] [“create scheduler”] [scheduler-name=balance-region-scheduler]
[2021/07/28 15:00:23.666 +08:00] [INFO] [coordinator.go:243] [“create scheduler”] [scheduler-name=balance-leader-scheduler]
[2021/07/28 15:00:23.666 +08:00] [INFO] [coordinator.go:243] [“create scheduler”] [scheduler-name=balance-hot-region-scheduler]
[2021/07/28 15:00:23.667 +08:00] [INFO] [coordinator.go:243] [“create scheduler”] [scheduler-name=label-scheduler]
[2021/07/28 15:00:23.668 +08:00] [INFO] [coordinator.go:149] [“coordinator begins to actively drive push operator”]
[2021/07/28 15:00:23.668 +08:00] [INFO] [coordinator.go:100] [“coordinator starts patrol regions”]
网络通讯没问题,ssh没有问题。我已把报错贴到上边了
1 个赞
从这一段日志中看到在 14:58 左右 pd leader 发生了切换,pd leader 从 47 节点切换到 45 节点,而在这期间进行了 tikv 扩容,最终提示请求超时了,麻烦尝试重新扩容下 tikv 节点,看下是否还有问题。
1 个赞
扩容节点已经显示正常并开始同步,就是报了一个错误,这个错误是否影响tidb数据完整性
1 个赞
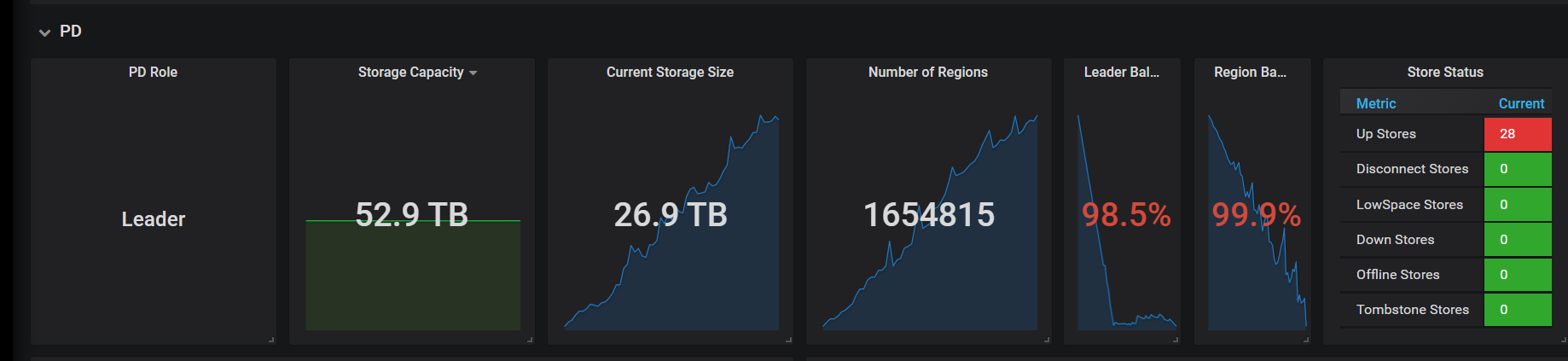
1.这个应该不会,上面的报错提示的是在扩容节点更新集群拓扑信息时和 pd leader 通信超时,这个跟 pd leader 发生了切换有关系,现在新 tikv 节点已经开始正常同步数据了,说明 pd leader 的调度任务是正常的,而且本身集群的数据都是在 tikv 中,pd leader 只是起到调度作用;
2.刚扩容节点,Leader Balance Ratio 和 Region Balance Ratio 指标高是正常现象,指标本身反应的是 Leader/Region 数量最多和最少节点相差的百分比,你可以再观察一段时间,随着 region 均衡这两个指标的值应该会逐步下降的
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。