脚本小王子
(脚本小王子)
1
为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
测试环境
【概述】场景+问题概述
192.168.68.131是tikv节点,执行以下命令缩容
tiup cluster scale-in tidb-test -N 192.168.68.131:20160
后一直显示“Pending Offline”,在执行该命令前整个集库的所有用户的库都已删除,等了一段时间还是这个状态后再执行
tiup cluster scale-in tidb-test -N 192.168.68.131:20160 --force
后,tiup cluster display tidb-test 终于看不到192.168.68.131这个节点了,然后使用lightning导入数据:
tidb-lightning -config tidb-lightning.toml --check-requirements=false
报以下错误:
tidb lightning encountered error: build local backend failed: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 192.168.68.131:20160: i/o timeout"
执行
tiup ctl:v5.1.0 pd -u http://192.168.68.128:2379 store
发现 192.168.68.131这个节点还在,id为114001,于是执行
tiup ctl:v5.1.0 pd -u http://192.168.68.128:2379 store delete 114001
提示Success!,但再执行上面命令查看时114001这个id还在,好像完全没生效
【背景】做过哪些操作
【现象】业务和数据库现象
【业务影响】
【TiDB 版本】
5.1.0
【附件】
-
TiUP Cluster Display 信息
-
TiUP Cluster Edit Config 信息
-
TiDB- Overview 监控
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。
1 个赞
gaozhenjiao
(Hacker O Kes Ks Fz)
2
对节点缩容后,不论是 --force 还是非 force delete,会有 offline → tombstone 状态的变化,变为 tombstone 后,才表示节点正式下线成功:
在节点下线过程中,并且状态为 offline,但是使用 tidb-lightning 导入数据出现下面的报错,辛苦提供下相应的信息:
- pd-ctl store 收集下所有 store 的信息
- tidb-lightning 的完整的配置文件以及 log 文件
脚本小王子
(脚本小王子)
3
store.json (2.8 KB) tidb-lightning.toml (1.5 KB) tidb-lightning.log (127.8 KB)
感谢回复!
相关文件如上,谢谢
集群中仅有 3 个 store,并且对 192.168.68.131:20160 缩容了,并且状态为 offline,其他两个 store 状态为 up。在这个情况下,192.168.68.131:20160 节点无法变为 tombstone 状态 ,即无法下线 ~
看起来是新建集群,建议你那里先新扩容一个 store_new,使 192.168.68.131:20160 可以正常下线,变为 tombstone 状态 ~
然后再使用 tidb-lightning local backend 模式(最新扩容的 store_new 保持在集群中)导入数据观察下情况 ~
脚本小王子
(脚本小王子)
5
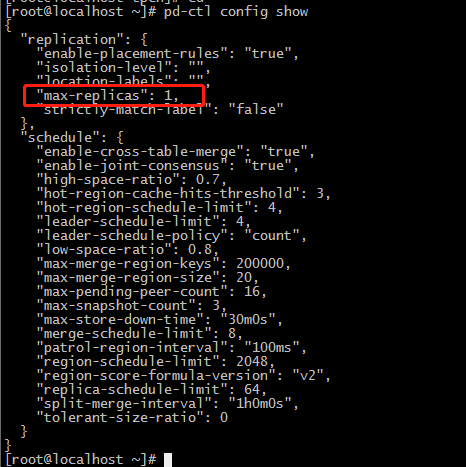
您好,我已改为只有一个副本,这也要求必须要有三个TiKV节点吗?
确认下,当前集群始终是只有一个副本吗,还是今天调整过 ?
脚本小王子
(脚本小王子)
7
今天把所有数据都删除后过一段时间再调整为一个副本的。
目前已多增加了一个TiKV节点(目前总共三个),但原来那个在store里还是显示有
脚本小王子
(脚本小王子)
8
抱歉,刚扩容那个新节点忘了关防火墙,关掉防火墙后,旧的那个节点就彻底删除了
嗯嗯,梳理下操作步骤:
1、当前 region 副本数量为 1
2、tiup scale-in 192.168.68.131:20160 状态看到变为 offline
3、再次 tiup scale-in 192.168.68.131:20160 force,状态仍为 offline,并且目标 store 进程以及数据目录均被删除
4、tidb-lightning local backend 导入数据出现下述报错。该报错的原因是,PD 中仍然记录了 192.168.68.131:20160 信息,但是因为 scale-in force 进程不存在,进而访问出现报错。
5、新扩容一个 store 后,192.168.68.131:20160 正常下线
因为 region 副本数为 1,并且有过 scale-in force 操作,所以可能会出现某些 region 数据被强制清除,导致数据不完整,建议使用 check miss-peer 先检查下:
https://docs.pingcap.com/zh/tidb/v5.0/pd-control#region-check-miss-peer--extra-peer--down-peer--pending-peer--offline-peer--empty-region--hist-size--hist-keys
如果检查结果显示有问题,并且是测试环境,没有业务数据,建议销毁集群,重新搭建环境后,再导入数据
一副本情况下,强烈不建议 --force scale-in store,3 或 5 副本的情况下,建议根据实际情况选用
脚本小王子
(脚本小王子)
10
谢谢
第2步为“Pending Offline”状态,执行第3步后,“tiup cluster display tidb-test”已看不到192.168.68.131:20160的节点,但pd-ctl store时仍能看到该节点,其状态为offline
嗯,这个现象是符合预期的:
第二步 scale-in 后,通过 tiup display 看到 pending offline
第三步 scale-in force 后,会删除 tiup meta.yaml 文件中的 192.168.68.131:20160 store 信息,故 tiup display 是看不到这个 store ,但是 pd-ctl 能看到 ~
一般情况下,不建议使用 scale-in --force
system
(system)
关闭
13
此话题已在最后回复的 1 分钟后被自动关闭。不再允许新回复。
