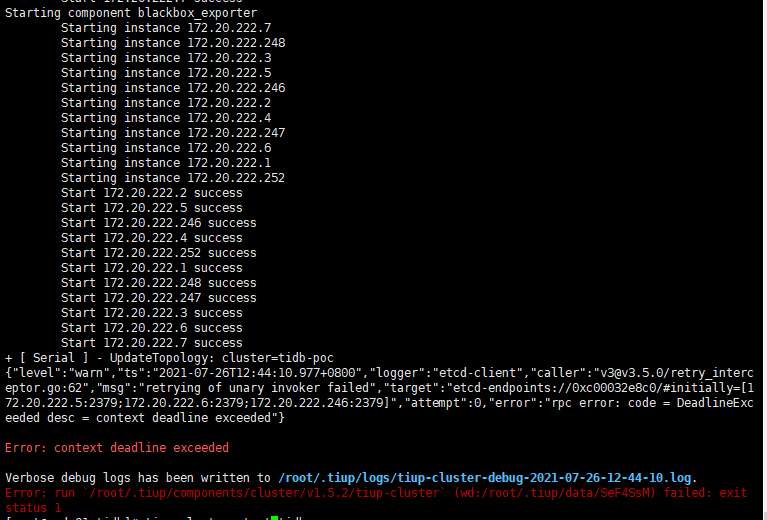
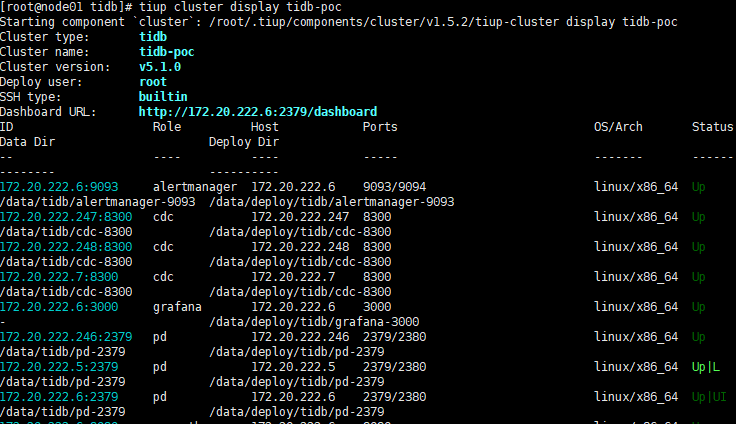
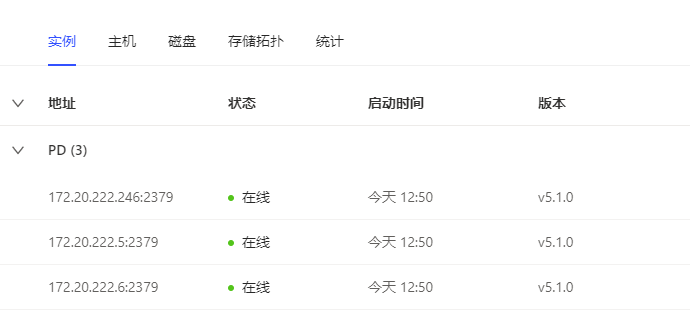
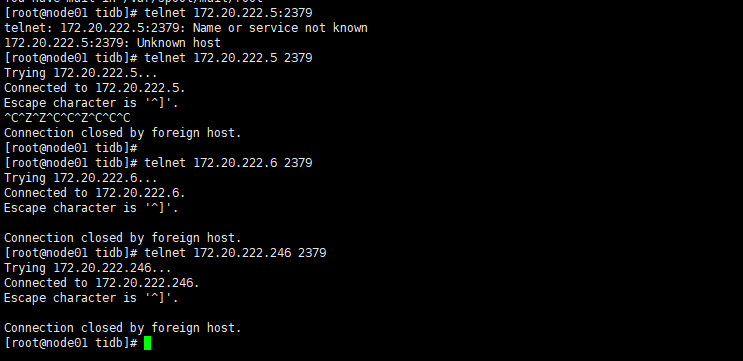
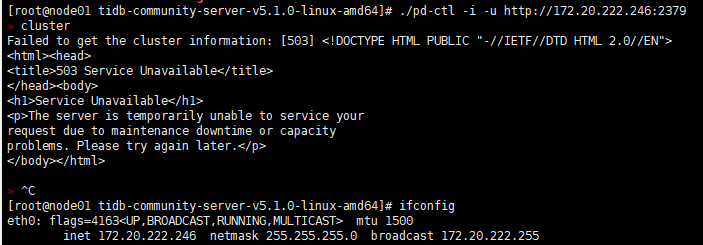
日志如下:
2021-07-26T10:39:51.207+0800 DEBUG TaskFinish {“task”: “StartCluster”}
2021-07-26T10:39:51.207+0800 INFO + [ Serial ] - UpdateTopology: cluster=tidb-poc
2021-07-26T10:39:51.207+0800 DEBUG TaskBegin {“task”: “UpdateTopology: cluster=tidb-poc”}
2021-07-26T10:40:01.209+0800 DEBUG TaskFinish {“task”: “UpdateTopology: cluster=tidb-poc”, “error”: “context deadline exceeded”}
2021-07-26T10:40:01.209+0800 INFO Execute command finished {“code”: 1, “error”: “context deadline exceeded”, “errorVerbose”: “context deadline exceeded
github.com/pingcap/errors.AddStack
\tgithub.com/pingcap/errors@v0.11.4/errors.go:174
github.com/pingcap/errors.Trace
\tgithub.com/pingcap/errors@v0.11.4/juju_adaptor.go:15
github.com/pingcap/tiup/pkg/cluster/manager.(*Manager).StartCluster
\tgithub.com/pingcap/tiup/pkg/cluster/manager/basic.go:114
github.com/pingcap/tiup/components/cluster/command.newStartCmd.func1
\tgithub.com/pingcap/tiup/components/cluster/command/start.go:39
github.com/spf13/cobra.(*Command).execute
\tgithub.com/spf13/cobra@v1.1.3/command.go:852
github.com/spf13/cobra.(*Command).ExecuteC
\tgithub.com/spf13/cobra@v1.1.3/command.go:960
github.com/spf13/cobra.(*Command).Execute
\tgithub.com/spf13/cobra@v1.1.3/command.go:897
github.com/pingcap/tiup/components/cluster/command.Execute
\tgithub.com/pingcap/tiup/components/cluster/command/root.go:264
main.main
\tgithub.com/pingcap/tiup/components/cluster/main.go:23
runtime.main
\truntime/proc.go:225
runtime.goexit
\truntime/asm_amd64.s:1371”}
tiflash 也没起来