为提高效率,请提供以下信息,问题描述清晰能够更快得到解决:
【 TiDB 使用环境】
Ti server 32GX3 16v核
Ti pd 32Gx3 16v核
Ti kv 32GX3 16核
【概述】 场景 + 问题概述
24小时内要导入20亿数据,字段53个,一个string主键,没有autoincrement。
insert跟update比例各半。QPS上不去。
存在大量 spilling in-memory map of 5.4 GB to disk (1 time so far)。spark的storage界面显示磁盘使用超过76G
【背景】 做过哪些操作
tikv tiserver 做了最大内存限制,其他的配置没有改。
【现象】 业务和数据库现象
tispark 的demo跟jdbc比,tispark只能有7k的qps。jdbc方式能到9k的qps。
表目前15亿,4500个region。
我能不能事先切好数据,再用tispark
【问题】 当前遇到的问题
写了20小时,spark的界面显示 mapping 的步骤跑了4遍,超过8小时 和 count超过3小时。
问题1:
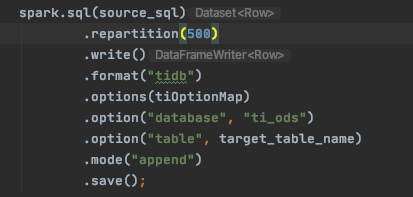
我能预先切数据到500个分区,然后每个分区起一个tispark任务来跑。并发写能行吗?
问题2:
tispark有没有commit机制,我跑了20个小时,没有查到数据写进去。
500w的数据21分钟能写跑成功。
1000w的数据21分钟能写跑成功。
【业务影响】
qps上不去。
【TiDB 版本】
4.0.x
【应用软件及版本】
spark 2.4.1集群,excutor 200个、32G
【附件】 相关日志及配置信息
- TiUP Cluster Display 信息
- TiUP CLuster Edit config 信息
监控(https://metricstool.pingcap.com/)
- TiDB-Overview Grafana监控
- TiDB Grafana 监控
- TiKV Grafana 监控
- PD Grafana 监控
- 对应模块日志(包含问题前后 1 小时日志)
若提问为性能优化、故障排查类问题,请下载脚本运行。终端输出的打印结果,请务必全选并复制粘贴上传。